


Central Processing Unit (ou CPU) é um dos dispositivos mais importantes que existem em um computador. É lá que todos os outros dispositivos săo coordenados e onde uma série de operaçőes săo realizadas, como soma, subtraçăo, leitura e armazenamento de dados, etc. Essas operaçőes săo realizadas através das instruçőes, que săo apenas números que ativam certos circuitos do processador.
As linguagens de programaçăo săo interpretadas ou compiladas, resultando em instruçőes que a CPU entende. Um simples código escrito em C++ ou T-SQL pode resultar na execuçăo de milhőes de instruçőes. Na grande maioria dos casos, quanto mais instruçőes, mais demorado aquele código irá rodar. Otimizar o uso de CPU de um código significa reduzir o número de instruçőes que săo executadas, ou escolher um conjunto de instruçőes que resultem em menos tempo de processamento.
O SQL Server possui componentes que fazem a interpretaçăo do código T-SQL e, baseado nas cláusulas e comandos utilizados, executam as instruçőes adequadas. Assim como qualquer outro processo no Windows, o SQL Server possui threads e está sujeito aos limites e configuraçőes do ambiente, e, portanto, compreender certos mecanismos e conceitos do sistema operacional é importante para efetuar otimizaçőes em scripts.
Otimizar o consumo de CPU é um desafio, principalmente em código T-SQL. Antes de qualquer açăo, é preciso compreender como o sistema operacional e as ferramentas de análise disponibilizam e mensuram o gasto de CPU para que se possa direcionar as técnicas de otimizaçăo. O Windows e o SQL Server fornecem várias ferramentas para auxiliar no processo de análise. Este artigo irá explorar os conceitos básicos, técnicas e ferramentas que o desenvolvedor ou o DBA podem utilizar para tornar a utilizaçăo de CPU mais eficiente em suas aplicaçőes. Todos os exemplos funcionam a partir da versăo 2005 e os casos específicos de uma versăo serăo informados.
Processador, cores, CPU e hyper thread
É importante definir os termos quando se fala em CPU, pois diferentes fontes os usam como se fossem a mesma coisa. Os próximos parágrafos irăo definir os termos a serem usados no artigo.
Processador se refere ao dispositivo acoplado diretamente no computador, especificamente na placa măe. Podem existir um ou mais processadores em um computador. Cada processador possui um ou mais cores (núcleos). O core é a unidade de processamento. Ele é capaz de realizar as operaçőes independentemente dos outros Cores. O core é capaz de executar um grupo de instruçőes por vez, mas há arquiteturas, como o Simultaneous multithreading (SMT), que otimiza o uso do core, dando a impressăo de que ele executa dois conjuntos de instruçőes por vez. Uma famosa implementaçăo dessa arquitetura é o Hyper Thread, da Intel.
Para o sistema operacional, um processador com dois cores, e com hyper thread habilitado, quatro cores serăo visualizados (dois cores físicos, cada um com dois cores lógicos, resultando em quatro cores lógicos). Na maioria dos casos, o SMT fornece um ganho considerável de performance, mas podem existir casos onde ele atrapalha, devido ao uso de recursos compartilhados, entre outros fatores.
Para esse artigo, o termo CPU será usado frequentemente e se refere a um core enxergado pelo sistema operacional, seja ele físico ou lógico.
Processos e threads
Um dos papéis do sistema operacional é coordenar a execuçăo das instruçőes de diferentes programas. O Windows faz isso por meio de processos e threads. O processo é uma estrutura do Windows que contém diversos elementos, como memória, código (as instruçőes), etc. Todo processo possui pelo menos uma thread.
A thread é uma estrutura que o Windows utiliza para, principalmente, organizar a execuçăo de instruçőes. Quando se diz que “uma thread está executando”, significa que a CPU está executando as instruçőes associadas ŕquela thread. Basicamente, as instruçőes que ficam salvas em executáveis, ou em DLLs, săo carregadas para a memória e o Windows é responsável por preparar e configurar a primeira thread para executar corretamente essas instruçőes. O programa pode, usando serviços do sistema operacional (ex.: funçăo CreateThread, da API do Windows) criar mais threads. A thread contém todas as informaçőes necessárias para que as execuçőes das instruçőes (BOX 1) aconteçam e que permita ao Windows interromper e continuar a execuçăo da thread quando, por exemplo, uma outra thread de maior prioridade precisar ser executada. Threads de diferentes processos podem concorrer por uma CPU e o Windows contém todos os mecanismos que coordenam essa concorręncia.
