Em que situação o tema é útil
Este tema é especialmente
útil em migrações de dados quando o próprio host atua como movimentador de
dados em cenários diversos, nos quais segurança, tempo e conforto operacional sejam
levados em consideração.
Existem muitas técnicas utilizadas em migrações de dados corporativos, podendo variar desde procedimentos executados no Storage, migrações de dados via Fabric (SAN – Storage Area Network), migrações via Host/Sistema Operacional ou até mesmo via gerenciadores de volume ou aplicação. Cada uma das abordagens repercute em ações e pré-requisitos que devem ser levados em consideração para o sucesso da migração dos dados.
Independentemente da técnica ou da metodologia que será empregada no processo, existe um fator que pode inviabilizar ou impactar o procedimento, que é a circunstância em que o dado se encontra armazenado. Normalmente, muitos administradores começam a planejar ou definir alguns aspectos da migração de dados sem ao menos entender como o dado encontra-se gerenciado e hospedado logicamente.
O dado a ser migrado pode estar sob um gerenciador de volumes como o LVM (Logical Volume Manager), que possibilita migração online, sem impacto para a aplicação, porém o dado também pode estar armazenado em um File System estático (/dev/sda1), significando que haverá necessidade de efetuar uma parada da aplicação em algum momento para gerar a consistência dos dados, de modo que parte do processo ou até mesmo todo ele precise ser executado de forma offline. Em outros momentos o dado também pode estar armazenado em um RAW device e requerer algum procedimento específico na aplicação para ser migrado adequadamente.
Esses e outros pontos importantes que devem ser levados em consideração para realizar uma migração de dados bem sucedida serão abordados neste artigo, cobrindo algumas metodologias adotadas pelo mercado de TI de várias corporações.
O artigo também visa dar ênfase às situações de migração executadas via host, utilizando ferramentas do próprio sistema operacional ou do gerenciador LVM. Em futuros artigos serão abordadas estratégias para migração de dados via Storage ou Fabric (SAN – Storage Area Network), entre outras. Em razão de sua vasta abrangência, o artigo foi dividido em duas partes. Na primeira parte contida nessa edição, o leitor terá contato com o ambiente proposto, sendo este composto por três servidores Linux com alguns File System e Volumes LVM. Cada servidor encontra-se em um cenário característico que viabilizará as estratégias de migração que serão apresentadas no artigo.
Na segunda parte deste artigo, o leitor será apresentado aos procedimentos técnico-operacionais, incluindo os comandos que serão utilizados para migrar os dados de nossos três servidores do ambiente proposto, além de cobrir aspectos de validação de migração de dados e Clean-Up do ambiente envolvido.
Classificação dos dados
Quando pensamos em dados pessoais, não parece uma tarefa tão difícil migrar dados de um dispositivo para outro, porém, quando pensamos em dados corporativos, várias questões entram em jogo, como a janela permitida de downtime do ambiente, SLA contratado, impacto a clientes externos, comunicação, gerência de mudanças, necessidade e tempo de rollback em caso de falhas ou comportamentos não esperados, entre outros fatores que também influenciam a decisão do melhor método para efetuar a migração dos dados. Em muitos desses casos, nem sempre o método inicialmente definido se mostra o mais adequado quando contextualizamos o custo-benefício da estratégia escolhida.
Independentemente da técnica a ser escolhida para migrar os seus dados, o primeiro passo de uma migração bem sucedida consiste em classificar os dados a serem migrados. É necessário compreender questões importantes, como: se os dados encontram-se armazenados em RAW Devices, se estão encapsulados sob algum gerenciador de volumes (LVM), se estão armazenados em File Systems dinâmicos ou estáticos, se são hard partitions, entre outras. Sem esse processo não é possível saber qual técnica pode ser adotada para migrar os dados da forma mais adequada às necessidades do negócio da companhia.
Usar ou não um gerenciador de volumes?
