Apesar de ser uma ferramenta poderosa e que aumenta significativamente a produtividade na escrita de aplicações corporativas, o Spring Framework ainda é alvo de críticas a respeito do tempo necessário para se iniciar o desenvolvimento de novos projetos. Pensando nisso, foi introduzido no Spring 4.0 um novo projeto que tem, dentre seus objetivos, responder a estas críticas e, como veremos neste artigo, também mudar bastante nossa percepção acerca do desenvolvimento de aplicações para a plataforma Java EE. Este projeto é o Spring Boot.
Saiba mais: Cursos de Java
A principal crítica feita ao Spring é sobre o modo como configuramos o seu container de injeção de dependências e inversão de controle usando arquivos de configuração no formato XML. Artefatos estes que, conforme aumentam de tamanho, se tornam cada vez mais difíceis de serem mantidos, muitas vezes se transformando em um gargalo para a equipe de desenvolvimento. No decorrer da história do framework vimos que este problema foi sendo tratado a partir de uma série de melhorias no modo como declaramos nossos beans a cada novo release: namespaces na versão 1.2, anotações na versão 2.0 e, finalmente, passamos a poder tratar arquivos XML como um artefato opcional no lançamento da versão 3.0, que nos trouxe a possibilidade de declarar nossos beans usando apenas código Java e anotações.
Relacionado: O Que é o Spring?
Outra crítica relevante diz respeito à complexidade na gestão de dependências. Conforme nossos projetos precisam interagir com outras bibliotecas e frameworks como, por exemplo, JPA, mensageria, frameworks de segurança e tantos outros, garantir que todas as bibliotecas estejam presentes no classpath da aplicação acaba se tornando um pesadelo. Não é raro encontrarmos em projetos baseados em Maven arquivos POM nos quais 90% do seu conteúdo sejam apenas para gestão de dependências. E esta é apenas a primeira parte do problema. O grande desafio surge quando precisamos integrar todos estes componentes.
Saiba mais: Curso Completo de Java
O projeto Spring Boot (ou simplesmente Boot) resolve estas questões e ainda nos apresenta um novo modelo de desenvolvimento, mais simples e direto, sem propor novas soluções para problemas já resolvidos, mas sim alavancando as tecnologias existentes presentes no ecossistema Spring de modo a aumentar significativamente a produtividade do desenvolvedor.
Trata-se de mais um framework, mas talvez a melhor denominação seja micro framework. Como mencionado na introdução deste artigo, seu objetivo não é trazer novas soluções para problemas que já foram resolvidos, mas sim reaproveitar estas tecnologias e aumentar a produtividade do desenvolvedor. Como veremos mais à frente, trata-se também de uma excelente ferramenta que podemos adotar na escrita de aplicações que fazem uso da arquitetura de microsserviços.
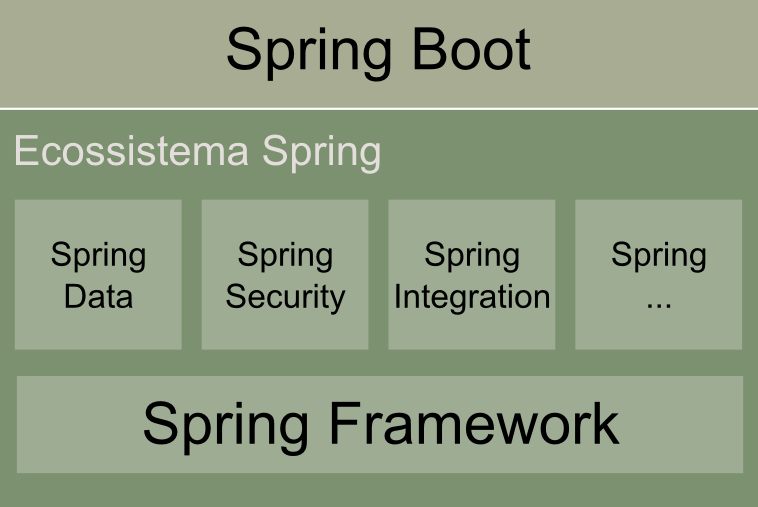
Se pudéssemos desenhar um diagrama arquitetural do Spring Boot, este seria muito similar ao que vemos no Grails: uma fina camada sobre tecnologias já consagradas pelo mercado, tal como podemos verificar na Figura 1. A grande mudança está no modo como agora empacotamos e acessamos estas soluções.
O desenvolvedor não precisa se preocupar em aprender novas tecnologias, pois todo o conhecimento adquirido sobre o ecossistema Spring é reaproveitado. A principal diferença se dá no modo como configuramos, organizamos nosso código e executamos a aplicação, tal como veremos neste artigo.
Como sabemos, todo framework se baseia em alguns princípios. No caso do Boot, são quatro:
Na documentação oficial do projeto Boot, assim como em posts a seu respeito, encontraremos muitas vezes o termo opinionated view (visão opinativa). Ao citá-lo, os responsáveis pelo desenvolvimento da ferramenta na realidade estão se referindo ao conceito de convenção sobre configuração, porém levemente modificado.
O conceito de convenção sobre configuração é o grande motor por trás do ganho de produtividade do Spring Boot, porém não foi algo introduzido por ele. Frameworks como Ruby on Rails e Grails já o aplicam há bastante tempo. A ideia é bastante simples: dado que a maior parte das configurações que o desenvolvedor precisa escrever no início de um projeto são sempre as mesmas, por que já não iniciar um novo projeto com todas estas configurações já definidas?
Pense no modo como estamos habituados a trabalhar, por exemplo, em um projeto baseado em Spring MVC. Nossos primeiros passos serão incluir as dependências necessárias no projeto, adequar o arquivo web.xml e organizar a estrutura do nosso código fonte para que possamos iniciar o desenvolvimento. E isto é feito no início de todo projeto. Sendo assim, por que não já começar com isto pronto?
Voltando nossa atenção para esse termo, é importante prestar atenção na palavra sobre em “convenção sobre configuração”. Note que não é “convenção em vez de configuração”. Não temos uma imposição aqui, mas sim sugestões. Deste modo, se seu projeto requer um aspecto diferente daquele definido pelas convenções do framework, o programador precisa alterar apenas aqueles locais nos quais a customização se aplica.
