


Este artigo tem o intuito de desenvolver um sistema de buscas local estilo “Google”, usando um engine conhecido como Lucene.net. Vamos mostrar como indexar algumas informações e posteriormente disponibilizá-las para serem consultadas através de uma interface Web.
Para que serve
O Lucene.net é um framework de indexação de informações das mais diversas fontes e que podem ser disponibilizadas através de consultas, servindo como um poderoso mecanismo para localização rápida de dados, exatamente como os mecanismos de buscas mais modernos vistos atualmente.
Em que situação o tema é útil
Imagine que seu sistema armazene arquivos PDF e seja necessário criar uma busca para o conteúdo desses arquivos. Ou se não for PDF, qualquer outro tipo de arquivo (RTF, XML, Word, HTML, Texto) e até mesmo banco de dados. É possível criar um arquivo indexado e disponibilizá-lo para seus sistemas, assim, de forma similar ao Windows Desktop Search ou Google Desktop Search, será possível localizar por textos, frases, combinações e muito mais.
Resumo do DevMan
O objetivo deste artigo é apresentar o Lucene.net, uma ferramenta que realiza a indexação de arquivos, bem similar ao que o Google Desktop Engine e o Windows Desktop Search fazem. Serão mostrados os conceitos, as principais classes / APIs do Lucene.net e posteriormente vamos colocar em prática seu uso desenvolvendo o exemplo prático. Além de realizar a indexação é possível realizar buscas onde os resultados podem ser ordenados, negritar o texto achado, buscar por palavras aproximadas, fazer pesquisa com a utilização de condicionais lógicas, indexar informações em arquivos que podem ficar alocados tanto no disco quanto na memória, fazer a busca em mais de um índice e muito mais.
O projeto Lucene
O Lucene começou a ser desenvolvido no final de 1997 por Doug Cutting, com a linguagem de programação Java. Em 2000 o projeto Lucene foi lançado no SourceForge, dessa forma os usuários foram apresentados a essa ferramenta de busca, que após um ano da sua divulgação conseguiu vários utilizadores, tornando-se membro do Apache Jakarta (projeto que reúne soluções e frameworks em Java de alta qualidade e colaboração). Dessa forma o projeto ganhou força na sua divulgação e consequentemente por ser Open Source, a colaboração na implementação e melhorias fluíram ao longo dos anos, aumentando a quantidade de colaboradores. Para atender a essa gama de desenvolvedores foi necessário fazer a implementação para outras linguagens de programação, como o C#, Perl, Python e C++.
A Figura 1 mostra em linhas gerais o processo de indexação de texto usado pelo Lucene.net. O motivo de mostrar esse processo é facilitar o entendimento de como é feita a indexação, a procura e ao final, a exibição do resultado para o usuário. Perceba que o texto pode ser extraído de um arquivo HTML, Word, PDF, uma base de dados dentre outras fontes. O mecanismo de extração desse texto fica a cargo do desenvolvedor, pois quando o texto é obtido, o mesmo é repassado ao Lucene.Net para sofrer uma análise.
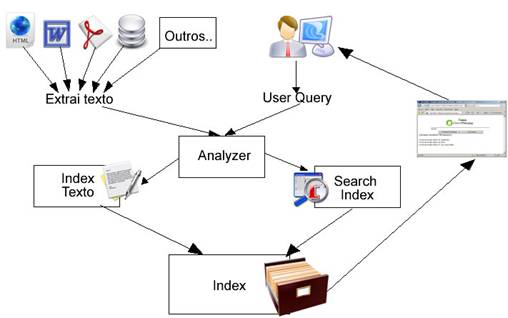
Figura 1. Visão geral da indexação de texto
Analyzer
Antes de criar o índice, que é o local onde informações analisadas estão alojadas, esses dados passam por um processo de análise realizado pelo Analyzer do framework. Esse Analyzer, que nada mais é do que uma classe, pode tratar a informação passada a ele de diversas maneiras, aplicando tipos de análise. Vamos compreender de forma rápida cada uma delas:
...
Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