Em linhas gerais, uma das mais importantes tarefas durante a migração de dados ocorre antes mesmo de os dados serem migrados, que seria no momento inicial, quando os dados são armazenados. Algumas perguntas que visam balizar essa dúvida seriam “Qual o melhor File System para armazenar esse tipo de informação, dadas as características do meu dado?” e “Devo utilizar algum gerenciador de Volumes”?
Para simplificar esse entendimento, vamos imaginar que um dado servidor recebeu um novo disco/LUN (Logical Unit Number), sendo este contido em um Storage e conectado ao host através de uma SAN (Storage Area Network). Essa nova LUN pode ser utilizada de várias formas.
Num primeiro momento, podemos entrar no utilitário FDISK, criar uma nova partição do tipo “Linux”, criar um File System nessa partição e montar a nova área em disco da seguinte forma: mount –t ext3 /dev/sdf1 /mountpoint. Esse método é conhecido como Hard Partition e impossibilita migrações de dados online.
Outra possibilidade seria utilizar essa nova LUN sob um gerenciador de volumes, no caso do Linux, o LVM (Logical Volume Manager). Nesse cenário, várias opções de migração de dados online são permitidas, como espelhamento e movimentação de PV (Physical Volumes), que serão abordados mais adiante.
LVM
LVM é uma tecnologia que permite utilizar um disco físico ou LUN de forma mais interessante e atraente, oferecendo melhor nível de aproveitamento do espaço em disco e gestão da área de armazenamento e, consequentemente, garantindo segurança e desempenho oferecendo recursos como espelhamento dos dados (RAID 1) e operações de redimensionamento dinâmico de volumes. Além disso, a utilização de um gerenciador de volumes permite manobras dinâmicas, como migração de dados e movimentação de estruturas lógicas com a aplicação em estado online.
O LVM trabalha com uma unidade primária chamada Physical Extents (PE), normalmente tendo o tamanho inicial de 4 MB. Quando disponibilizamos uma nova área em disco para ser utilizada com LVM, durante o processo de inicialização essa nova área é dividida logicamente em tamanhos iguais (Extents). Quando um novo volume de 10 GB é criado no LVM, este precisa alocar os 10 GB de armazenamento em “x” Extents de 4 MB. Neste caso, esse volume seria composto por 2560 Extents. Em operações como criação ou redimensionamento de volumes, o administrador pode informar o tamanho desejado do volume em Extents (PE) ou em tamanho físico, como Megabytes ou Gigabytes. Adicionalmente, vários comandos LVM mostram as informações na unidade Extents. Deste modo, é interessante que o leitor crie familiaridade com esta unidade para melhor compreensão desses comandos.
Para aqueles leitores que não estão familiarizados com o LVM e precisam utilizar um disco nele, primeiramente é necessário criar um PV (Physical Volume), que numa analogia seria equivalente a uma partição. Esse processo cria a estrutura lógica que permite endereçar o espaço em disco em endereçamentos LVM, conforme o Estágio 1 da Figura 1.
Após essa etapa, é necessário criar o Volume Group (VG), que representa uma estrutura lógica com propósitos de associar um ou mais Physical Volumes (PVs), conforme visto no Estágio 2 da Figura 1. Vamos imaginar que existam dois discos físicos a serem espelhados. Nesse cenário, teremos dois PVs (um em cada disco físico), os quais irão compor um único VG (Volume Group).
Por fim, temos os Logical Volumes (LVOLs), que representam os File Systems que serão criados na estrutura LVM, conforme observado no Estágio 3 da Figura 1. Os LVOLs são criados dentro do VG, que é composto por um ou mais PVs.
Dessa forma, os passos macro para realizar a adição um novo disco no LVM seriam:
· Criar uma partição do tipo 8E (Linux LVM) via FDISK ou outro utilitário;
· Criar um Physical Volume (PV) no disco;
· Adicionar o novo Physical Volume (PV) ao Volume Group (VG);
· Criar um novo Logical Volume (LVOL) no Volume Group (VG).

Figura 1. Etapas para utilização de um novo disco no LVM.