Indo além na análise dos termos mencionados, percebemos que no Spring Boot não foi usado o termo “convenção sobre configuração”, mas sim “visão opinada sobre configuração”. Dito isso, você pode estar se perguntando: Qual a diferença entre eles? A diferença está no fato da equipe de desenvolvimento do Spring Boot assumir que algumas escolhas tomadas baseiam-se em aspectos subjetivos e não estritamente técnicos. Um exemplo é a escolha da biblioteca de log. Foi adotado o Log4J, no entanto o Commons Logging seria uma opção igualmente competente. Sendo assim, por que um ao invés do outro? Em grande parte, preferências pessoais.
Há outra grande vantagem na adoção deste princípio. A partir do momento em que a equipe conhece as convenções, torna-se menor o tempo necessário para que novos membros se adaptem ao projeto e a manutenção passa a ser mais simples.
O projeto Spring Boot nos permite criar dois tipos de aplicações: as tradicionais, escritas primariamente em Java; e uma segunda forma, chamada pela equipe de desenvolvimento do Boot de “Spring Scripts”, que nada mais são do que códigos escritos em Groovy – o que não é de se estranhar, dado que desde o lançamento da versão 4.0 do framework há uma forte tendência da Pivotal em abraçar esta linguagem de programação e torná-la cada vez mais presente no dia a dia do programador Java.
Para ilustrar esse tipo de aplicação, vamos escrever um “Olá mundo!” bastante simples que nos conduzirá na apresentação de alguns conceitos fundamentais por trás do Spring Boot. Todo o código fonte do nosso projeto pode ser visto na Listagem 1.
@RestController
class OlaMundo {
@RequestMapping("/")
String home() {
"Olá mundo!"
}
}Antes de explicar o código fonte apresentado (que facilmente pode ser reduzido a uma única linha, o que fica de exercício para o leitor), vamos executar nossa aplicação. Para tal, se faz necessário que tenhamos instalado em nosso computador a interface de linha de comando do Spring Boot (CLI: Command Line Interface).
Como pode ser verificado, a instalação é bastante simples: baixe a distribuição oficial no site Spring Initializr (veja o endereço na seção Links), a descompacte em um diretório de sua preferência e depois inclua o diretório bin no path do seu sistema operacional.
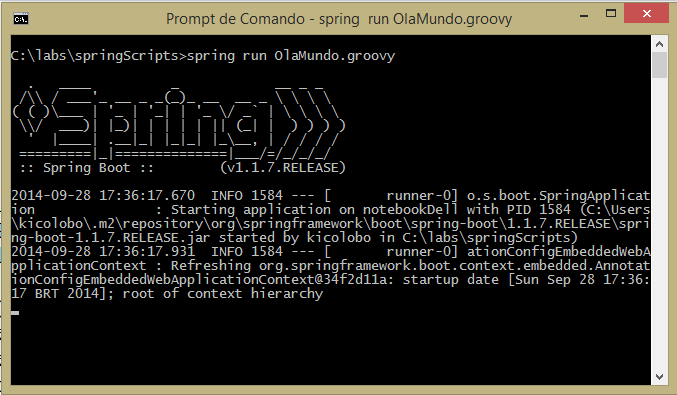
Instalado o CLI e salvo o script exposto na Listagem 1, tudo o que precisamos fazer para iniciarmos a execução do projeto é executar o comando spring run OlaMundo.groovy. Feito isso, seremos saudados com uma saída similar à exposta na Figura 2.
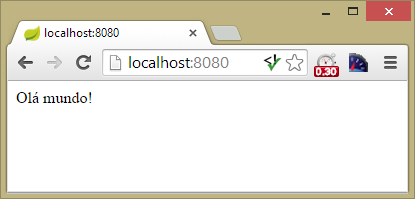
Tendo nosso script sido inicializado, o que leva apenas alguns segundos, inicie um navegador de sua preferência e aponte para o endereço http://localhost:8080. Feito isso, veremos a mensagem “Olá mundo!” tal como exposto na Figura 3.
Após este rápido tour no qual vimos como instalar o CLI e como executar nosso Spring Script, podemos dissecar nosso código fonte.
O leitor atento deve ter estranhado algumas ausências na Listagem 1. Para começar, não há qualquer instrução import no nosso código Groovy, mas mesmo assim incluímos duas anotações (@RestController e @RequestMapping) que não estão nos pacotes padrão que normalmente são importados pelo Groovy. Então, como nosso script executa sem erros?
Antes de ser executado, o script é processado antecipadamente pelo Spring Boot tirando máximo proveito das características dinâmicas da linguagem Groovy, que nos permite modificar código em tempo de execução através do seu Meta Object Protocol (MOP) e em tempo de compilação usando transformações AST, capazes de, dentre outras coisas, incluir instruções de import ausentes, assim como adicionar anotações em alguns dos métodos. Outra característica do Groovy bastante explorada pelo Boot é o Grape, gerenciador de dependências nativo da linguagem, similar ao Maven ou Ivy. Com ele o desenvolvedor obtém de forma transparente em tempo de execução todas as dependências necessárias para a execução do script como, por exemplo, drivers JDBC, bibliotecas, etc. O resultado obtido pode ser visto na Listagem 1, que apresenta um código limpo e direto com o mínimo de boiler plate.
Quando executamos o comando spring run, o Spring Boot inicia o processo de análise do código fonte do script Groovy que passamos como parâmetro. Ao encontrar a anotação @RestController (pacote org.springframework.web.bind.annotation), nosso script será interpretado como a implementação de um serviço REST.
O próximo passo é descobrir as URLs de acesso que são disponibilizadas pelo nosso projeto. Em nosso código, elas serão identificadas pela presença da anotação @RequestMapping, que é exatamente a mesma que usamos ao desenvolver aplicações baseadas em Spring MVC. @RequestMapping recebe como parâmetro o caminho relativo da URL em relação ao contexto da aplicação. No caso a Listagem 1, a raiz corresponde à função home, que retorna um objeto do tipo String.
Para o programador que conhece o Spring MVC, a principal mudança está no modo como este é empacotado e executado pelo Spring Boot. Todas as técnicas adotadas no desenvolvimento de aplicações baseadas no MVC se mantêm. Talvez o leitor sinta falta apenas da anotação @ResponseBody. No caso do Boot, não precisamos mais incluí-la, pois ao encontrar um método anotado com @RequestMapping, @ResponseBody será inserida automaticamente.
