


As Windows Functions são trabalhadas com um conjunto de linhas definidas por uma cláusula OVER, que permite trabalhar com totais, agrupamentos, ordenações, cálculos complexos dentre outros. Assim, conseguimos melhorar a performance com ordenações avançadas, além de limitarmos o número de linhas que serão retornadas em um subconjunto de dados associados a uma determinada tabela. As funções de agregação que são definidas pelo usuário também podem atuar como Windows Functions quando estas possuem uma chamada com a palavra-chave OVER.
A seguir veremos com mais detalhes as Windows Functions definidas no PostgreSQL, que hoje são um total de 11: cume_dist(), row_number(), rank(), dense_rank(), present_rank(), first_value(), last_value(), nth_value(), ntile(), lag() e a lead().
Esta é utilizada com o intuito de obtermos a classificação da linha atual. Para que este resultado seja obtido é realizado um cálculo no qual ocorre a divisão do número de linhas anteriores a linha atual pelo total de linhas encontradas. Essa razão é apresentada na fórmula a seguir, onde o tipo de retorno é o double precision:
Linha atual = (Número de linhas anteriores a linha atual)/(número total de linhas)Na Listagem 1 temos um exemplo simples da criação de uma nova tabela, a qual chamaremos de funcionarios_windows_function. O nome do banco de dados fica a critério, mas no nosso caso utilizamos TesteDevmedia.
Listagem 1. Criação da tabela funcionarios_windows_function.
CREATE TABLE funcionarios_windows_function
(
codigo_func integer NOT NULL,
nome_func character varying(100) NOT NULL,
profissao character varying(100) NOT NULL,
nome_departamento character varying(100) NOT NULL,
departamento_cod integer NOT NULL,
salario real,
CONSTRAINT funcionarios_windows_function_pkey PRIMARY KEY (codigo_func)
)
WITH (
OIDS=FALSE
);
ALTER TABLE funcionarios
OWNER TO postgres;Com a nossa tabela de testes criada, inserimos alguns dados de teste, como vemos na Listagem 2.
Listagem 2. Inserindo dados na tabela funcionarios_windows_function.
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (1, 'Edson Dionisio', 'Desenvolvedor Web', 'Desenvolvimento web', 10, 2000.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (2, 'Marília Késsia', 'Scrum Master', 'Desenvolvimento', 10, 6000.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (3, 'Caroline França', 'Desenvolvedor Android', 'Mobile', 30, 2500.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (4, 'Gustavo França', 'Desenvolvedor IOS', 'Mobile', 30, 2800.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (5, 'Renato silva', 'Desenvolvedor de Sistemas', 'Desenvolvimento de Sistemas', 10, 2000.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (6, 'João dos testes', 'Analista de Testes', 'Testes', 16, 2000.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (7, 'Maria das dores', 'Análista de Software', 'Engenharia de software', 12, 3000.00);
INSERT INTO FUNCIONARIOS_WINDOWS_FUNCTION (codigo_func, nome_func, profissao, nome_departamento, departamento_cod, SALARIO) VALUES (8, 'Rodrigo Sampaio', 'Desenvolvedor Windows Phone', 'Mobile', 30, 2600.00);Com a inserção dos registros na tabela de testes utilizaremos o comando SELECT para ver se as informações foram inseridas corretamente:
SELECT * FROM funcionarios_windows_functionApós isso, utilizaremos a mesma consulta, só que dessa vez adicionando a função cume_dist(), para ver o resultado da operação, conforme a seguinte instrução:
select *, cume_dist() OVER (ORDER BY departamento_cod) from FUNCIONARIOS_WINDOWS_FUNCTION;Ao utilizarmos a cláusula OVER para o código do departamento, temos que a função cume_dist() irá atribuir o mesmo valor para os departamentos que tenham o mesmo código, conforme vemos na Figura 1.
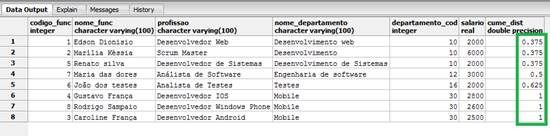
Figura 1. Resultado da utilização da função cume_dist.
Repare que temos a representação visual de um ranking sendo apresentado em ordem crescente, com base no código do departamento.
Essa função é utilizada para obter o número da linha atual dentro de sua partição, sendo este iniciado com o valor um. Na Listagem 4 temos um exemplo do seu uso.