Quando nenhum Gerenciador de Volumes é utilizado
Nesses casos, normalmente trata-se de um File System montado como /dev/sdb1 (Hard Partition) ou um RAW Device. Quando nenhum gerenciador de volumes é utilizado, não é possível executar migrações de dados entre discos/LUNs de forma online por meio de ferramentas do sistema operacional, ou seja, os dados são migrados necessitando de uma parada da aplicação ou serviço.
Existem algumas soluções e produtos comerciais pagos que permitem o processo online, porém, em linhas gerais, nessa situação é necessário gerar um ponto de consistência dos dados, normalmente o umount do File System ou parada da aplicação, traduzindo-se em um processo offline. Ademais, algumas aplicações como bancos de dados com propósitos comerciais têm recursos que permitem a migração de dados online, mesmo que os dados não se encontrem hospedados em algum gerenciador de volumes.
Em alguns casos, o dado pode estar armazenado em um RAW device utilizado por um banco de dados, como o Sybase, Oracle, entre outros. Nesses casos, existem ferramentas do próprio banco de dados que podem permitir a migração online, no entanto, via sistema operacional, quando os dados não estão encapsulados sobre algum gerenciador de volumes, o processo de migração de dados ocorre de forma offline.
Outro ponto interessante é que preferencialmente devem ser escolhidos File Systems dinâmicos para armazenar os dados. File Systems dinâmicos são aqueles que permitem operações de Grow (expansão) e Shrink (redução) de forma dinâmica, ou seja, com a aplicação em estado online. Em casos menos comuns, porém não menos importantes, a LUN origem é maior que a LUN destino, podendo ser necessário executar operações de Grow ou Shrink antes de migrar os dados.
Quando algum Gerenciador de Volumes é utilizado
Nesses casos, normalmente é um Logical Volume (LVOL) pertencente a algum Volume Group (VG) LVM. Esse volume pode ser utilizado como File System ou RAW device. Essa situação é um dos cenários mais interessantes de se trabalhar quando se objetiva disponibilidade e conforto operacional, pois manobras como espelhamento, migração de PV (Physical Volumes LVM), entre outras, podem ser utilizadas sem necessidade de efetuar parada da aplicação. Quando optamos por utilizar algum gerenciador de volumes, a migração ocorre na camada do gerenciador, ou seja, uma operação Block Level. Já quando não utilizamos um gerenciador de volumes, a cópia ocorre em cenário File Level, ou seja, é influenciada pela quantidade de arquivos e diretórios existentes no File System, e a princípio é menos performática, pois mais camadas devem ser acessadas para chegar até o dado (LVM e File System). A Nota DevMan 1 traz mais detalhes sobre as operações Block Based e File Based.
As operações Block Based se comportam como cópias de RAW Devices por meio do comando DD. O tempo de cópia não é influenciado pela quantidade de arquivos a serem migrados. A ferramenta utilizada na cópia requisita os blocos existentes nos volumes origem e os copia para os volumes destino.
Já as operações File Based são influenciadas pela quantidade de arquivos existentes no sistema de arquivos a ser migrado. A ferramenta utilizada na cópia requisita os arquivos existentes no sistema de arquivos origem e os copia para o sistema de arquivos destino.
Para melhor compreensão do leitor entre a diferença prática entre operações Block Level e File Level, imagine um File System de 10 GB com 232 milhões de arquivos muito pequenos na casa de alguns poucos Bytes, como é muito comum nos ambientes de Telecom (arquivos CDR).
Podemos afirmar certamente que em uma migração Block Level o processo levaria alguns minutos, enquanto que numa cópia File Level o processo certamente levaria algumas horas, pois os 232 milhões de ponteiros dos File Systems, que na verdade referenciam arquivos e diretórios, precisam ser traduzidos para posições físicas de disco. Nos dois casos, são apenas 10 GB a serem migrados. Não é incomum que administradores já tenham vivenciado experiências de migrações de dados em que alguns poucos Gigabytes de informação demoraram mais de um dia para serem migrados via operação File Level devido à baixa taxa de transferência (Throughput) de cópia, parametrização indevida de File System, opções de montagem impróprias para necessidades da aplicação, entre outras situações.