Uma mudança interessante a se observar é a aparente ausência do Servlet container. Na realidade, ele está presente, porém é executado de uma forma ligeiramente diferente. Ao invés de empacotarmos nosso projeto em um arquivo WAR para ser implantado no servidor, agora o próprio Spring Boot se encarrega de embutir o servidor entre as dependências do projeto, iniciá-lo e, de uma forma completamente transparente, implantar nossa aplicação neste.
Assim, Spring Scripts são uma solução interessante quando precisamos escrever algum serviço REST simples e direto como, por exemplo, aqueles que consistem em meros CRUDs a bases de dados preexistentes. Outro aspecto interessante que merece nossa atenção é a crescente importância da linguagem Groovy dentro do ecossistema Spring.
Desde 2012, um termo que tem ganhado cada vez mais atenção entre os arquitetos é “microserviço” (ou microsservices). Quando lançada a versão 4.0 do Spring, foi feita uma referência a esse estilo arquitetural, visto pela equipe responsável pelo desenvolvimento do framework como uma das principais tendências do mercado. O Spring Script, que expusemos no tópico anterior, apesar de extremamente rudimentar, adota esse estilo arquitetural. Mas, afinal, o que é um microserviço?
Dependendo da fonte consultada, esse estilo arquitetural é visto como uma novidade (ao menos para os desenvolvedores Java) ou apenas uma variação do já conhecido SOA (Service Oriented Architecture). Ignorando essa questão, em sua essência, o problema que a arquitetura baseada em microserviços busca resolver é a eterna questão da componentização. Sendo assim, para que possamos definir o que é um microserviço, primeiro precisamos entender o que é um componente.
Uma boa definição de componente é dada por James Lewis e Martin Fowler, no artigo chamado Microservices. Segundo os autores, componente é “uma unidade de software que pode ser aprimorada e substituída de forma independente”. Para simplificar a compreensão, vamos pensar em um exemplo bastante comum: suponha que seu sistema utilize uma biblioteca X para o envio de e-mails.
Em um primeiro momento esta biblioteca funciona como esperamos. Ligamos nosso código a esta durante a compilação e tudo o que faremos serão chamadas às classes ou funções que ela disponibiliza. Imagine agora que os responsáveis pela evolução da biblioteca consigam ganhos enormes de desempenho aprimorando os algoritmos internos adotados. Se a interface for mantida, seu código se beneficiará destes ganhos de forma transparente. Basta que você atualize a versão da biblioteca em seu código fonte e em seguida o compile novamente (ou apenas substitua o binário da biblioteca).
Realizada a atualização, uma nova implantação do sistema no servidor ou nas máquinas clientes é feita e pronto, só precisamos aguardar pelo cliente entrando em contato para lhe parabenizar pelo ganho de desempenho que ele está experimentando após o upgrade.
Esse modelo de componentização funciona bem e a prova disso está no fato de ser o mais adotado no desenvolvimento de qualquer projeto (lembre-se que todo projeto faz uso de alguma biblioteca). No entanto, e quando não podemos parar o sistema para fazer uma implantação ou, melhor ainda, precisamos minimizar ao máximo o tempo de down time? Indo além: e se quiséssemos tornar componentizáveis os requisitos funcionais do nosso projeto? Imagine que queiramos apenas resolver um bug que encontramos no componente “cadastro de clientes” em um ERP sem ter de parar todo o sistema. E se no futuro percebêssemos que nossa implementação deste componente de negócio deveria ter sido feita em outra linguagem ou plataforma computacional e fosse de nosso interesse corrigir esse erro?
Surge um “novo” tipo de componente: o serviço. A grande diferença entre este e a biblioteca está no fato dele não ser executado no mesmo processo que o software cliente. Normalmente é executado em uma máquina distinta e toda iteração com o serviço ocorre através de chamadas remotas que, tal como descritas em inúmeros artigos e livros escritos a partir de 2012, se manifestam sob a forma de chamadas REST ou mensageria.
Este modelo arquitetural também nos diz que devemos decompor nossos sistemas em diversos serviços, cada qual responsável por um conjunto de requisitos funcionais relacionados. Neste ponto é importante que tomemos muito cuidado com a interpretação dada ao prefixo “micro”. Idealmente o microserviço deve ser suficientemente pequeno para que possa ser inteiramente compreendido por aqueles responsáveis por sua escrita. Por outro lado, não deve ser exageradamente pequeno, dado que assim aumentaria significativamente o custo de manutenção do sistema como um todo.
Ao adotar uma arquitetura baseada em microserviços a equipe deve levar em consideração novos custos como, por exemplo, chamadas remotas que são ordens de magnitude mais caras que os locais e a manutenção de processos independentes, o que requer uma forte disciplina de gerência de configuração e administração de sistemas. Além disso, conseguir mapear todos os relacionamentos entre processos pode se mostrar bastante complexo conforme o número de serviços aumenta.
Vale a pena mencionar que uma importante diferença entre microserviços e o SOA é a ausência do ESB. Os serviços são implementados de tal forma que um sabe da existência do outro, ou seja, sabe que alguém implementará um contrato do qual sua execução depende.
Por ser um processo independente, o microserviço também deve prover a infraestrutura necessária para que possa ser facilmente implantado. Esta infraestrutura deve compreender o essencial: facilitadores de implantação e métricas que ajudem a equipe responsável pela administração, além de uma boa documentação que possibilite a todos os envolvidos conhecer os serviços que comporão a arquitetura do sistema.
Como veremos até o final deste artigo, Spring Boot satisfaz todas estas necessidades de uma forma bastante simples e produtiva.
Outro tipo de aplicação que pode ser desenvolvida com o Spring Boot são aquelas empacotadas no formato JAR ou WAR. Tratam-se de aplicações Java baseadas no ecossistema Spring já conhecido pelos desenvolvedores que o adotam como framework.
Nesse tipo de aplicação não é necessária a instalação do CLI do Spring Boot. Nosso único requisito é a presença de um sistema de build automatizado. Para isso, há duas alternativas providas pela Pivotal: Maven (3.0 ou posterior) e Gradle. Dado a maior popularidade da primeira opção, neste artigo iremos adotar o Maven como sistema de build. Ao leitor que prefere Gradle, é importante salientar que não há grandes mudanças no modo como deve proceder e a documentação oficial é rica em exemplos.