Listagem 4. Utilizando a função row_number().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
row_number()
OVER (PARTITION BY departamento_cod)
FROM funcionarios_windows_function;Como resultado da consulta temos que cada um dos registros apresenta o número de fileiras com base no código dos departamentos, mostrando dessa forma a partição entre eles. Podemos ver o resultado da consulta na Figura 2.
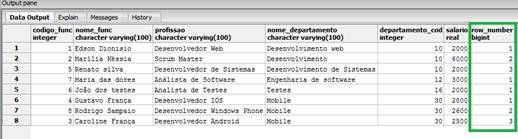
Figura 2. Consulta com a função row_number().
A quantidade de partições é apresentada com base na quantidade de registros com o mesmo código do departamento, de forma que os departamentos Mobile e de desenvolvimento possuem três registros sendo apresentados na partição, enquanto que os demais apresentam apenas uma partição.
A função rank() é utilizada basicamente para obtermos a classificação da linha atual onde, em caso de haver empate, o resultado será repetido entre as linhas com mesmo código, como mostra a Listagem 5.
Listagem 5. Utilizando a função rank().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
rank() OVER (
PARTITION BY departamento_cod ORDER BY nome_departamento)
FROM funcionarios_windows_function;Como o resultado da consulta anterior temos os departamentos classificados de acordo com o nome, estando estes separados em partições, como podemos ver na Figura 3.
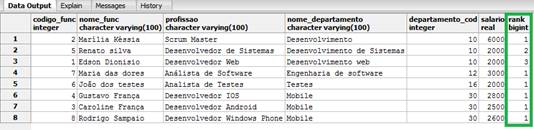
Figura 3. Utilizando a função rank().
Agora vamos considerar o seguinte caso: ao invés de utilizarmos a função para classificarmos os registros com base no código do departamento, vamos fazer a consulta baseada no nome do departamento, como mostra a Listagem 6.
Listagem 6. Consulta com base no nome do departamento.
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
rank() OVER (ORDER BY nome_departamento)
FROM funcionarios_windows_function;A nossa consulta muda o resultado, assim a classificação será com base no nome do departamento, atribuindo o mesmo valor classificatório para os itens repetidos, como podemos ver na Figura 4. Percebam também que obstruímos a pesquisa com o PARTITION BY.
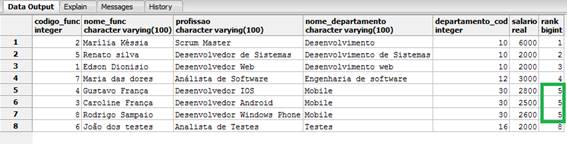
Figura 4. Utilizando a função rank() ordenando pelo nome do departamento.
A função dense_rank() também é utilizada para a obtenção da classificação atual dos registros, onde as linhas que apresentam valores iguais para os critérios de classificação recebem o mesmo valor, apresentando uma numeração contínua. Esta função difere da função rank() em apenas um aspecto: em caso de empate entre duas ou mais linhas, não havendo nenhuma lacuna presente na sequência dos valores classificados. Para demonstrarmos esse exemplo, acompanhe a Listagem 7.
Listagem 7. Utilização da função dense_rank().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
dense_rank()
OVER (ORDER BY departamento_cod)
FROM funcionarios_windows_function;Veja que temos apenas quatro departamentos sendo apresentados, então teremos a classificação máxima com o valor 4, como podemos ver na distribuição apresentada na Figura 5.
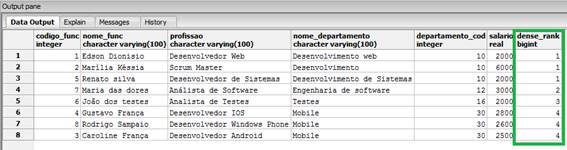
Figura 5. Distribuição classificatória com o dense_rank().
Em caso de utilizarmos a coluna “nome_departamento” na cláusula OVER, como fizemos anteriormente na Listagem 6, teremos um resultado diferente por conta das diferentes profissões cadastradas, como podemos ver na Listagem 8.
Listagem 8. Utilização da coluna “nome_departamento”.
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
dense_rank()
OVER (ORDER BY nome_departamento)
FROM funcionarios_windows_function;Como resultado desta nova consulta obtivemos o rank gerado até a sexta posição, pois temos seis departamentos distintos sendo apresentados, como mostra a Figura 6.
