


Grandes massas de dados são geradas diariamente pelos sistemas que apoiam as atividades rotineiras das organizações, dificultando a tarefa analítica dos gestores. Diante dessa necessidade, surgiram os Sistemas de Apoio à Decisão (SADs) que permitem apoiar, contribuir e influenciar no processo de tomada de decisão. Os SADs permitem, a partir dos dados transacionais da organização, gerar informações gerenciais que facilitam o referido processo.
Como grande parte dos dados manipulados pelas organizações está em formato textual, torna-se fundamental o uso da técnica de mineração de texto (também conhecido por Knowledge Discovery in Texts, KDT) para identificar padrões e conhecimentos para auxiliar nas decisões.
O conhecimento gerado pode ser avaliado para determinar se o mesmo é relevante ou não para o usuário, ou seja, avaliar o desempenho do processo de mineração para a geração do conhecimento. Existem várias métricas, sendo as principais relacionadas ao desempenho, à acurácia, precisão e cobertura.
Neste artigo iremos apresentar um estudo de caso realizado em uma organização ABC. A ACB lida com um imenso volume de informações, sendo necessária a utilização de mecanismos que tornem efetivas as atividades de auditoria. Auditoria é a atividade que realiza a validação das informações, verificação da obediência às normas e recomendações e avaliações dos controles em busca dos resultados da gestão. Objetivando atender as necessidades da ABC, desenvolvemos uma aplicação que realiza a mineração de texto em qualquer campo descritivo de um sistema, a ferramenta TextMining.
A aplicação permite determinar se uma descrição é ou não evidência de irregularidade, tornando efetivo o trabalho do auditor na identificação de irregularidades. Para classificar uma descrição, a ferramenta dispõe de um algoritmo, Naïve Bayes, de forma parametrizada, especificando um limiar mínimo para auxiliar no processo classificatório. É importante destacar que existem três métodos para o Naïve Bayes: “Híbrido” (utilização da frequência do termo da amostra com tf, term frequency, da sentença), “Frequência Inversa” (tfidf, term frequency – inverse document frequency, da amostra com tf da sentença) e “Frequência” (frequência da amostra com frequência da sentença).
Este trabalho introduziu um segundo algoritmo, Similaridade, na ferramenta citada e foram avaliadas as métricas de qualidade e desempenho para as duas abordagens. A avaliação se deu por meio da coleta de métricas de tempo médio, acurácia, cobertura, medida F e precisão de cada algoritmo.
Assim, este artigo objetiva comparar o desempenho e qualidade de dois algoritmos de mineração de texto aplicados a históricos de contas públicas custodiadas pela organização ABC. A análise comparativa determinará o melhor algoritmo da ferramenta TextMining e, consequentemente, o conhecimento gerado por essa abordagem será efetivo e relevante para os auditores na descoberta de irregularidades como a identificação de uma descrição de motivo de viagem para a qual não é permitida o pagamento de diárias.
Descoberta de Conhecimento em Bases de Dados
KDD (Knowledge Discovery in Databases) é o processo não-trivial de identificar padrões válidos, novos, potencialmente úteis em dados, ou seja, é o processo de descoberta de conhecimento ou padrões úteis e desconhecidos em grandes massas de dados.
O processo de KDD consiste de várias etapas, as quais envolvem preparação dos dados, busca por padrões, avaliação do conhecimento e refinamento, todos repetidos em múltiplas iterações. Esse processo é composto por cinco passos bem definidos: seleção, pré-processamento, transformação, mineração de dados, análise / assimilação, conforme é mostrado na Figura 1.
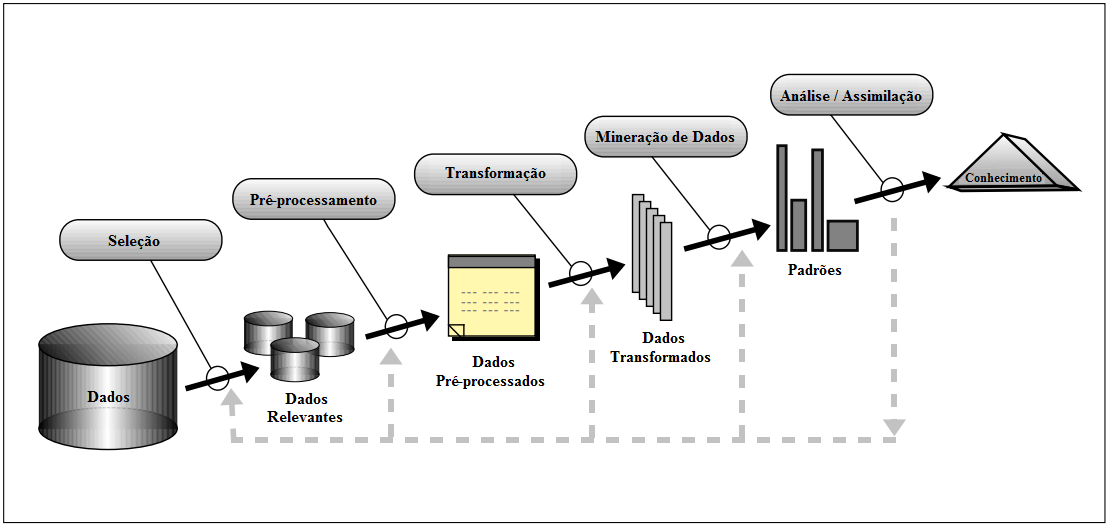
Figura 1. Passos que compõem o processo de KDD.