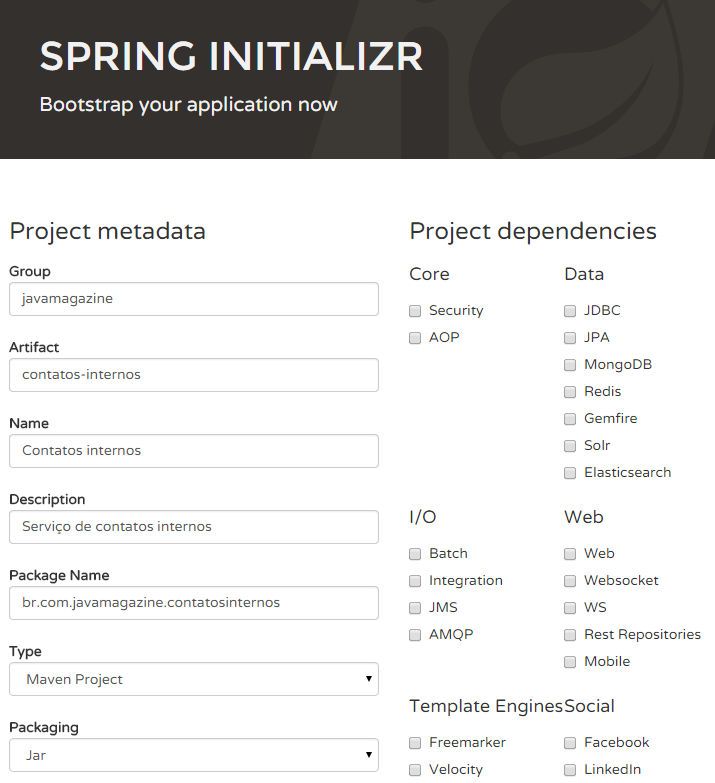
Para tornar o mais fácil possível o início de novos projetos, a Pivotal criou o site Spring Initializr. Nele, há um assistente no qual o desenvolvedor seleciona quais tecnologias deseja incluir em seu projeto, como Spring Data, Spring Security e tantas outras, preenche os campos fornecidos e, uma vez finalizado o preenchimento do formulário, simplesmente clica sobre o botão Generate Project. Feito isso, será gerado um arquivo zip, a ser descompactado no diretório de preferência do usuário. Em seguida, basta importá-lo usando sua IDE favorita. Na Figura 4 podemos ver as configurações usadas na criação do nosso projeto. Este irá se tratar de um microserviço que fornecerá para nossa empresa fictícia um cadastro de contatos internos, que poderá ser compartilhado por diversos outros serviços.
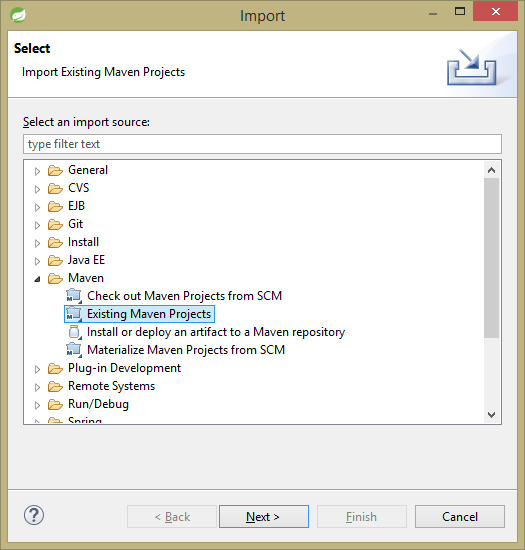
Caso esteja usando como IDE o Eclipse com o plugin m2e, que oferece suporte ao Maven, o processo de importação do projeto é bastante simples. Para isso, vá ao menu File e clique sobre a opção Import. Na janela de importação que surgir (Figura 5), clique sobre a opção Existing Maven Project. Dando um duplo clique sobre esta opção, aparecerá a janela Import Maven Projects. Agora, basta clicar sobre o botão Browse, selecionar o diretório no qual foi descompactado o projeto baixado do site Spring Initializr e, depois, clicar no botão Finish. Deste modo nossa IDE já estará pronta para trabalhar com o projeto.
Com o projeto criado e devidamente importado em nossa IDE, chegou o momento de entender como o Spring Boot resolve o problema do gerenciamento de dependências. Isso é feito através da modularização das diversas tecnologias que compõem o ecossistema Spring em starter POMs. Tratam-se de arquivos POM previamente configurados pela equipe de desenvolvimento do framework que já contêm todas as configurações necessárias para que o programador possa usar imediatamente qualquer uma das tecnologias mantidas pela Pivotal ou mesmo por terceiros.
Como podemos verificar, a configuração inicial do projeto em si também é bastante simples. Todo projeto Spring Boot baseado em Maven tem como arquivo POM pai a configuração exposta na Listagem 2.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.1.7.RELEASE</version>
<relativePath/>
</parent>É importante mencionar que a versão 1.1.7 do Spring Boot é baseada na versão 4.0.7 do Spring Framework, e não na 4.1. Versões futuras do framework farão o upgrade para o último release em breve, de acordo com a equipe responsável pelo desenvolvimento.
Com esta simples configuração já podemos desenvolver aplicações desktop, mas dado que nosso objetivo é implementar um microserviço que usará o padrão REST, faz-se necessário incluir mais um starter POM, o spring-boot-starter-web. Para isso, precisamos modificar o arquivo pom.xml do projeto, mais especificamente no interior da tag <dependencies>, para que fique tal como exposto na Listagem 3.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Demais dependências omitidas -->
</dependencies>Por padrão, o site Spring Initializr já inclui no pom.xml do projeto as dependências spring-boot-starter e spring-boot-starter-test. A primeira fornece as funcionalidades básicas do Spring Boot, enquanto a segunda adiciona o suporte a testes unitários e integrados do Spring Framework. Tudo o que precisamos fazer foi incluir a dependência spring-boot-starter-web, que nos fornece todo o suporte ao Spring MVC e também já incluí a versão embarcada do Tomcat (versão 7.0.55), que será usada na execução do nosso projeto caso seja empacotado no formato JAR.
Com este exemplo, verifica-se que se for necessário usar alguma tecnologia pertencente ao ecossistema Spring, incluí-la no projeto é bastante simples. Basta consultar a lista de Starter POMs presente na documentação oficial do projeto (veja o endereço na seção Links) e adicionar a dependência necessária no pom.xml.