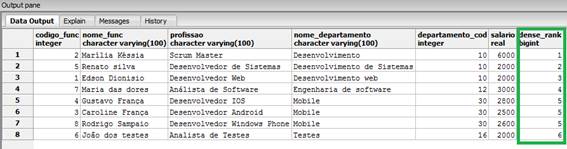
Figura 6. Classificação com base no nome_departamento.
Quando precisamos obter uma classificação relativa das classificações, podemos utilizar a função percent_rank(), que é utilizada para obtermos a classificação relativa da linha atual. Para que tenhamos a posição relativa da linha atual, realizamos o cálculo com base na seguinte fórmula:
Posição relativa da linha atual = (rank - 1) / (número total de linhas - 1)Vejamos agora com base na Listagem 9, um exemplo simples de sua utilização para uma melhor compreensão.
Listagem 9. Utilizando a função percent_rank().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
percent_rank()
OVER (PARTITION BY departamento_cod ORDER BY profissao)
FROM funcionarios_windows_function;Aqui continuamos utilizando a cláusula PARTITION BY, com relação ao código do departamento, dessa forma teremos que a função percent_rank() será com base no mesmo código, o que podemos ver na Figura 7.
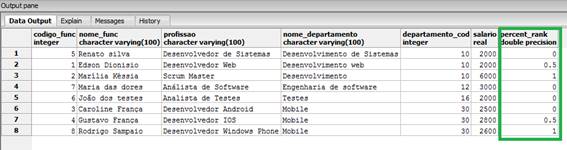
Figura 7. Utilização da função percent_rank().
Percebam que neste caso, para os departamentos com o mesmo código, obtivemos os valores de 0, 0.5 e 1. Enquanto que os demais registros obtiveram o valor 0.
Esta função é utilizada para a obtenção do valor presente na primeira linha da tabela. Para isso passamos o nome da coluna requerida como argumento de entrada, como mostra o exemplo da Listagem 10.
Listagem 10. Utilizando a função first_value().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
first_value(departamento_cod) OVER (ORDER BY departamento_cod)
FROM funcionarios_windows_function WHERE departamento_cod > 12;Com base na Listagem 10, temos a consulta na tabela, onde buscamos os registros que tenham o código de departamento maior que 12, após isso aplicamos a cláusula Order By pelo código do departamento. Dessa forma, como retorno, teremos uma lista contendo os departamentos com código acima de 12. Como utilizamos a função first_value, obtivemos o primeiro código da tabela e este será apresentado como resultado para todas as linhas presentes, como podemos ver na Figura 8.

Figura 8. Windows Function first_value().
Num segundo exemplo, poderíamos utilizar a cláusula order by para ordenarmos os registros por nome do departamento, onde com isso, obteremos um valor diferente para o valor da função first_value(), como podemos ver presente na Listagem 11.
Listagem 11. Ordenando por nome do departamento.
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
first_value(departamento_cod) OVER (ORDER BY nome_departamento)
FROM funcionarios_windows_function WHERE departamento_cod > 12;Ao contrário da função first_value(), a função last_value() é utilizada para a obtenção do valor presente na última linha de registro presente na tabela, onde utilizamos o nome da coluna como argumento, de igual forma a função anterior. Podemos ver de acordo com a Listagem 12 como proceder com essa função.
Listagem 12. Utilizando a função last_value().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
last_value(departamento_cod) OVER (ORDER BY nome_departamento)
FROM funcionarios_windows_function;Após a consulta, obtivemos o resultado presente na Figura 9, onde o nosso último registro, com base na ordenação por nome de departamento, é o departamento de testes, que corresponde ao código do departamento 16.
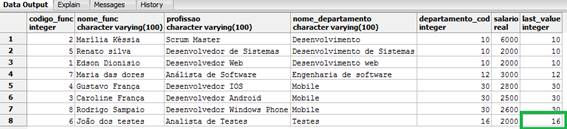
Figura 9. Utilizando a função last_value().
A próxima função a ser vista é a nth_value(), a qual nos possibilita receber um valor diferente do inicial e do final, obtendo assim um valor presente na enésima linha da tabela. Para utilizar esta função passamos o nome da coluna desejada e o enésimo número como argumentos de entrada. Caso o valor informado não seja encontrado na tabela, o valor apresentado pela função será nulo, como mostra a Listagem 13 como proceder.
