Dentre as muitas vantagens que a XML oferece aos desenvolvedores, uma das mais interessantes é o fato de que nćo precisamos “inventar” o nosso próprio código para realizar o processamento de documentos XML. Por exemplo: o desenvolvedor nćo precisa perder tempo inventando uma lógica (algoritmo) para varrer um documento XML, identificando a abertura e o fechamento de tags para assim poder obter o conteśdo texto compreendido entre essas tags. Ao invés disso, os programas que lidam com XML podem fazer uso de bibliotecas especialmente projetadas para processar este tipo de estrutura.
Este artigo aborda uma das mais importantes bibliotecas da XML, denominada SAX (Simple API for XML). O restante do artigo estį dividido da seguinte forma. Na Seēćo 2 explicamos o princķpio de funcionamento da API SAX. A seguir, na Seēćo 3, mostramos apresentamos um exemplo prįtico de utilizaēćo da mesma em um programa Java. Na Seēćo 4, discutimos algumas de suas vantagens e limitaēões. Por fim, na Seēćo 5 apresentamos alguns comentįrios adicionais para quem pretende aprofundar-se em XML e SAX.
O primeiro passo para que vocź possa comeēar a trabalhar com a API SAX consiste em entender o seu princķpio de funcionamento. Uma forma simples de fazer isso é imaginar que programar utilizando a SAX é uma atividade similar a participar de um jogo de pingue-pongue, onde, a cada momento, a bolinha serį rebatida por um dos dois jogadores de cada lado da mesa. Nesse caso, o jogador 1 é o desenvolvedor e o jogador 2 é o processador SAX. Com o auxķlio da Figura 1, explicaremos esse conceito de forma mais clara. Essa figura ilustra a forma com que a API SAX realiza o processamento de um documento XML bem simples.
Figura 1: Documento XML e eventos disparados pelo SAX
O processamento de XML com SAX tem duas caracterķsticas interessantes: (i) produz um laēo automįtico que varre o documento de inķcio ao fim; e (ii) durante esse laēo automįtico, dispara diversos eventos para possibilitar com que o desenvolvedor possa recuperar informaēões contidas no documento XML. Os passos a seguir mostram como funciona esse “jogo de pingue-pongue” entre o desenvolvedor e a API SAX.
Nesta seēćo, apresentamos um programa Java que ilustra a utilizaēćo prįtica da API SAX. O programa realiza o processamento do documento XML com informaēões sobre paķses representado na Listagem 1.
Listagem 1: Documento XML de Paķses
<?xml version="1.0" encoding="ISO-8859-1"?> <paises> <pais sigla="BR"> <nome>Brasil</nome> <moeda>Real</moeda> <populacao>196655014</populacao> </pais> <pais sigla="CA"> <nome>Canadį</nome> <moeda>Dólar canadense</moeda> <populacao>34349561</populacao> </pais> <pais sigla="MX"> <nome>México</nome> <moeda>Peso mexicano</moeda> <populacao>114793341</populacao> </pais> </paises>
O programa Java é apresentado na Listagem 2. A classe DevmediaSAX processa o documento XML com o uso da API SAX, recuperando as informaēões de cada paķs e as imprimindo na tela (usando uma linha para cada paķs). A explicaēćo sobre o funcionamento do programa é apresentada detalhadamente logo após o código.
Listagem 2: Programa Java
import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; /** * classe DevmediaSAX: processa o documento XML de paķses com o uso da API SAX, * recuperando as informaēões de cada paķs e as imprimindo na tela (usando uma * linha para cada paķs). * * A classe "DevmediaSAX" é derivada da classe "DefaultHandler" da biblioteca * org.xml.sax.helpers.DefaultHandler. Isso faz com que "DevmediaSAX" “ganhe” * automaticamente um processador SAX com o comportamento default. * * @author Eduardo Corrźa Gonēalves * */ public class DevmediaSAX extends DefaultHandler { private String tagAtual; private String siglaAtual; /** * construtor default */ public DevmediaSAX() { super(); } /** * Método que executa o parsing: laēo automįtico que varre o documento de * inķcio ao fim, disparando eventos relevantes * * @param pathArq */ public void fazerParsing(String pathArq) { // Passo 1: cria instāncia da classe SAXParser, através da factory // SAXParserFactory SAXParserFactory factory = SAXParserFactory.newInstance(); SAXParser saxParser; try { saxParser = factory.newSAXParser(); // Passo 2: comanda o inķcio do parsing saxParser.parse(pathArq, this); // o "this" indica que a própria // classe "DevmediaSAX" atuarį como // gerenciadora de eventos SAX. // Passo 3: tratamento de exceēões. } catch (ParserConfigurationException | SAXException | IOException e) { StringBuffer msg = new StringBuffer(); msg.append("Erro:\n"); msg.append(e.getMessage() + "\n"); msg.append(e.toString()); System.out.println(msg); } } // os métodos startDocument, endDocument, startElement, endElement e // characters, listados a seguir, representam os métodos de call-back da API // SAX /** * evento startDocument do SAX. Disparado antes do processamento da primeira * linha */ public void startDocument() { System.out.println("\nIniciando o Parsing...