Com o problema das dependências resolvido, chegou a hora de conhecermos como o Boot põe em prática o conceito de convenções sobre configuração. Para tal, começaremos pela análise da classe Application (Listagem 4), que foi gerada automaticamente pelo assistente que usamos no site Spring Initializr. Trata-se do “equivalente Java” ao Spring Script que vimos no início do artigo. É por esta razão que vemos em sua implementação aquilo que não precisamos digitar em Groovy: os imports e as anotações @Configuration e @ComponentScan.
package br.com.javamagazine.contatosinternos;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan
@EnableAutoConfiguration
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}O programador acostumado a escrever aplicações web e que há anos não implementa um projeto desktop possivelmente sentirá nostalgia ao contemplar o único método presente na classe Application: o velho método main(): que todos nós conhecemos em nosso primeiro contato com a linguagem Java.
Um aspecto que causa impacto na experiência inicial com o Spring Boot é o fato do desenvolvedor não precisar se preocupar com a configuração de um servidor Servlet, pois o Apache Tomcat já vem embutido em nosso projeto de forma transparente. Por padrão, quando nosso projeto for empacotado, todas as dependências do Tomcat serão incluídas em um único arquivo JAR gerado pelo Boot. E para executar nosso projeto, basta executar o comando: java –jar [arquivo JAR]. Como estamos falando de convenções sobre configurações, caso seu projeto requeira empacotamento no formato WAR, deve-se apenas alterar a configuração do projeto, um procedimento bastante simples que veremos mais à frente, quando tratarmos da questão da implantação do projeto.
Conforme verificado, nosso método main() é composto por uma única linha, na qual executamos o método estático run() da classe SpringApplication. Esse método recebe dois parâmetros: uma classe e os argumentos que passamos para nossa aplicação quando esta é iniciada pela linha de comando.
A classe SpringApplication é um elemento fundamental do Spring Boot, sendo responsável por executar a inicialização do projeto. Voltando ao método run(), a classe que passamos como primeiro parâmetro passará a ser considerada o ponto de partida para a execução do sistema. No processo de análise, o sistema irá encontrar a anotação @Configuration, uma velha conhecida daqueles que já trabalharam com o Spring 3.x. Outra anotação que será levada em consideração é @ComponentScan, responsável por instruir o Spring Boot a buscar por beans definidos com anotações presentes no pacote da classe anotada (Application, neste exemplo), assim como todos os sub-pacotes do pacote no qual a classe que passamos como parâmetro se encontra.
No entanto, a anotação mais importante para nós é a @EnableAutoConfiguration, que deve ser incluída apenas na classe responsável pela inicialização do sistema. Esta instrui o Spring Boot a aplicar seu recurso de autoconfiguração, ou seja, sua implementação do conceito de convenção sobre configuração que iremos tratar agora.
Todo POM starter que incluímos entre as dependências do nosso projeto possui uma classe de autoconfiguração responsável por iniciá-lo e aplicar as configurações padrão para aquela funcionalidade. Sendo assim, quando incluímos, por exemplo, o módulo spring-boot-starter-web, neste há uma destas classes e ela será responsável por fazer boa parte do trabalho chato: configurar o arquivo web.xml, buscar todas as classes de controle, etc.
Na realidade, o recurso de autoconfiguração do Spring Boot é muito mais poderoso do que isso. Ele é capaz de, analisando as dependências do projeto, já tornar algumas configurações prontas para o desenvolvedor. Um bom exemplo ocorre quando incluímos uma dependência para o banco de dados HSQLDB junto com o starter POM spring-boot-starter-data-jpa, que fornece acesso ao módulo JPA do projeto Spring Data, tal como exposto na Listagem 5.
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>O recurso de auto configuração do Spring Boot é suficientemente inteligente para automaticamente detectar a presença do HSQLDB e seu driver JDBC e já criar um pool de conexões pronto para ser usado por toda a aplicação. Claro, esta é a configuração mais básica possível, e todos os dados são armazenados apenas em memória, mas como se trata de convenções sobre configuração, basta sobrescrever este comportamento.
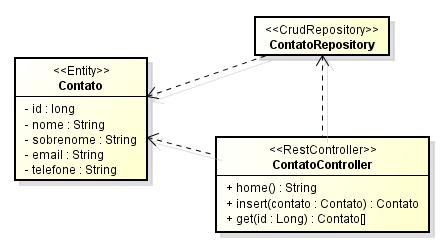
Para vermos o Spring Boot na prática, vamos implementar um microserviço que consistirá em um diretório de contatos internos, ideal para o uso em intranets que precisem compartilhar esse tipo de informação entre diferentes sistemas. Como exemplo, implementaremos uma interface REST bastante simples, que contém apenas duas funções: listar e incluir contatos. Para minimizar o tamanho de nosso exemplo, não iremos incluir as funcionalidades de exclusão e edição. Com relação às dependências necessárias, usaremos aquelas que já foram apresentadas nas Listagens 3 e 5. Na Figura 6 podemos ver as classes que compõem nosso microserviço, todas presentes no mesmo pacote que a classe Application, exposta na Listagem 4.
Pela análise das principais classes de domínio do nosso sistema, expostas na Figura 6, nota-se que uma base de dados relacional atenderá os requisitos do nosso projeto, o que nos dá uma excelente justificativa para adotarmos o projeto Spring Data for JPA, que nos oferecerá todo o suporte que precisamos. O Spring Data é um projeto guarda-chuva da Pivotal que tem dois objetivos principais: facilitar e homogeneizar a manipulação de diferentes tecnologias de acesso a dados como, por exemplo, MongoDB, Redis, GemFire, Couchbase, JDBC e, finalmente, JPA, que será a tecnologia adotada no projeto exemplo.