Nas operações Block-Level, não importa se o dado se encontra hospedado em um RAW device ou um File System de 232 milhões de arquivos. A única informação que importa é a volumetria a ser migrada, ou seja, os zeros (0) e uns (1) armazenados em disco. O tempo de cópia não sofre influência da quantidade de arquivos existentes.
Cabe ressaltar que também existem alguns gerenciadores de volumes comerciais voltados ao segmento Datacenter que oferecem outros recursos mais avançados direcionados ao ambiente Enterprise. Alguns produtos muito utilizados em ambiente Linux são o Oracle ASM (Oracle Automatic Storage Management), Symantec Storage Foundation, entre outras soluções interessantes.
Multipathing
Uma situação muito comum em ambientes corporativos e SAN de porte Enterprise é a utilização de algum software de Multipathing nos sistemas operacionais para acesso dos servidores ao Storage onde o dado reside. A Nota DevMan 2 traz mais detalhes sobre a tecnologia Multipathing.
Multipathing é uma tecnologia utilizada quando existe mais de uma controladora ou caminho de acesso a um disco/LUN. Neste caso, um mesmo dispositivo pode ser visto e reconhecido pelo sistema operacional por dois ou mais caminhos de acesso, /dev/sda e /dev/sds, por exemplo. Porém, para que o sistema operacional tire proveito da redundância dos múltiplos caminhos de acesso de um disco, é necessário configurar algum software de multipath no sistema operacional.
Existem softwares freeware e outros proprietários distribuídos pelo fabricante do Storage. Cada um oferece vantagens específicas a cada uma das necessidades do negócio.
A utilização de Multipathing faz sentido quando o sistema operacional reconhece os discos/LUNs por mais de um caminho lógico. Em ambientes de alta disponibilidade é comum encontrar servidores com duas ou mais controladoras Fiber Channel (HBAs) e o Storage possuir mais de uma controladora também. Neste cenário, um único disco/LUN é reconhecido em nível de sistema operacional por mais de um caminho lógico. Exemplo: /dev/sdb, /dev/sdc, /dev/sdd e /dev/sde.
Até então, se nenhum software de Multipathing for utilizado, na prática, a redundância de acesso ao disco não existe. O efeito prático para o sistema operacional é como se houvessem quatro discos diferentes com um único caminho de acesso, em vez de um único disco com quatro caminhos de acesso.
A tecnologia de Multipathing permite que o sistema operacional possa “entender” que existem vários caminhos de acesso a um mesmo disco físico. Existem softwares nativos de cada sistema operacional e também softwares proprietários em caso de fabricantes que comercializam Storages de médio e grande porte, como HP, EMC e Hitachi. Cada um com comandos, procedimentos e requisitos muito específicos.
Cada modelo de Storage permite ou não características como balanceamento de carga no acesso aos dados que possibilitam trabalhar de forma ativa/ativa quando há mais de uma controladora para acesso aos discos. Também existem modelos de Storage que possuem duas controladoras, porém estas funcionam somente em regime ativo/passivo, ou seja, a segunda controladora só é utilizada em situações de falha da primeira controladora.
Dessa forma, o software de Multipathing somente pode trabalhar nas configurações suportadas pelo modelo do Storage em questão, variando normalmente de forma macro em ativa/ativa ou ativa/passiva, sendo possível parametrizar esse tipo de acesso ao disco normalmente nas seguintes variantes:
· Round Robin: Modalidade em que todas as requisições de I/O são distribuídas entre os possíveis caminhos de acesso ao dado. O acesso 1 é feito por meio da controladora 1, o acesso 2 é feito por meio da controladora 2, o acesso 3 por meio da controladora 1, o acesso 4 pela controladora 2, e assim por diante;
· Preferred: Nessa modalidade, todas as requisições de I/O são direcionadas a uma controladora que o administrador define como preferencial. A segunda controladora só é utilizada em caso de falha da primeira;
· Custom: Modalidade específica do fabricante do Storage em função da tecnologia utilizada. Alguns fabricantes oferecem em seus softwares de Multipathing recursos como verificação de latência e tempo de resposta de acesso ao disco/LUN, ou seja, o caminho que responder com menor latência (mais rápido) é o utilizado para acessar a informação. Já existe outra modalidade customizada em que a carga de consumo da controladora é verificada. A controladora do Storage que estiver com menor consumo atende às requisições de I/O. Existem inúmeros outros algoritmos de balanceamento de carga variando de fabricante para fabricante com os mais diferentes propósitos, como beneficiar o processo de escrita ou de leitura, bem como privilegiar o acesso sequencial ou randômico aos dados.