Na etapa seleção serão definidas as fontes de dados relevantes, ou seja, as bases de dados importantes para o problema em questão, o qual se deseja resolver. No pré-processamento, os dados serão tratados, pois como esses dados podem ser oriundos de diversas fontes, os mesmos podem conter divergência de valores e outras inconsistências. Na transformação, os dados pré-processados serão convertidos para uma estrutura compatível com o algoritmo de mineração escolhido. Já na etapa mineração de dados, objetivo do processo de KDD, é escolhida e executada uma técnica e algoritmo de mineração de acordo com o problema em questão, por exemplo, classificação, regressão, agrupamento e sumarização. E, por fim, na etapa de análise/assimilação, o conhecimento gerado será avaliado se é útil ou não para a tomada de decisão.
Como é mostrado na Figura 1, o processo de KDD é um processo iterativo e interativo, em que o usuário participa e realiza decisões nas diversas etapas do processo, as quais podem também ser repetidas, dependendo do conhecimento gerado ou pela ausência do mesmo.
O processo de KDD pode ser aplicado em diversas áreas, incluindo marketing, finanças, detecção de fraudes, manufaturas e telecomunicações. Um exemplo clássico de utilização de KDD é o conhecimento descoberto nos dados da rede de supermercados Walmart. Foi descoberto que a maioria dos pais que iam comprar fraldas para seus filhos acabavam comprando cerveja. Em uma jogada de marketing, as fraldas foram colocadas próximas da cerveja, sendo que as batatas fritas estavam entre elas. Consequentemente, houve um aumento das vendas dos três produtos.
Outro exemplo de utilização do processo de KDD foi o uso do sistema ADVANCED SCOUT da IBM para ajudar os treinadores da NBA, no ano de 1996, a procurar e descobrir padrões interessantes nos dados dos jogos da NBA. Com esse conhecimento obtido, os treinadores podiam avaliar a eficácia das decisões de táticas e formular estratégias de jogo para jogos futuros. O sistema foi distribuído para dezesseis das vinte e nove equipes da NBA, sendo usado de forma efetiva por algumas equipes para a preparação de jogadas e processos analíticos, como foi o caso do time Seattle Supersonics, o qual atingiu as finais da NBA.
Mineração de Texto
Mineração de texto é o processo de descoberta de conhecimento, potencialmente útil e previamente desconhecimento, em bases de dados desestruturadas, ou seja, extração de conhecimento útil para o usuário em bases textuais.
O processo de mineração de texto é dividido em quatro etapas bem definidas: seleção, pré-processamento, mineração e assimilação, conforme é mostrado na Figura 2.
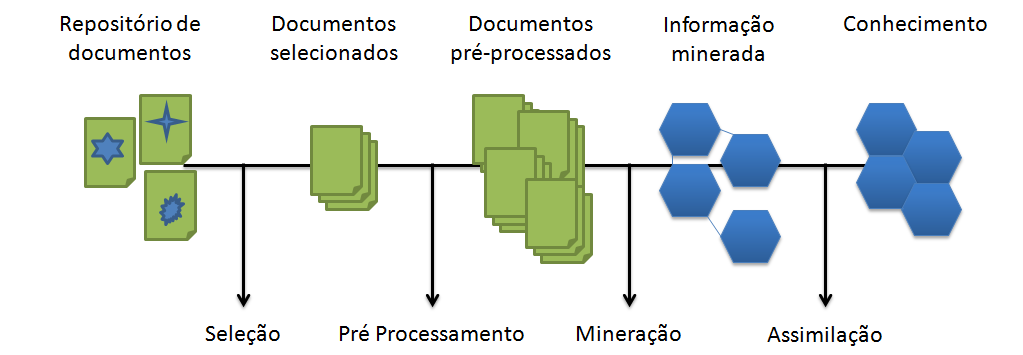
Figura 2. Processo de mineração de texto.
Na seleção, os documentos relevantes devem ser escolhidos, os quais serão processados. No pré-processamento ocorrerá a conversão dos documentos em uma estrutura compatível com o minerador, bem como ocorrerá um tratamento especial do texto. Na mineração, o minerador irá detectar os padrões com base no algoritmo escolhido. E por fim, na assimilação, os usuários irão utilizar o conhecimento gerado para apoiar as suas decisões.