Apenas uma thread pode estar executando em cada CPU por vez. Se há quatro CPUs disponíveis, haverá no máximo quatro threads em execuçăo (lembre-se que, nesse artigo, o termo CPU se refere a CPU lógica enxergada pelo sistema operacional). O Windows armazena o tempo total de CPU usado para cada thread. Por exemplo, se uma thread executa por cinco milissegundos, é interrompida, e depois executa por mais 10 milissegundos, entăo o tempo total gasto pela thread até o momento săo de 15 milissegundos.
O SQL Server é um processo “multi-thread”, o que significa que ele possui diversas threads trabalhando para executar o código T-SQL e garantir seu funcionamento.
Ao executar uma instruçăo, a CPU obtém o código da próxima instruçăo da memória. Um registrador especial da CPU, chamado “Instrunction Pointer” (IP), contém o endereço da próxima instruçăo a ser executada. Ŕ medida que a CPU carrega a instruçăo da memória, ela incrementa o IP, de forma que contenha o próximo endereço da instruçăo a ser executada. Há inclusive instruçőes que alteram o valor do IP, permitindo ŕ CPU buscar a próxima instruçăo em um endereço diferente, alterando dessa forma o fluxo (muito utilizado para implementar estruturas condicionais como IF). Assim, “executar uma tarefa” se resume a obter a próxima instruçăo da memória e executá-la, repetindo esse processo até que a última instruçăo do programa seja executada.
Além do IP, há outros registradores que podem conter valores necessários para a execuçăo de uma instruçăo. Programas săo isso, apenas a execuçăo de uma instruçăo após a outra, e diferentes programas possuem sequęncias diferentes. Uma thread no Windows é uma estrutura de dados, semelhante a um struct do C/C++ ou a uma tabela, que fica na memória do Kernel do Windows. Entre as diversas informaçőes dessa estrutura, estăo os registradores da CPU. A operaçăo de “retirar” uma thread da CPU é salvar todas as informaçőes dos registradores nessa estrutura, incluindo o IP. Assim, o Windows pode interromper uma determinada sequęncia de execuçăo, iniciar outra (carregando as informaçőes salvas na estrutura respectiva), e posteriormente retomar a sequęncia, bastando apenas recarregar os valores dos registradores. Isso é a troca de contexto (Context Switch). As instruçőes săo carregadas para a memória quando o processo se inicia e podem ser carregadas sob demanda, com o uso de DLLs, por exemplo. Todo processo tem uma memória associada e as instruçőes săo carregadas nessa memória. Assim, as threads de um determinado processo sempre apontam para os endereços de memória associados com o mesmo. Vocę pode obter muito mais detalhes dessa estrutura no livro Windows Internals.
O uso de CPU
Há várias ferramentas disponíveis para se medir o consumo de CPU no Windows. Vale citar o Process Explorer (link para download na seçăo Links), Task Manager (Gerenciador de Tarefas) e o perfmon (ou System Monitor).
Essas ferramentas geralmente apresentam o consumo de CPU como uma porcentagem. Essa informaçăo indica quanto tempo a CPU esteve ocupada durante um intervalo de tempo. Uma CPU ocupada está executando alguma instruçăo. Por exemplo, se uma CPU está em 50% durante um intervalo de um segundo, significa que a CPU passou 500 milissegundos processando instruçőes (500ms/1000ms). A mesma lógica pode ser aplicada para o cálculo de uso de CPU de uma única thread: se uma thread gasta 70% de CPU em um intervalo de um segundo, isso significa que a thread gastou 700 milissegundos executando instruçőes naquele intervalo. A fórmula está descrita a seguir:
Tempo CPU Gasto
Intervalo
Conforme mencionado, o Windows registra o tempo total de CPU gasto para cada thread existente desde a criaçăo da mesma. Essas informaçőes săo armazenadas nas estruturas internas que somente o código do sistema tem acesso. Uma aplicaçăo que deseja ter acesso a essa informaçăo pode usar funçőes da API do Windows como GetThreadTimes e QueryThreadCycleTime. Como é um valor acumulado durante toda a vida da thread, obter o total de CPU usado em um intervalo de um segundo, por exemplo, segue um algoritmo bem simples:
Para obter o tempo gasto em um intervalo qualquer, basta uma subtraçăo. A Figura 1 ilustra isso melhor.