Para melhor compreensão didática, os aspectos de Multipathing não serão abordados em detalhes nesse artigo, pois, em função do fabricante ou tecnologia que o leitor dispuser, os comandos requeridos podem mudar de forma que dificultaria a compreensão técnico-didática desse artigo. Cada fabricante mantém sua própria documentação, além de existirem diversas outras fontes e artigos na Internet sobre o assunto Multipathing. A tecnologia Multipathing será abordada em detalhes em futuros artigos da Infra Magazine.
Vale lembrar aos leitores menos experientes que LVM (Logical Volume Manager) não deve ser associado a Multipathing. É possível utilizar Multipathing e não utilizar LVM, por exemplo. Fazendo uma analogia, Multipathing está relacionado à forma ou modo de acesso físico ao dado, ao passo que o LVM está relacionado à forma lógica como o dado é armazenado em disco.
Cenário de testes
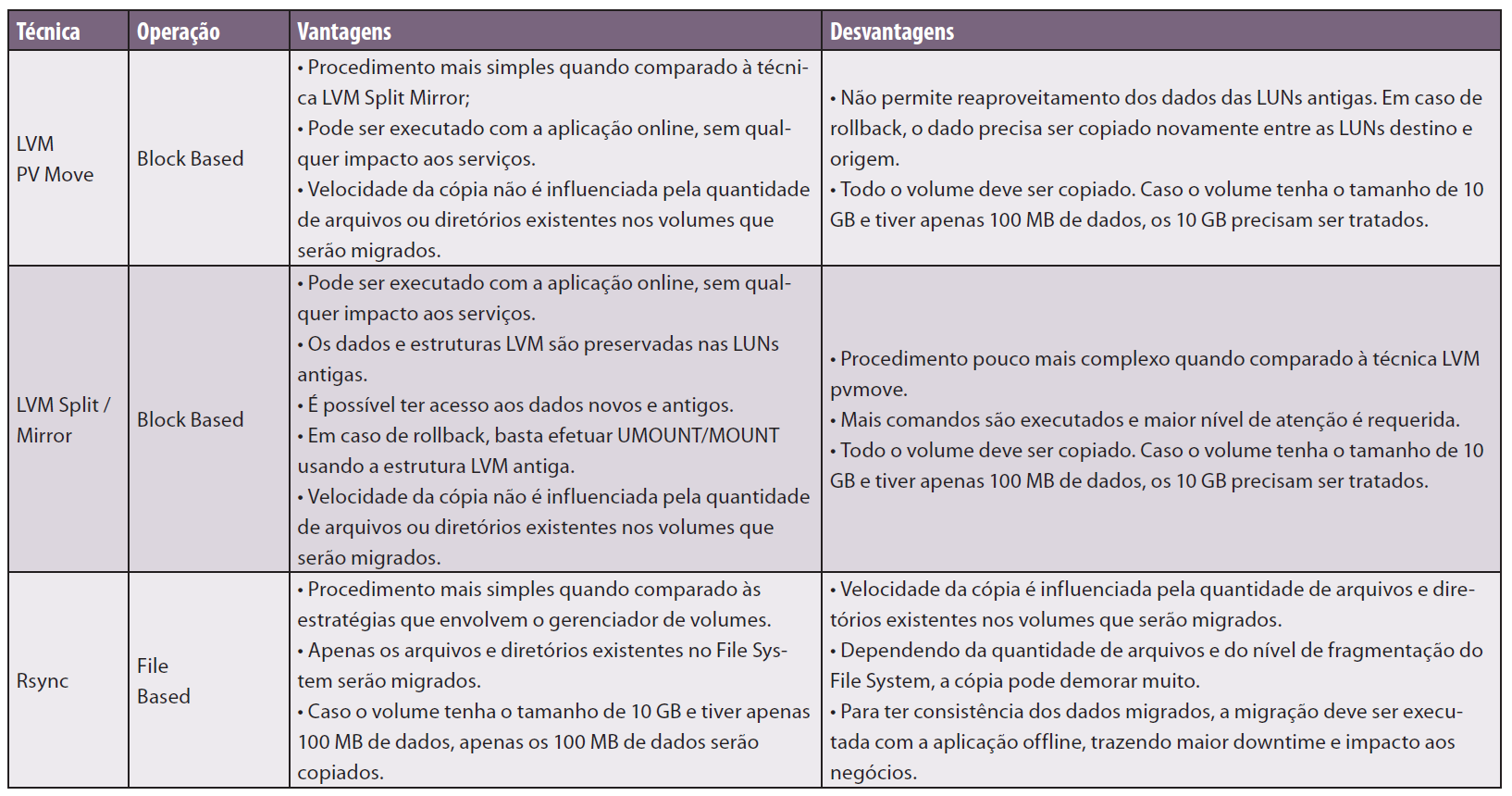
Para elaboração desse artigo, vamos imaginar que nosso ambiente a ser migrado seja composto de três servidores Linux, com os hostnames RJOSRVUUXX01, RJOSRVUUXX02 e RJOSRVUUXX03, respectivamente. Cada host tem seus dados armazenados de uma forma peculiar que será avaliada e terá um método de migração próprio a ser definido adiante, no decorrer do artigo. A Figura 2 ilustra de forma macro o cenário que será tratado nos próximos passos do artigo.
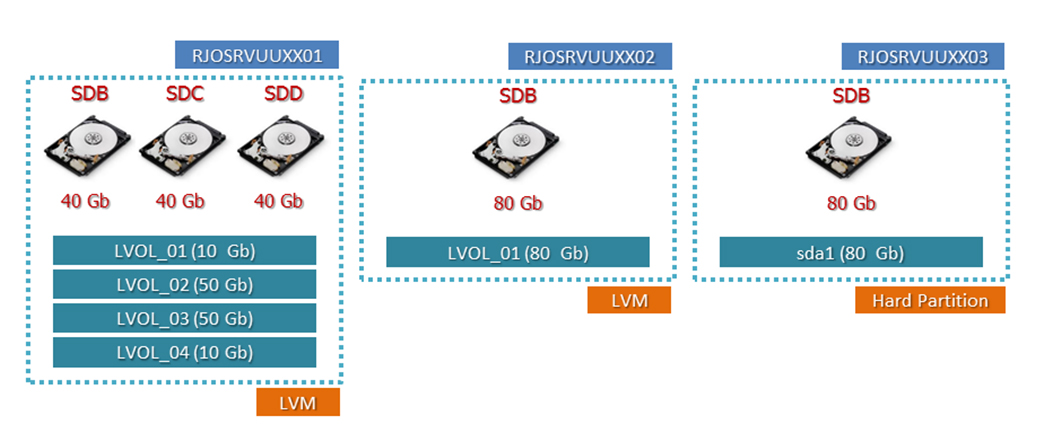
Figura 2. Dados a serem migrados.
Para obtermos as informações necessárias que viabilizem a avaliação de como os dados encontram-se hospedados nos hosts e Sistemas Operacionais envolvidos, é necessário executar comandos específicos do gerenciador de volumes ou do sistema operacional, conforme será explicado adiante.