É notório a semelhança entre os processos de KDD e KDT, sendo que o KDT não possui a etapa de transformação. O fato da ausência da etapa transformação, etapa no processo de KDD que converte os dados pré-processados para uma estrutura utilizada na etapa de mineração de dados, é justificada pelo fato de que a etapa de pré-processamento no KDT, além de realizar um tratamento no texto, permite definir uma estrutura compatível com as entradas dos algoritmos de mineração.
A etapa pré-processamento pode ser dividida em quatro subetapas: remoção de StopWords, conflação, normalização de sinônimos e indexação. Na etapa remoção de stopwords os termos com pouca ou nenhuma relevância para o documento serão removidos. São palavras auxiliares ou conectivas, ou seja, não são discriminantes para o conteúdo do documento. São, em sua maioria, pronomes, preposições, artigos, numerais e conjunções. Para auxiliar na remoção das stopwords, geralmente, utiliza-se uma lista destas predefinida. Para facilitar o entendimento, na Figura 3 é apresentado um exemplo de remoção de stopwords.

Figura 3. Exemplo de remoção de StopWords
.Na etapa seguinte, conflação, realiza-se uma normalização morfológica, ou seja, realiza-se uma combinação das palavras que são variantes morfológicas em uma única forma de representação. Um dos procedimentos mais conhecidos de conflação é a radicalização (Stemming). Nela as palavras são reduzidas ao seu radical, ou seja, as palavras variantes morfologicamente serão combinadas em uma única representação, o radical. A radicalização pode ser efetuada com o auxílio de algoritmos de radicalização, sendo os mais utilizados o algoritmo de Porter (Porter Stemming Algorithm) e algoritmo de Orengo (Stemmer Portuguese ou RLSP). A Figura 4 exemplifica o processo de radicalização de um texto utilizando o algoritmo de Porter.

Figura 4. Exemplo de radicalização utilizando o algoritmo de Porter.
Existem dois problemas no processo de radicalização:
· Overstemming: quando a string removida não é um sufixo, mas sim parte do radical da palavra. Isso possibilita a combinação de palavras não relacionadas;
· Understemming: quando parte do sufixo não é removido, ocasionando numa falha de conflação de palavras relacionadas.
Após a conflação, na etapa de normalização de sinônimos, os termos que possuem significados similares serão agrupados em um único termo, por exemplo, as palavras ruído, tumulto e barulho serão substituídas ou representadas pelo termo barulho.
Na normalização de sinônimos, é formado um vocabulário controlado que se refere à utilização de termos adequados para representar um documento, sendo esses termos pré-definidos e específicos a um determinado assunto de uma área. Isso facilita a busca, pois os termos são comumente utilizados pelos usuários da área.
E, por fim, na etapa indexação atribui-se uma pontuação para cada termo, garantindo uma única instância do termo no documento. No processo de atribuição de pesos devem ser considerados dois pontos: (a) quanto mais vezes um termo aparece no documento, mais relevante ele é para o documento; (b) quanto mais vezes um termo aparece na coleção de documentos, menos importante ele é para diferenciar os documentos.
Existem várias formas de determinar o peso de um termo (pontuação). Os principais métodos são:
· Booleano ou Binário: o peso para um determinado termo será 1 se o mesmo aparece no documento. Caso contrário, o peso será 0. Indica a presença ou ausência do termo no documento;
·
Frequência do Termo (term frequency ou tf): o peso é a frequência do termo no documento. Consiste da razão
entre a quantidade de vezes que o termo apareceu no documento e a quantidade
total de termos contidos no documento, como é mostrado na Figura 5, onde ni
é a quantidade de ocorrências do termo i no documento e![]() a quantidade total de termos no documento;
a quantidade total de termos no documento;
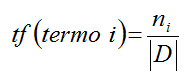
Figura 5. Fórmula para calcular a frequência do termo.
· Frequência do Documento (Document Frequency ou df): é o número de documentos que possui um determinado termo;
·
Frequência
Inversa do Documento (Inverse Document
Frequency ou idf):
refere-se à importância de um termo em um conjunto de documentos. Quanto maior
o idf, mais representativo é o termo
para o documento. Consiste no logaritmo da razão entre o número total de
documentos e a frequência do documento, conforme é demonstrado na Figura 6, onde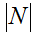 é a
quantidade total de documentos e df(termo
i) a frequência do documento para o termo i;
é a
quantidade total de documentos e df(termo
i) a frequência do documento para o termo i;
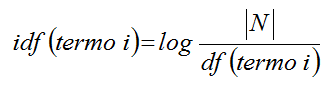
Figura 6. Fórmula para calcular a frequência inversa do termo.
· tfidf (Term Frequency – Inverse Document Frequency): o peso para o termo é associado na proporção da frequência do termo no ...

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






