


O artigo é
útil principalmente para estudantes e profissionais de mineração de dados, que
buscam uma ferramenta gratuita para implementação e uso prático de algoritmos
que possam auxiliar na busca de respostas em bases de dados usando mineração.
Autores: Adriano Geraldo Dias Ferreira e Larissa Pereira
A mineração de dados é por definição o método utilizado para a descoberta de conhecimento em grandes bases de dados, convencionais ou não, e faz uso de algoritmos diversos, utilizando estatística e técnicas de inteligência artificial na busca de relações de similaridade ou mesmo discordância entre dados.
O resultado final deste processo tem por objetivo principal descobrir informações relevantes que possam auxiliar os gestores nas suas decisões.
A tarefa de mineração de dados pode ser vista como um processo de exploração e análise, por meio automático ou semiautomático, de grandes quantidades de dados, com o objetivo de descobrir padrões que sejam significativos.
Além disto, o processo de minerar dados possui duas vertentes principais, onde em uma delas se pretende “analisar o passado” e na outra “predizer o futuro”.
A mineração de dados envolve vários objetos de estudo, combinando disciplinas tão diversas quanto estatística, inteligência artificial, aprendizagem de máquina, banco de dados e data warehouse.
Na maioria das vezes, o processo de mineração de dados possui um alto custo de implementação, muitas vezes pelo tamanho do projeto proposto que precisa explorar volumosas bases de dados, acumuladas ao longo dos anos de operação de uma empresa.
O início histórico da mineração de dados acontece a partir dadécada de 90, com sua utilização em pesquisas científicas, com o interesse e crescimento evidenciado mais especificamente a partir de 1997, com cases e ocorrências em grandes atacadistas, no mercado financeiro, governamental e industrial.
Vários têm sido os motivadores para o uso comercial e científico da mineração de dados em diferentes áreas de estudo e mesmo ciências aplicadas.
Na área comercial, o uso da mineração é evidenciado principalmente pelo crescimento no número de dados armazenados pelas empresas. São dados de compras e navegação pela internet, dados de transações bancárias, ou do uso de cartões de crédito. Pode-se considerar também a pressão por competição nas empresas e o barateamento e potência cada vez maior dos computadores.
Para as ciências, a coleta e armazenamento de dados a altas velocidades (Gb/hora) e os resultados da produção científica gerando terabytes de dados, provenientes de telescópios, sensores remotos em satélites, microarrays que podem gerar dados de expressões de genes, sendo que muitas vezes as técnicas tradicionais não são hoje apropriadas para analisar tais dados, gerando ruídos e grande dimensionalidade nos resultados produzidos.
Se forem consideradas as leis, como motivadores para o desenvolvimento desta ciência ainda temos a Lei de Moore e sua capacidade de processamento que dobra a cada 18 meses, em termos de CPU, memória, cachê e a capacidade de armazenamento que dobra a cada 10 meses. Se combinarmos as duas leis (processamento e armazenamento), produziríamos um ‘Gap’ cada vez mais crescente entre nossa capacidade de gerar dados e nossa habilidade de fazer uso eficiente deles.
Um exemplo deste crescimento constante no número de dados armazenados seria o da Biblioteca do Congresso (EUA), que possui aproximadamente 10 terabytes de texto e aproximadamente 3 petabytes (vídeos, áudio, etc.) e isto em pesquisa de 2007. Se considerarmos que a maior parte dos dados no qual falamos nunca foi vista por um ser humano, estes motivadores aumentam mais ainda.
São exemplos de tarefas abordadas em mineração de dados: modelagem preditiva (classificação, regressão), segmentação (clustering), afinidade (sumário/resumo dos dados), relações (entre campos, associação e visualização).
Na maioria dos casos, a mineração tem processo baseado em OLAP (On-Line Analytical Process) e não mais no tradicional SQL (Structured Query Language). São, portanto, etapas de seu processo a seleção e depuração dos dados, transformação dos dados, o próprio processo de mining (Mineração), interpretação, avaliação e por fim, a integração final e resultado.
Estas etapas fazem parte do KDD (Knowledge Discovery in Databases), que será mais bem detalhado no próximo tópico deste artigo.
A mineração e o processo KDD
O termo que representa o processo que transforma dados de baixo nível em conhecimento de alto nível é conhecido como KDD. A mineração de dados é uma das etapas deste processo e que pode ser entendida como a extração de padrões ou modelos de dados observados para avaliação e descoberta de conhecimento.
Para um projeto de mineração eficiente e que consiga produzir conhecimento necessário e utilizável, são necessários cuidados nas diversas etapas compostas pelo processo de descoberta de conhecimento em bases de dados, que descritos em fases seriam:
Fase 1: Definição e compreensão do domínio do problema a analisar. Esta fase representa o processo inicial da definição de objetivos a serem atingidos e deve prever que profissionais que participam da equipe de projeto precisam ter conhecimentos prévios e relevantes sobre o que vai ser tratado e com qual informação irão trabalhar.
Esta é a fase em que se avaliam a viabilidade do projeto a partir da determinação do escopo e custos. Não faz parte das etapas descritas na Figura 1, pois deve acontecer antes do processo de seleção dos dados.
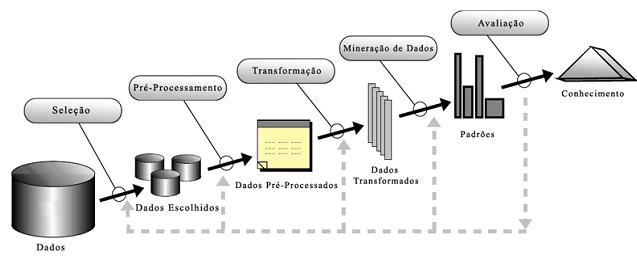
Figura 1. O Processo de KDD
Fase 2: Seleção e Amostragem. Esta é uma fase de extrema importância para o projeto de mineração e requer cuidados extras, já que seria nesta fase que os dados vão ser selecionados para a composição do conjunto de dados, para a criação de nova base de dados ou mesmo para a definição da amostra a ser uti ...

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