Listagem 13. Obtendo resultados com a função nth_value().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
nth_value(nome_departamento, 2)
OVER (PARTITION BY departamento_cod ORDER BY nome_departamento)
FROM funcionarios_windows_function;Veja que estamos utilizando a cláusula PARTITION BY para dividirmos os registros com base no código do departamento, onde cada partição criada terá um número de saída, que será o valor que utilizaremos para a função nth_value. Observe o resultado apresentado na Figura 10.
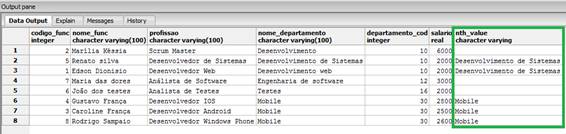
Figura 10. Utilizando a Windows Function nth_value().
Esta função nos permite atribuir valores para grupos de resultados, ou seja, um número inteiro a eles. Para melhor entendermos a sua utilização, vejamos o exemplo presente na Listagem 14.
Listagem 14. Utilizando a Window Function ntile().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
ntile(2)
OVER (ORDER BY departamento_cod)
FROM funcionarios_windows_function;A tabela está dividida em duas partições pela função ntile(), como mostra o resultado presente na Figura 11.
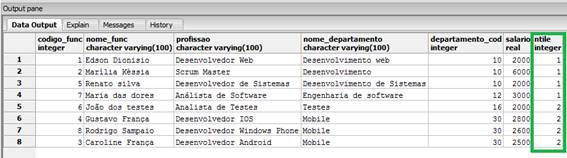
Figura 11. Resultado da utilização do ntile().
Neste próximo exemplo da Listagem 15, vejamos como a função irá se comportar ao utilizarmos o valor 3 como argumento e, com isso, ver o impacto sobre os resultados.
Listagem 15. Utilizando um novo argumento para o ntile().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
ntile(3)
OVER (ORDER BY departamento_cod)
FROM funcionarios_windows_function;Com a mudança do argumento, apenas aumentamos a quantidade de partições que podem ser utilizadas pelo ntile().
A função lag() é utilizada para acessarmos mais de uma linha presente na tabela ao mesmo tempo, sem a necessidade de utilizarmos o SELF JOIN. Para entendermos essa funcionalidade vejamos o código da Listagem 16 como proceder.
Listagem 16. Utilizando a função lag().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
lag(departamento_cod, 3)
OVER (ORDER BY departamento_cod)
FROM funcionarios_windows_function;Veja que passamos para a função o código do departamento e como segundo argumento o valor 3. Nessa hora estamos passando um valor para o deslocamento, que no nosso caso é o 3, e isto significa que o cursor vai começar a partir do quarto registro da tabela. Dessa forma, faremos uma SELF JOIN com base no código do departamento e o restante dos registros, como mostra a Figura 12.
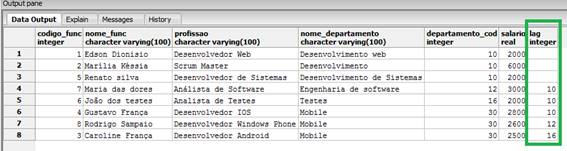
Figura 12. Utilizando a função Lag().
A última função a ser apresentada é a lead(), a qual é utilizada para obtermos os valores retornados para linhas de registro com base no deslocamento abaixo da linha atual da partição. Se o argumento de deslocamento não é informado no momento de chamarmos a função, ela será definida como um, por padrão. Vejamos como isso será executado com base no exemplo apresentado pela Listagem 17. Neste nós temos a tabela com base no código do departamento e, em seguida, chamamos a função lead().
Listagem 17. Utilizando a Windows Function lead().
SELECT codigo_func, nome_func, profissao, nome_departamento, departamento_cod, salario,
lead(nome_departamento, 1)
OVER (PARTITION BY departamento_cod ORDER BY departamento_cod)
FROM funcionarios_windows_function;Podemos ver o resultado da consulta na Figura 13.
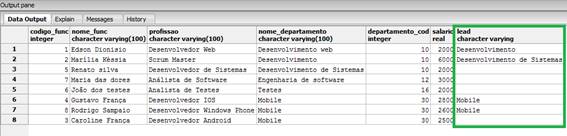
Figura 13. Resultado da utilização da função lead().
Com isso finalizamos o nosso artigo, onde vimos funções que nos auxiliam com relação a melhoria de performance e redução de código, no caso de obtermos resultados sem a necessidade realizarmos JOINS entre tabelas. Esperamos que tenham gostado. Até a próxima! =)
Link
Documentação
http://www.postgresql.org/docs/9.4/static/tutorial-window.html

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