Para cada um dos casos a serem analisados, pode ser necessário executar comandos específicos mediante o resultado obtido na análise inicial. Quando os dados estiverem sob gerência do LVM, será necessário avaliar outputs de comandos como pvdisplay, lvdisplay ou vgdisplay. Já em situações em que os dados estejam hospedados em hard partitions (/dev/sda1), não é necessário avaliar os comandos LVM, apenas os comandos específicos do sistema operacional. Por isso a etapa de levantamento é muito específica e peculiar a cada ambiente.
Mapeamento do servidor RJOSRVUUXX01
Na Listagem 1, temos todos os passos associados com o mapeamento do servidor RJOSRVUXX01, que tem seus File Systems a serem migrados sob gerência do LVM (Logical Volume Manager). Como pode ser observado, serão executados comandos específicos de LVM para efetuar o mapeamento dos dados a serem migrados.
Para facilitar a compreensão da sequência de comandos exibida na Listagem 1, a dividimos em várias partes e agora explicaremos cada uma separadamente:
1. Conforme observado na Figura 2, o host RJOSRVUXX01 tem seus File Systems a serem migrados sob gestão de um gerenciador de volumes. Vamos então documentar o cenário no qual iremos trabalhar. Para realizar o mapeamento dos dados é necessário associar cada File System que será migrado com seu respectivo LVOL (Logical Volumes). Utilizando o comando df –h ou outro de sua preferência, verifique os LVOLs e seus respectivos Mount Points e VGs (Volume Groups).
Como exemplo, a primeira linha do comando df –h mostra que o LVOL lvol_01, pertence ao Volume Group (VG) db_vg e está montado no diretório /srv/db/MYDB. Tome nota dos demais LVOLs.
Em negrito, encontram-se relacionados os nomes dos LVOLs que serão migrados (lvol-01, lvol-02, lvol-03 e lvol-04) juntamente com os atuais Mount Points desses volumes (/srv/db/MYDB, /srv/db/data01, /srv/db/indx01 e /srv/db/arch);
2. Por meio do comando pvs, verifique quais PVs (Physical Volumes) fazem parte do VG db_vg. Em nosso caso, /dev/sdb1, /dev/sdc1 e /dev/sdd1, conforme as marcações em negrito. Além disso, também repare que cada um desses PVs a serem migrados possui 40 GB. Essa informação será utilizada mais adiante no artigo. Até o presente momento, foram mapeados quatro LVOLs hospedados em três PVs;
3. Conforme o comando anterior, todos os PVs já estão devidamente mapeados. Agora vamos registrar como esses PVs encontram-se do ponto de vista físico, ou seja, qual a controladora, target e LUN desses PVs. Essa informação pode ser utilizada em caso de Rollback, além de dar uma visão da distribuição física dos discos/LUNs entre os barramentos e os controladores existentes no servidor.
Utilizando o utilitário lsscsi (nem sempre instalado por padrão), verifique as LUNs que farão parte da migração e registre o caminho físico associado com cada LUN. Observe os device paths marcados em negrito. Nesse caso, temos o disco físico /dev/sdb associado ao device path 1:0:0:0. O disco /dev/sda não está marcado porque é a área de Boot do servidor;
4. Conforme explicado inicialmente nesse artigo na seção LVM, o LVM trabalha com o conceito de Extents. Portanto, é importante registrar não só o tamanho dos PVs em GB, mas também seu tamanho em Extents (áreas de 4 MB). Essa informação será útil na criação dos volumes em um momento futuro. Assim, por meio do comando PVDISPLAY, verifique a atual parametrização e quantidade de Extents alocados para os PVs.
Nesse caso temos os PVs /dev/sdb1, /dev/sdc1 e /dev/sdd1, cada um com 10239 Extents, o que representa 40 GB. Também podemos ver que os Extents (PE) são de 4 MB.