\n"); } /** * evento endDocument do SAX. Disparado depois do processamento da śltima * linha */ public void endDocument() { System.out.println("\nFim do Parsing..."); } /** * evento startElement do SAX. disparado quando o processador SAX identifica * a abertura de uma tag. Ele possibilita a captura do nome da tag e dos * nomes e valores de todos os atributos associados a esta tag, caso eles * existam. */ public void startElement(String uri, String localName, String qName, Attributes atts) { // recupera o nome da tag atual tagAtual = qName; // se a tag for "<pais>", recupera o valor do atributo "sigla" if (qName.compareTo("pais") == 0) { siglaAtual = atts.getValue(0); } } /** * evento endElement do SAX. Disparado quando o processador SAX identifica o * fechamento de uma tag (ex: </nome>) */ public void endElement(String uri, String localName, String qName) throws SAXException { tagAtual = ""; } /** * evento characters do SAX. É onde podemos recuperar as informaēões texto * contidas no documento XML (textos contidos entre tags). Neste exemplo, * recuperamos os nomes dos paķses, a populaēćo e a moeda * */ public void characters(char[] ch, int start, int length) throws SAXException { String texto = new String(ch, start, length); // ------------------------------------------------------------ // --- TRATAMENTO DAS INFORMAĒÕES DE ACORDO COM A TAG ATUAL --- // ------------------------------------------------------------ if (tagAtual.compareTo("nome") == 0) { System.out.print(texto + " - SIGLA: " + siglaAtual); } if (tagAtual.compareTo("moeda") == 0) { System.out.print(" - MOEDA: " + texto); } if (tagAtual.compareTo("populacao") == 0) { System.out.println(" - POPULACAO: " + texto); } } /** * Este é o saque inicial do jogo!! Recebe o nome o nome do arquivo XML de * entrada, instancia um objeto da classe DevmediaSAX (myDevSax) e chama o * método “fazerParsing” deste objeto * * @param args * @throws Exception */ public static void main(String[] args) throws Exception { if (args.length != 1) { System.err.println("ERRO: modo de chamar 'PaisesSAX nome_do_xml'"); System.exit(1); } DevmediaSAX myDevSax = new DevmediaSAX(); myDevSax.fazerParsing(args[0]); } }
Para executar o programa, inicialmente salve o arquivo XML de paķses (Listagem 1) em uma pasta de seu computador. Supondo que vocź salvou o arquivo com o nome “paises.xml” na mesma pasta do programa DevmediaSAX, bastarį fazer a seguinte chamada: java DevmediaSAX paises.xml.
A explicaēćo detalhada sobre o o programa é apresentada a seguir:
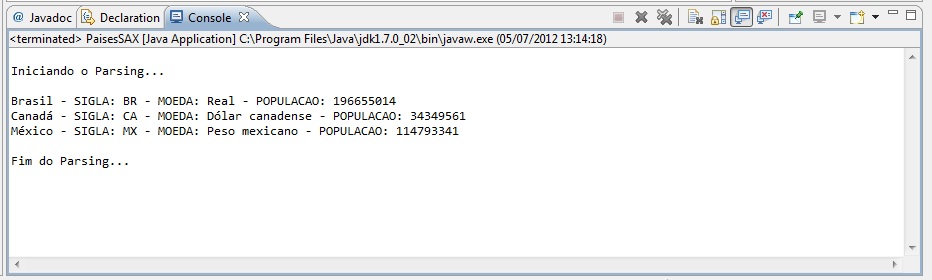
A Figura 2 mostra o resultado da execuēćo.
Figura 2: Resultado da Execuēćo
A principal caracterķstica positiva da API SAX é a sua eficiźncia. É exatamente por esta razćo que ela se tornou a principal API para a manipulaēćo de documentos XML de tamanho grande. Ao contrįrio do que ocorre com a API DOM (outra API clįssica para a manipulaēćo de XML), quando trabalhamos com SAX o documento nćo é importado para a memória. O que é o processador SAX faz é simplesmente implementar um laēo que varre o documento do inķcio ao fim e dispara eventos sempre que um “trecho interessante” do documento é encontrado. O SAX foi exatamente criado com esse propósito: fazer o processamento de XML sem a necessidade de importar os dados para a memória (ou seja, o SAX contorna a deficiźncia que o modelo DOM possui para lidar com documentos muito grandes).
Embora eficiente, o esquema utilizado pelo SAX possui limitaēões. Alguns exemplos: durante o parsing, vocź nćo pode voltar para seēões jį processadas do documento. O processador SAX, em seu loop automįtico, anda apenas para frente. Além disso, a API SAX serve apenas para ler documentos XML e nćo para atualizį-los! Por sua vez, com o uso da API DOM é possķvel navegar em diferentes sentidos do XML e alterar o conteśdo do documento (mudar texto, remover elementos, inserir elementos, etc.). Na prįtica, tanto os modelos SAX e DOM sćo complementares. Dependendo do tamanho do documento e do problema que vocź deseja resolver vocź escolherį uma das duas API’s.
Este artigo apresenta apenas conceitos introdutórios sobre o uso da API SAX em programas Java. Apresentamos simplesmente uma “receita de bolo” para vocź manipular arquivos XML utilizando o modelo SAX. Como quase tudo ligado ą XML, SAX é um tema rico e repleto de conceitos importantes. Alguns exemplos sćo: parsing com validaēćo (uso de DTD’s), tratamento de caracteres especiais no texto (ex: texto com quebra de linha entre tags de abertura e fechamento), uso de namespaces, gerenciamento de exceēões, tratamento de atributos (nosso documento exemplo contém “sigla” como śnico atributo), etc.
As referźncias bįsicas utilizadas para a elaboraēćo deste texto foram as notas de aula da professora Vanessa Braganholo (IC/UFF). A Figura 1 foi adaptada de um exemplo mostrado no artigo “Desmistificando XML: da pesquisa ą prįtica industrial”, de Mirella Moro e Vanessa Braganholo.

Veja os resultado dos nossos alunos
Conquistas reais de quem estį aplicando o método








Utilizamos cookies para fornecer uma melhor experiźncia para nossos usuįrios, consulte nossa polķtica de privacidade.