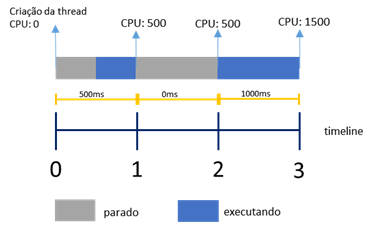
Figura 1. Gasto de CPU em um intervalo
Veja que o ciclo de vida de uma thread ao longo de tręs segundos e a cada segundo, o gasto de CPU é medido subtraindo o valor de CPU atual pelo valor de CPU anterior. Os retângulos de cor azul indicam o tempo gasto pela thread executando algo. Os retângulos com a cor cinza indicam o tempo que a thread está fora da CPU. O texto “CPU:” indica o tempo total de CPU gasto pela thread. No instante “0”, a thread é criada e o tempo total de CPU é 0. Após um segundo, o tempo total de CPU para a thread foi de 500 milissegundos, que foram os 500ms gastos no final do intervalo entre 0s e 1s (representado pelo retângulo azul). No intervalo entre 1s e 2s, năo houve qualquer gasto de CPU pela thread, porém, como o Windows guarda o tempo total gasto, o valor ainda permanece em 500. Quando se passa tręs segundos desde que a thread foi criada, o tempo total de CPU passou a ser 1500. A diferença entre o tempo coletado no instante 3 e o tempo coletado no instante 2 revela que a thread gastou 1000 milissegundos de CPU, ou, um segundo nesse intervalo. Como a coleta é feita a cada um segundo (intervalo de monitoramento), entăo a thread gastou 100% de CPU entre o instante 3 e 2, gastou 0 % de CPU entre o instante 2 e 1, e 50% de CPU entre o instante 1 e 0. Essa fórmula simples pode ser aplicada a praticamente qualquer caso em que se deseje mensurar o gasto de CPU em um determinado intervalo. Posteriormente nesse artigo, será demonstrada uma variaçăo desse exemplo para calcular o gasto de CPU de um trecho de um script T-SQL.
As ferramentas que exibem o consumo de CPU seguem a mesma lógica, medindo o tempo gasto de CPU em um intervalo. Também, boa parte dessas ferramentas permitem alterar esse intervalo. Isso significa que o percentual de uso de CPU pode mudar dependendo do intervalo utilizado. Por isso é importante certificar-se de que, ao comparar o gasto de CPU de diferentes ambientes, o intervalo usado seja igual em todos.
No caso de computadores com mais de uma CPU, o consumo de CPU total da máquina é uma média: em um computador com duas CPUs, onde uma está em 100% e a outra em 0%, o consumo total será de 50%. Se as duas CPU’s estiverem em 50%, o consumo total também será de 50%. A fórmula é apresentada a seguir:
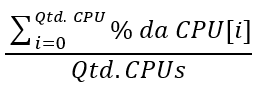
É importante entender que existem duas métricas a respeito do gasto de CPU: tempo total e uso durante um intervalo. O que as ferramentas geralmente mostram é o segundo caso. Mas o primeiro merece sua atençăo pois é o valor reportado pelas DMV’s do SQL Server. O tempo total de CPU é o tempo gasto desde a criaçăo da thread. No caso do SQL Server, é o tempo total gasto desde o início de uma requisiçăo, como um comando de SELECT, ou o total, somadas todas as execuçőes de uma query.
Há ainda o tempo de espera, que é o tempo que a thread passou aguardando por recursos, como I/O ou locks. O tempo de espera mais o tempo total de CPU é o tempo total gasto para executar uma tarefa e nesse artigo será chamado de “duraçăo”:
duraçăo = Tempo CPU + Tempo de EsperaPara compreender como essas tręs métricas pode ...

Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.