O objetivo de um mecanismo de replicação de dados é permitir a manutenção de várias cópias idênticas de um mesmo dado em vários servidores de bancos de dados (SGBD). Os principais benefícios da replicação de dados são a redundância, o que torna o sistema tolerante a falhas, a possibilidade de um balanceamento de carga do sistema, já que o acesso pode ser distribuído entre as réplicas, e finalmente, ter-ser o backup online dos dados, já que todas as replicas estariam sincronizadas. Este artigo, apresenta uma introdução ao mecanismo de replicação do MySQL, bem como as configurações básicas para realização desta tarefa.
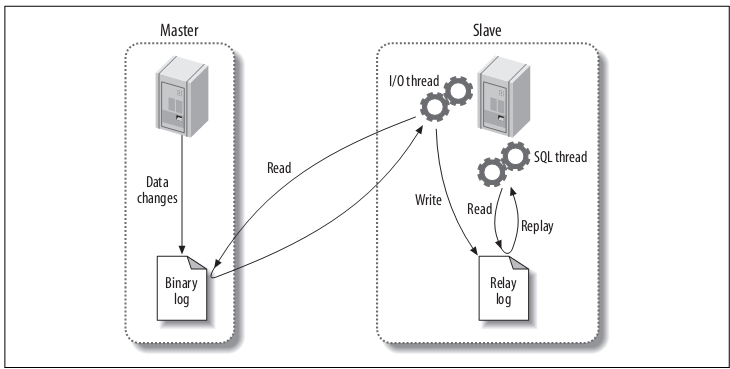
O MySQL permite um tipo de replicação conhecido como Master-Slave, onde temos um servidor atuando como master e um ou mais servidores atuando como slave. O master grava em um log binário de alteração todos os comandos de atualizações da base de dados. Desta forma, todas as alterações ocorridas no master são imediatamente replicadas para os outros servidores slave.
A replicação no mysql é principalmente compatível com a anterior, isto é, um servidor mais novo pode normalmente ser um escravo de um servidor mais velho sem nenhum problema. Porém, versões mais antigas dos servidores são, freqüentemente, incapazes de servir como slaves de versões mais novas, pois eles não podem entender novas características ou a sintaxe SQL que o servidor mais novo utiliza, e pode haver diferenças no formato dos arquivos que a replicação usa, por exemplo, você não pode replicar de um master MySQL 5.0 para um slave MySQL 4.0.
Com a replicação você possui uma série de vantagens como:
O MySQL realiza a replicação em um simples processo de três fases, a Figura 1 ilustra a replicação com mais detalhes:
A configuração do MySQL é bem simples, mas dependendo do cenário pode ocorrer alguma variação. O cenário mais básico é um servidor master e um slave. Basicamente o processo de configuração da replicação é a seguinte:
Obs.: Esta configuração foi feita em duas máquinas virtuais onde as mesmas tinham instaladas o sistema operacional GNU\Linux CentOS 5.7 final. Este artigo parte do principio de que você já tenha instalado o servidor mysql tanto no servidor slave quanto no servidor master.
Primeiramente deve-se criar uma conta de usuário com permissão de replicação para os servidores tanto no master quanto no slave, ou seja, o mesmo usuário criado para os servidores em questão. Aqui está como criar a conta de usuário, que chamaremos de replicador:
mysql> create user replicador identified by ‘replica’;
Query OK, 0 rows affected (0.00 sec)
mysql> grant replication slave, replication client on *.* to replicador@'192.168.56.%' identified by 'replica';
Query OK, 0 rows affected (0.00 sec)Depois de criado as contas o próximo passo é ativar algumas configurações no master. É preciso ativar o log binário e especificar um ID do servidor. Este passo é feito no aquivo de configuração do mysql o “my.cnf” dentro do diretório “/etc”, para isso insira as seguintes linhas no arquivo:
log-bin = mysql-bin
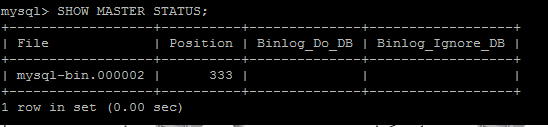
server-id = 1 #pode ser qualquer identificadorDepois de realizado essa configuração no master é preciso reiniciar o mysql para o servidor ativar as configurações e criar os logs binários. Para verificar se o arquivo de log binário está criado no master execute o seguinte comando “SHOW MASTER STATUS” a Figura 2 mostra o resultado desse comando:
Obs: O exemplo que foi citado acima eu tirei o print da tela depois que eu já tinha feito a configuração e já tinha realizado algumas instruções em sql que gerou esse log binário nessa posição. Suponho que você acabou de instalar o mysql e de configurar o master para replicação quando você digitar esse comando na coluna File irá aparecer mysql-bin.000001 e na coluna position o número 98.
Seguindo no processo de configuração da replicação de dados no mysql, o servidor slave precisa ser configurado pelo arquivo de configuração do mysql (my.cnf), para isso insira as seguintes linhas no arquivo:
log-bin = mysql-bin
server-id = 2
relay-log = mysql-relay-bin
log-slave-updates = 1Esta configuração segue o mesmo padrão de configuração do servidor master,porém incluímos alguns parâmetros adicionais: relay-log (para especificar a localização e o nome do relay log) e o log-slave-updates (para fazer o slave logar os eventos replicados no seu próprio log binário.
Obs.: não coloque opções de configuração de replicação como master_host e master_port no arquivo my.cnf do slave, pois esta é uma maneira ultrapassada de configurar e ainda pode causar problemas.
mysql> CHANGE MASTER TO MASTER_HOST='192.168.56.101',
-> MASTER_USER='replicador',
-> MASTER_PASSWORD='replica',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=0;Esta configuração utilizar o usuário e a senha que foi criado no inicio da configuração. O MASTER_HOST é onde colocamos o ip ou nome do servidor master, neste exemplo utilizamos o ip ‘192168.56.191’. O MASTER_LOG_POS é configurado em 0 porque é o inicio do log.
Depois de realizada essa configuração, basta só iniciar o slave executando o seguinte comando:
mysql> START SLAVE;Pronto! A partir de agora a replicação acaba de ser iniciada. Nessa configuração não é para aparecer erros, para verificar se a replicação está funcionando execute o seguinte comando:
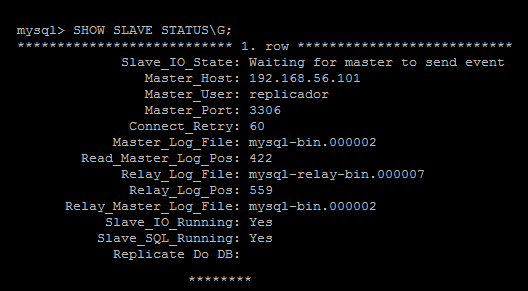
mysql> SHOW SLAVE STATUS\G;Note que a replicação está funcionando perfeitamente, portanto a tudo que for feito no servidor master será replicado para o servidor slave.
Finalizando este artigo espero que todos vocês compreendam a mensagem que eu queria passar qualquer coisa é só entrar em contato comigo.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.