


O artigo será útil para o leitor entender os conceitos de paralelismo, analisar planos paralelos, conhecer detalhes do otimizador de consultas, determinar as corretas configurações de uma instância do SQL Server e, naturalmente, ganhar uma sólida base para aplicar em seu ambiente as melhores práticas, fazendo corretamente o troubleshooting ou tuning de consultas paralelas.
Vivemos um período onde os processadores não evoluem mais tão rapidamente a cada novo ciclo de lançamento dos fabricantes. Em contrapartida, encontramos cada vez mais processadores em uma única máquina. Diante disso, é necessário que os programas passem a explorar o paralelismo em seu código, com múltiplas threads em execução, potencializando o uso do hardware à sua disposição.
O paralelismo possui um objetivo muito nobre, que é explorar a concorrência de processamento em um programa com o objetivo de resolver um problema em menos tempo.
Porém, é importante frisar que isto não significa que o uso de recursos será menor, pelo contrário, o tempo total de processamento (uso efetivo das CPUs) tende a ser maior, pois além da execução é necessário incluir no código mecanismos de sincronização das threads.
Atualmente é comum encontrarmos instâncias do SQL Server em servidores com 16, 32 ou mais núcleos (cores) de processamento. Diante desse cenário, é desejável que a engine possa explorar o paralelismo em seu código, ainda mais considerando que o SQL Server é licenciado por núcleo e não por outros fatores como, por exemplo, quantidade de memória.
E mesmo que o código do SQL Server tenha diversos trechos multi-thread, muitos deles não podem ser vistos ou são transparentes para nós, “usuários”. No entanto, existe um deles, assunto cerne deste artigo, onde podemos ver claramente a utilização de múltiplos núcleos de processamento: os planos de execução que possuem operadores paralelos.
Plano de execução paralelo
Definimos um plano paralelo como aquele composto por operadores que exploram o paralelismo em sua árvore de execução. Neste contexto, um conjunto de operadores paralelos é o que determina o que chamamos de zona paralela.
As zonas existem pelo fato do plano de execução nunca ser 100% paralelo, pois sempre o último operador deve ser não paralelo (serial) para que a engine possa retornar os registros da consulta a partir de uma única thread, chamada de coordenadora.
Dito isso, como primeiro exemplo deste artigo, faremos a comparação entre a execução de duas consultas, uma serial e outra paralela, com o intuito de apresentar como são processados os registros em um plano com zona paralela.
O detalhamento de como interpretar um plano de execução e seus operadores está além do escopo do artigo, porém é importante que se tenha o conhecimento do que são e como podem ser gerados através do SQL Server Management Studio. Você encontra um artigo sobre planos de execução na edição 119 da SQL Magazine.
Na Listagem 1 demonstramos uma consulta simples, que conta a quantidade de registros na tabela dbo.bigTransactionHistory fazendo uso da hint “MAXDOP 1”, que força o SQL Server a não utilizar paralelismo para esta consulta. O termo MAXDOP é bastante adotado por ser uma redução de MAX Degree Of Parallelism, ou grau máximo de paralelismo, e também será empregado ao longo deste artigo.
Listagem 1. Consulta simples, sem paralelismo.
USE AdventureWorks2012
GO
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.bigTransactionHistory OPTION (MAXDOP 1);
GOComo pode ser verificado na Figura 1, o plano de execução é simples. O SQL Server opta por percorrer um índice não cluster por completo (index scan), retornando cada um dos registros para ser contabilizado pelo próximo operador (stream aggregate), e por fim devolvendo o resultado para o cliente (o compute scalar não é relevante neste contexto).
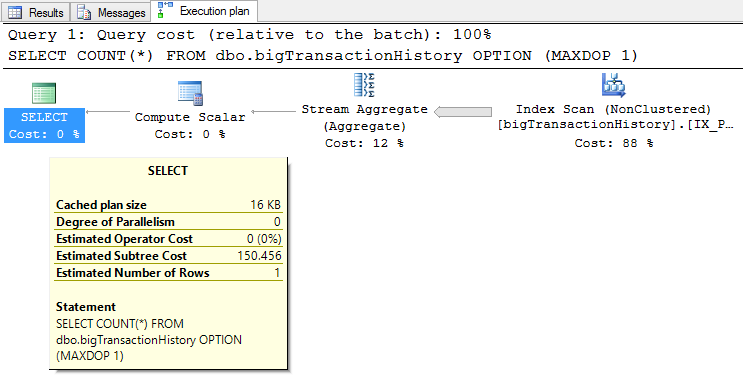
Figura 1. Plano de execução simples, sem paralelismo.
Esse plano de execução tem um custo total de 150.456 e como saída gerada pelo comando SET STATISTICS TIME ON, t ...

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