O recurso central do Spring Data é o conceito de repositório (repository) que, como o nome já indica, trata-se de um componente de acesso e persistência de informações. Seu objetivo é minimizar ao máximo o código que o desenvolvedor precisa escrever tanto para as operações básicas de CRUD, como para a busca de informações. Indo direto à parte prática, na Listagem 6 podemos ver o repositório que escrevemos para a nossa entidade Contato. A partir dela iremos conhecer o básico por trás do funcionamento do Spring Data.
import org.springframework.data.repository.CrudRepository;
public interface ContatoRepository extends CrudRepository<Contato, Long>{
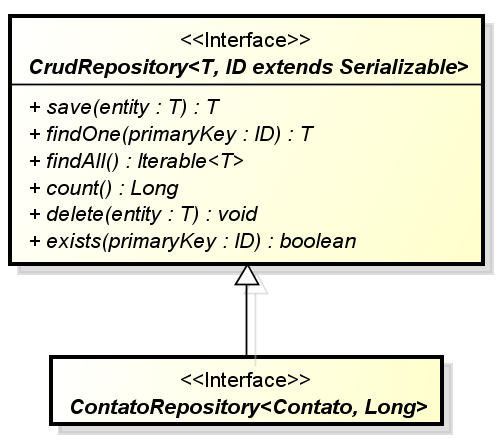
}Por mais incrível que possa parecer, este é todo o código que precisamos escrever para o nosso projeto relacionado à persistência e obtenção de dados, não sendo necessário o esforço de fornecer uma implementação desta interface. Deste modo, de onde vem a implementação desta então? Ela é gerada de forma automática pelo Spring Data em tempo de execução! Para entender isso, basta observar que a interface ContatoRepository estende CrudRepository e é declarada com dois parâmetros de tipo que correspondem à nossa classe de domínio e ao tipo de dados que adotamos como identificador em nosso banco de dados (Long). A interface CrudRepository identifica no Spring Data um tipo de repositório que disponibiliza tudo o que é necessário para a execução das operações básicas de um CRUD. Deste modo, esta já nos fornecerá métodos para listagem, inclusão, edição e exclusão de registros na base de dados. Na Figura 7 podemos ver as principais operações que estarão disponíveis para nosso repositório.
Voltando à Listagem 6, o leitor deve ter observado a ausência de qualquer anotação com a qual estamos acostumados a lidar com o Spring na hora de declararmos nossos beans. Sendo assim, como ele estará disponível para ser injetado e usado em nosso controlador? A resposta é simples: através do recurso de autoconfiguração do Spring Boot. Quando declaramos o Starter POM do Spring Data na Listagem 5, este vem acompanhado de uma classe de autoconfiguração que irá varrer os pacotes do nosso projeto em busca de interfaces de repositório do Spring Boot.
Com nosso repositório definido, chegou a hora de pô-lo em prática, o que é feito na classe ContatoController, cujo código fonte pode ser conferido na Listagem 7.
@RestController
public class ContatoController {
@Autowired
private ContatoRepository repository;
@RequestMapping(value="/", method=RequestMethod.GET)
public String home() {
return "Cadastro de contatos";
}
@RequestMapping(value="/add", method=RequestMethod.PUT)
public @ResponseBody Contato insert(@RequestBody Contato contato) {
repository.save(contato);
return contato;
}
@RequestMapping(value="/list", method=RequestMethod.GET)
public List<Contato> get() {
List<Contato> result = new ArrayList<Contato>();
Iterator<Contato> iterator = repository.findAll().iterator();
while (iterator.hasNext()) {
result.add(iterator.next());
}
return result;
}
}Programadores que já tenham trabalhado com Spring MVC se sentirão bastante familiarizados com ContatoController, pois não há novidades. É o mesmo modo de trabalho com o qual já estão habituados. Para os leitores que nunca tenham trabalhado com Spring MVC, no entanto, uma rápida introdução se faz necessária.
A anotação @RestController, inserida na declaração da classe, é usada para especificar um tipo especial de bean do Spring: aquele que irá expor uma interface REST do nosso sistema, um controlador, velho conhecido de todos que lidam com o padrão Model-View-Controller (MVC). Apenas @RestController, contudo, não é suficiente. Precisamos também definir quais são as URLs disponibilizadas por esta classe, o que é feito com a anotação @RequestMapping.
@RequestMapping é aplicada sobre as funções presentes no nosso controlador, que possuem um nome especial dentro do “jargão Spring”: actions ou ações. Uma action é apenas isto: um método ou função de um controlador que será responsável por receber o input do usuário sob a forma de uma requisição HTTP, executar alguma lógica presente na camada de negócios do sistema e, em seguida, retornar algum valor para o usuário como uma resposta em algum formato conhecido (HTML, XML, JSON, arquivos binários, etc.). Como estamos lidando com um serviço REST, nosso valor de retorno estará no formato JSON, ou como strings.
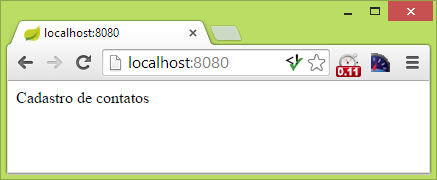
A action mais rudimentar do nosso controlador é home(), que apenas retorna um texto de boas-vindas. A anotação @RequestMapping define que este é, inclusive, o ponto de entrada do aplicativo, ou seja, a URL “/”, relativa ao contexto da nossa aplicação. Portanto, ao iniciarmos a execução do nosso projeto e acessarmos a URL http://localhost:8080/ com um navegador, iremos nos deparar com o resultado exposto na Figura 8.
As coisas ficam mais interessantes quando acessamos a URL http://localhost:8080/list, obtendo o resultado exposto na Figura 9. O que temos é uma lista com dois contatos, representados no formato JSON. Na Listagem 7 podemos ver a action que nos forneceu este resultado. Trata-se da função get(), que nos retorna um objeto do tipo java.util.List que armazena elementos do tipo Contato cuja implementação podemos verificar na Listagem 8.
O funcionamento da função get() é bastante simples. Tudo o que fazemos é chamar a função findAll() do nosso repositório, que nos retorna um objeto do tipo Iterator. Em seguida, extraímos todos os itens do objeto Iterator e os adicionamos à lista, que será retornada pela função. O programador não precisa se preocupar com a transformação do resultado para o formato JSON, pois tudo isso é feito de forma transparente pelo Spring MVC, que usa a biblioteca Jackson, incluída por padrão entre as dependências do Starter POM spring-boot-starter-web.
@Entity
public class Contato {
@Id
@GeneratedValue
private Long id;
@Column(name="nome", length=128)
private String nome;
@Column(name="sobrenome", length=128)
private String sobrenome;
@Column(name="email", length=128)
private String email;
@Column(name="telefone", length=32)
private String telefone;
// getters e setters omitidos
}Voltando à Listagem 7, veremos uma terceira action em nosso controlador: insert. Esta recebe como parâmetro um objeto do tipo Contato, passado para o método save() do nosso repositório. Observe que anotamos o método informando o Boot que esta função seja acionada a partir do método PUT do HTTP que, de acordo com o padrão REST, é o adotado quando desejamos inserir registros na base de dados.
