Na versão 2009, o Delphi atualizou o core do compilador e do IDE para aceitar o padrão Unicode, em substituição ao padrão utilizado até então, o ASCII. Essa mudança fez o mapa de caracteres subir de 255 para mais de 100 mil opções, passando a comportar os caracteres de variados idiomas de todo o mundo, como chinês e russo.
Esse recurso não trouxe diferenças para grupos de desenvolvedores que lidam apenas com caracteres convencionais do nosso alfabeto, mas expandiu a possibilidade de incorporar caracteres de idiomas menos comuns dentro do código fonte das aplicações.
Antes da versão 2009, o tipo string no Delphi seguia o mesmo padrão de caracteres utilizado nas versões mais antigas do Windows, e que fazem parte de uma tabela conhecida como ASCII. Essa tabela possui os principais caracteres (visuais e não visuais) para composição de texto em sistemas computacionais.
O surgimento do padrão Unicode para Windows e Web, representado pela tabela UTF (8 ou 16), possibilitou a representação e mapeamento de todos os caracteres de idiomas existentes. Diante disso, para aceitar a criação de variáveis que atendessem a esse novo padrão, o Delphi criou o tipo WideString.
Contudo, após a versão 2009, devido à comum necessidade de internacionalização das aplicações, o Delphi adotou o WideStringcomo o tipo padrão para strings, enquanto que para representar textos com caracteres em ASCII, foi criado o padrão AnsiString.
Todas as operações com strings conhecidas no Delphi se mantêm as mesmas, exceto as rotinas que trabalham com manipulação de texto em baixo nível (quando há a validação direta dos bytes que compõem a string). Isso ocorre porque os códigos que representam os caracteres nas tabelas ASCII e UTF não são necessariamente os mesmos, o que pode gerar alguns bugs em códigos que trabalhem com textos diretamente em bytes.
Na Listagem 1 temos um exemplo de concatenação de strings, contidas em variáveis, para terem seus valores exibidos em uma caixa de diálogo. Nesse código, as variáveis messageAnsi e messageUnicode foram declaradas com tipos de dados que podem comportar, respectivamente, caracteres ASCII e UTF.
procedure TForm3.Button1Click(Sender: TObject); var messageAnsi: AnsiString; messageUnicode: string; begin messageAnsi :='Atenção!'; messageUnicode :='注意'; ShowMessage(messageAnsi+#13+messageUnicode); messageAnsi:='Внимание'; messageUnicode:='Внимание'; ShowMessage(messageAnsi+#13+messageUnicode); end;
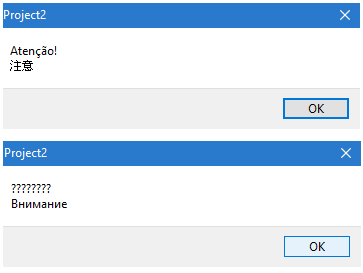
Na Figura 1 podemos ver o resultado do método ShowMessage nos dois casos. Observe que na primeira caixa de diálogo ambos os valores das variáveis são apresentados corretamente, enquanto na segunda o valor da variável messageAnsi é apresentado como “?????”. Isso ocorre porque a variável do tipo AnsiString só trabalha com o range de 255 caracteres da tabela ASCII, na qual não estão contidos os caracteres utilizados (russos, nesse caso).
Saiba mais sobre a manipulação de strings no Delphi
Ao modificarem o compilador e o IDE para aceitarem o padrão Unicode, surgiu um efeito colateral que se tornou “bem-vindo”. O Delphi, por ser uma linguagem case-insensitive, não possuía tanta flexibilidade na escolha de palavras para nomear as variáveis, gerando erros de compilação em trechos como:
Cliente: cliente; String: string; Record = record;
Esse tipo de sintaxe é aceitável em qualquer linguagem case-sensitive, pois “Cliente”, iniciado com maiúsculo, é diferente de “cliente”, iniciado com minúsculo, por exemplo, mas no Delphi não há essa distinção.
Com o uso de strings Unicode no código fonte, o programador Delphi passou a contar com maior versatilidade na escolha dos nomes das variáveis, como pode ser visto no exemplo da Listagem 2.
procedure TForm3.Button2Click(Sender: TObject); var Atenção: AnsiString; 注意 : string; begin Atenção :='Atenção!'; 注意 :='Внимание'; ShowMessage(Atenção+#13+注意); end;
Diferentemente do que se pode imaginar à primeira vista, esse código não gera erros. O compilador compreende perfeitamente que os demais caracteres são normais e podem ser utilizados para nomear variáveis, classes e instâncias. Embora a linguagem ainda seja case-insensitive, a possibilidade de utilizar ç e acentos, por exemplo, dá mais flexibilidade nos nomes escolhidos pelo desenvolvedor, desde que isso não prejudique os padrões de nomenclatura e boas práticas adotados no projeto.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.