


Artigo no estilo: Curso
Neste artigo, os arquivos gerados para a mineração de dados (apresentados na primeira parte) serão utilizados em estudos de caso em uma aplicação de algoritmo de clustering e em uma aplicação de algoritmo de classificação.
Caso 1 – Aplicação de Algoritmo de Clustering
O agrupamento ou clustering identifica similaridades entres os valores dos atributos analisados e, a partir dessa análise, particiona a base de dados em grupos. Para a execução da técnica, no estudo de caso, foi selecionado o algoritmo SimpleKMeans que, a partir da indicação da quantidade (k) de clusters desejada, divide a base de dados de forma que a similaridade dos elementos de cada cluster seja alta e, entre os clusters seja baixa.
O arquivo de entrada de dados gerado para essa aplicação, descrito no artigo anterior, foi carregado no WEKA onde algumas análises e considerações foram realizadas sobre a distribuição dos valores dos atributos e seu impacto na atividade. A Figura 1 apresenta as distribuições dos valores de cada atributo da base de dados carregada. Como pode ser observado, os atributos PendenciasAcademicas, PeriodosConcluidos e IndicadorEvasao apresentam apenas um valor, cada, em toda a base utilizada. Dessa forma, não possuem nenhuma interferência na criação dos agrupamentos.
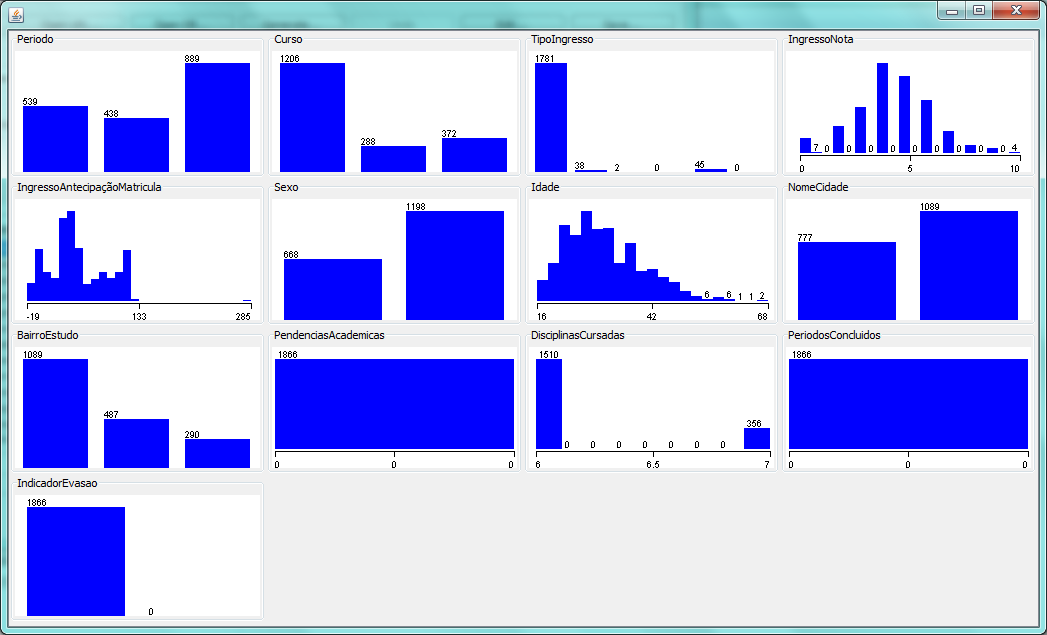
Figura 1. Representação gráfica da distribuição dos valores do arquivo de entrada para o caso 1
O algoritmo simpleKmeans apresenta algumas variáveis de configuração para a sua execução:
· displayStdDevs: indica a exibição de desvios padrão dos atributos numéricos e contagens de atributos nominais. Seu valor padrão é false;
· distanceFunction: determina a função de distância a ser usada para comparação das instâncias. Como padrão, é utilizada a weka.core.EuclideanDistance;
· dontReplaceMissingValues: indica se os valores faltantes devem ser ...

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