É importante salientar que o endpoint HTTP (URL “/add”), responsável por cadastrar um novo contato, espera dados no formato JSON. Apenas a título de ilustração, na Listagem 9 podemos ver um exemplo de documento que pode ser passado via chamada HTTP para o nosso controlador.
{"nome":"Maria Angelica",
"sobrenome":"Alvares",
"email":"nanna@algo.com.br",
"telefone":"9123-3223"}Finalizada a implementação do nosso microserviço, o próximo passo será implantá-lo em produção. Por padrão, o Spring Boot empacotará nosso projeto como um arquivo JAR, o que é feito executando o comando mvn package na interface de linha de comando do seu sistema operacional, dentro do diretório em que se encontra o código fonte do projeto, gerando o pacote no diretório target do projeto.
Neste arquivo JAR estará contido, além das classes compiladas do projeto, todas as dependências que declaramos no pom.xml. Com isto a implantação se torna bastante direta: basta copiar o pacote para o servidor e executá-lo com o comando java –jar, tal como faríamos com qualquer aplicação Java.
Outra forma de empacotar o projeto é gerando um arquivo WAR que pode ser instalado em praticamente qualquer Servlet Container ou servidor de aplicações. Tudo o que precisamos fazer é alterar o elemento <packaging> do pom.xml tal como fizemos na Listagem 10.
<groupId>javamagazine</groupId>
<artifactId>contatos-internos</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>Feito isso, basta executar o comando mvn package no diretório corrente do projeto que será gerado o arquivo desejado no diretório target. A implantação é feita de acordo com o Servlet container.
Um ponto fundamental no desenvolvimento de qualquer sistema é o modo como este consumirá as configurações necessárias para a sua execução. No caso de uma arquitetura baseada em microserviços esta questão se torna ainda mais importante, pois para garantir a viabilidade do produto precisamos facilitar ao máximo a vida dos administradores responsáveis por garantir a boa execução do nosso código, possibilitando assim que nosso sistema possa ser executado em diferentes ambientes sem a necessidade de recompilação. Ainda mais importante, precisamos que a tarefa de gerenciamento dos parâmetros de configuração seja uma tarefa fácil.
Em um projeto baseado em Spring Boot, as configurações encontram-se essencialmente no formato chave-valor e podem estar armazenadas em diferentes fontes de dados. Para entender como uma informação é obtida nestas diferentes fontes, iremos expor um exemplo trivial buscando uma chave de configuração chamada application.version. Durante o processo de busca, as seguintes fontes serão consultadas:
De acordo com essa lista, se passarmos como parâmetro de linha de comando o valor para a chave application.version e, ao mesmo tempo, tivermos um arquivo application.properties presente no classpath de nosso projeto declarando esta chave de configuração, o valor passado pela linha de comando terá prioridade e será o adotado pelo sistema durante sua execução.
Dado que o objetivo deste artigo é apresentar o Spring Boot e não se aprofundar em seus detalhes, trataremos aqui apenas das fontes de configuração mais comuns: os parâmetros de linha de comando e os arquivos de propriedades. As demais encontram-se suficientemente detalhadas na documentação de referência do Spring Boot, cujo endereço se encontra na seção Links.
A passagem de parâmetros pela linha de comando é bastante direta. Basta utilizar a sintaxe --[chave de configuração]=“valor”.
Com nosso projeto compilado, o comando de exemplo a seguir definiria o valor da chave de configuração application.version com o valor “1.0.0”:
java –jar
lista-contatos.jar –application.version=”1.0.0”No entanto, raras são as situações em que passamos as configurações por linha de comando. Na maior parte das vezes lidaremos com arquivos do tipo chave-valor. Sendo assim, é importante saber como estes arquivos são lidos pelo framework quando nossa aplicação é iniciada. Por padrão, o arquivo de configuração se chama application.properties, e será buscado em diferentes fontes, de acordo com a lista de prioridades exposta a seguir:
Deste modo podemos configurar qualquer módulo baseado em Spring Boot, bastando para isso buscar na documentação relacionada quais as chaves disponibilizadas. Como exemplo, vamos alterar as configurações do módulo Spring Data for JPA. Para isso, primeiro vamos alterar o SGBD. Assim, ao invés de usarmos o padrão (HSQLDB), passaremos a adotar o MySQL. Esta é uma mudança simples de ser realizada e das poucas que requerem dois passos (a esmagadora maioria requer apenas um). O primeiro é incluir no pom.xml do projeto mais uma dependência, que será o driver JDBC do MySQL. O segundo é incluir um arquivo chamado application.properties no mesmo diretório em que formos disponibilizar o arquivo JAR do nosso projeto, forçando assim que as configurações sejam adotadas pelo projeto quando sua execução for iniciada. Na Listagem 11 podemos ver como ficariam nossas configurações para adotarmos o MySQL.
spring.datasource.url=jdbc:mysql://localhost/contatos
spring.datasource.username=usuarioContatos
spring.datasource.password=senhaUsuarioContatos
spring.datasource.driverClassName=com.mysql.jdbc.DriverComo sua aplicação se comporta em produção? Quais as funcionalidades mais acessadas? Como anda o consumo de memória? Quais os beans carregados pelo Spring? Qual o valor daquela chave de configuração mesmo? Quais as threads ativas? Todas estas perguntas (e muitas outras) referentes ao estado de uma aplicação no ambiente de produção são o que chamamos de métricas.
Dado que o esforço na área de administração de sistemas em projetos que adotem a arquitetura baseada em microserviços é maior, métricas são dados cruciais para que possamos adaptar melhor nosso código ao ambiente no qual ele será executado.
Para provermos métricas em projetos baseados no Spring Boot, usamos o módulo Spring Boot Actuator. Este nos fornecerá uma série de métricas pré-prontas e também nos permite criar novas métricas. Sua adoção no projeto é extremamente simples: basta incluir o starter POM spring-boot-starter-actuator no pom.xml do projeto tal como exposto na Listagem 12.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- demais dependências ocultas da listagem -->
</dependencies>Apenas com esta alteração já teremos acesso a uma série de métricas que podem ser visualizadas tanto pelo browser como por JMX. Ao executarmos a aplicação o código de auto configuração do módulo Actuator será executado e disponibilizará uma série de endpoints, cada qual responsável por apresentar informações importantes a respeito do estado da aplicação em tempo de execução. Na Tabela 1 podemos conferir quais são os endpoints fornecidos.
| Identificador | URL | Descrição |
|---|---|---|
| autoconfig | /autoconfig | Lista todas as classes de autoconfiguração do Spring Boot e seus respectivos status. |
| beans | /beans | Lista todos os beans do contexto de IoC do Spring. |
| configprops | /configprops | Lista as configurações definidas por @ConfigurationProperties. |
| dump | /dump | Fornece o estado de todas as threads em execução na aplicação. |
| env | /env | Fornece as variáveis de ambiente usadas pelo Spring. |
| health | /health | Expõe informações sobre a saúde da aplicação. |
| info | /info | Fornece informações arbitrárias da aplicação, que variarão de acordo com os módulos adotados pelo projeto. |
| metrics | /metrics | Fornece informações variadas sobre a aplicação, incluindo as métricas personalizadas que incluirmos no projeto. |
| mappings | /mappings | Expõe todas as URLs mapeadas em nossa aplicação pela anotação @RequestMapping. |
| shutdown | /shutdown | Executa o shutdown da aplicação. |
| trace | /trace | Lista as últimas requisições HTTP feitas à nossa aplicação |
Como podemos notar na Figura 10, ao acessar a URL http://localhost:8080/metrics da nossa aplicação, recebemos como resposta um documento no formato JSON contendo uma série de métricas; a maior parte delas provida pelo próprio Actuator.
Além destas, também é interessante prover nossas próprias métricas. Para demostrar esse recurso, incluiremos duas métricas simples, que nos forneçam quantas vezes os usuários do sistema estão consultando ou inserindo novos contatos na aplicação. O intuito disso é guiar os desenvolvedores na busca por gargalos de desempenho. Para tanto, basta efetuar algumas modificações na classe ContatoController, conforme o código da Listagem 13.
@RestController
public class ContatoController {
// restante da classe omitido
@Autowired
private CounterService counterService;
@RequestMapping(value="/add", method=RequestMethod.PUT)
public @ResponseBody Contato insert(@RequestBody Contato contato) {
counterService.increment("contatos.inclusoes");
// restante da função omitido
}
@RequestMapping(value="/list", method=RequestMethod.GET)
public List<Contato> get() {
counterService.increment("contatos.listagem");
// restante da função omitido
}
}A novidade aqui é a injeção do serviço CounterService. Resumindo, trata-se de uma classe cuja principal função é armazenar valores numéricos que possam ser acessados através de uma chave. Na Listagem 13 usamos apenas o método increment() desta classe. Este recebe como único parâmetro uma chave no formato String. Ao ser invocado, tal método primeiro verificará a existência de um valor numérico identificado pela chave passada como parâmetro. Caso a chave não exista, será criado um valor numérico igual a zero, caso contrário, terá apenas seu valor incrementado e disponibilizado para consulta pelos usuários do sistema.
Na Figura 10 podemos encontrar uma chave chamada counter.contatos.listagem dentre as métricas pré-fornecidas pelo módulo Actuator. Esta é a métrica que incluímos na função get() do nosso controlador.
Apesar das métricas serem um poderosíssimo recurso, estas também abrem algumas brechas de segurança que devem ser levadas em consideração pela equipe de desenvolvimento. O leitor atento irá observar que dentre os endpoints disponibilizados pelo módulo Actuator está um chamado shutdown, que finaliza a execução da aplicação. Além desta opção, usuários mal intencionados também poderiam tirar proveito das métricas com o objetivo de executar um ataque do tipo Denial of Service ou similar em nosso microserviço. A solução para este problema é simples: a inclusão do módulo Spring Security no projeto, também disponibilizado sob a forma de um starter POM. Este irá automaticamente aplicar a restrição às métricas, garantindo que apenas usuários que possuam credenciais possam acessá-las. Infelizmente foge do escopo deste artigo falar sobre o Spring Security, mas dentro da abordagem do Spring Boot, trata-se de um módulo cuja implantação no projeto é um processo bastante fácil.
Caso o leitor releia este artigo notará algo muito interessante: escrevemos pouquíssimo código e nossa única configuração consistiu na inclusão de alguns módulos no arquivo pom.xml do projeto (que poderia muito bem ter sido gerado automaticamente pelo site Spring Initializr)! Claro, devemos descontar o fato de que nossa aplicação é bastante espartana, mas acreditamos que nosso ponto de vista foi claramente exposto: o Spring Boot torna o desenvolvimento de aplicações corporativas uma tarefas ordens de magnitude mais simples.
Agora os desenvolvedores Spring experimentam algo que os programadores Grails já conhecem desde 2007, o poder do conceito de convenção sobre configuração e as vantagens de se ter um framework full stack.
Frameworks full stack são aqueles que nos fornecem uma série de tecnologias que vão desde a camada de visualização (não tratada neste artigo), passando pela camada de negócio, até a integração com bases de dados e outros sistemas já devidamente integradas e configuradas.
Sabemos que uma das maiores vantagens da plataforma Java sempre foi a sua imensa biblioteca de código desenvolvida por terceiros. Isoladamente estas tecnologias nos fornecem imensos ganhos de produtividade, mas, infelizmente, quando precisamos integrá-las, parte destes ganhos se perde no tempo que gastamos fazendo com que todas se comuniquem bem umas com as outras. Através dos starter POMs temos todas as bibliotecas que já estamos acostumados devidamente integradas e prontas para o uso, e se precisarmos customizar o funcionamento do sistema, não precisaremos gastar horas ou dias confeccionando nossas configurações, pois agora podemos alterar apenas o que nos interessa.
É importante salientar também a importância estratégica do projeto Spring Boot para todo o ecossistema Spring. Além de trazer de volta a sensação de inovação a esta plataforma, é também uma nova fundação para outros projetos como, por exemplo, o Grails 3.0.
Quando lançado, o Grails foi visto como um alívio para os programadores que estavam exaustos da burocracia envolvida na escrita de aplicações web para a plataforma Java EE. Podemos dizer que o Spring Boot é a repetição daquele alívio que experimentamos e, ainda mais do que isso, uma experiência revitalizante para aqueles que têm como sua principal linguagem de programação o Java e sentiam uma pontinha de inveja dos programadores Groovy e Ruby.
Enfim, Spring Boot aponta uma nova tendência no desenvolvimento de aplicações corporativas, é algo que todos devem prestar atenção, pois possivelmente novos frameworks que surgirem para a plataforma Java seguirão a mesma direção.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.