Em alguns casos muito específicos, aplicações Enterprise, visando obter melhor desempenho nas operações de I/O, recomendam alterar o valor default do tamanho dos Extents. Esta configuração pode ser feita no momento da criação das estruturas LVM. A princípio, o tamanho inicial de 4 MB atende muito bem qualquer aplicação. Em nosso caso, os PVs têm Extents de 4 MB;
5. Verifique se todos os LVOLs foram devidamente mapeados ou se faltou algum. Até então nos baseamos na saída do comando df –h, que não é o melhor método. Poderiam existir LVOLs não montados, ou então os LVOLs poderiam ser RAW devices que não apareceriam na saída desse comando.
O comando adequado para o mapeamento é o lvs, que mostra todos os Logical Volumes (LVOLs) existentes no VG (Volume Groups) db_vg. Ao executá-lo, podemos notar que todos os quatro Logical Volumes (lvol_01, lvol_02, lvol_03 e lvol_04) foram devidamente mapeados.
Note também que os Logical Volumes têm respectivamente 10 GB, 50 GB, 50 GB e 9,98 GB de tamanho;
6. Como já vimos anteriormente, o LVM trabalha com o conceito de Extents (áreas de 4 MB), de forma que é muito importante sempre registrar o tamanho das estruturas LVM não em tamanho (GB ou MB), por exemplo, mas em Extents. Assim, em momentos de migração de dados, ao utilizar os tamanhos em Extents, sempre garantimos que as novas estruturas LVM serão migradas consistentemente do ponto de vista físico de volumetria.
Dando continuidade à fase de levantamento de informações, através do comando lvdisplay, verifique a atual parametrização e quantidade de Extents dos LVs. Podemos observar que o lvol_01 tem 2560 extents, o lvol_02 tem 12800 Extents, o lvol_03 também possui 12800 Extents, e, por fim, o lvol_04 tem 2555 Extents. Essa informação pode ser útil em momentos de Rollback e criação de volumes, sendo importante para efeitos de planejamento e organização dos dados que serão migrados.
Listagem 1. Sequência de comandos para mapeamento do host RJOSRVUXX01.
########## Trecho 1 ##########
sysadmin@rjosrvuuxx01:~$ df -h | tail -4
/dev/mapper/db_vg-lvol_01 9.9G 4.5G 5.4G 45% /srv/db/MYDB
/dev/mapper/db_vg-lvol_02 50G 22G 28G 44% /srv/db/data01
/dev/mapper/db_vg-lvol_03 50G 22G 28G 44% /srv/db/indx01
/dev/mapper/db_vg-lvol_04 9.9G 8.1G 1.8G 82% /srv/db/arch
########## Trecho 2 ##########
sysadmin@rjosrvuuxx01:~$ sudo pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 db_vg lvm2 a- 40.00g 8.00m
/dev/sdc1 db_vg lvm2 a- 40.00g 0
/dev/sdd1 db_vg lvm2 a- 40.00g 0
########## Trecho 3 ##########
sysadmin@rjosrvuuxx01:~$ lsscsi --size
[0:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sda 8.58GB
[1:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdb 42.9GB
[2:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdc 42.9GB
[3:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdd 42.9GB
########## Trecho 4 ##########
sysadmin@rjosrvuuxx01:~$ sudo pvdisplay /dev/sdb1 /dev/sdc1 /dev/sdd1
--- Physical volume ---
PV Name /dev/sdb1
VG Name db_vg
PV Size 40.00 GiB / not usable 3.00 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 10239
Free PE 2
Allocated PE 10237
PV UUID LWfb6K-5Za8-5X1n-3CD4-iTmw-N126-s4bUI3
--- Physical volume ---
PV Name /dev/sdc1
VG Name db_vg
PV Size 40.00 GiB / not usable 3.00 MiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 10239
Free PE 0
Allocated PE 10239
PV UUID rIe6sc-zB55-90Fq-KN0f-kem0-J17a-KitlgB
--- Physical volume ---
PV Name /dev/sdd1
VG Name db_vg
PV Size 40.00 GiB / not usable 3.00 MiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 10239
Free PE 0
Allocated PE 10239
PV UUID XnttFc-mMLh-il7g-VelV-yVVd-Hqsy-F4X456
########## Trecho 5 ##########
sysadmin@rjosrvuuxx01:~$ sudo lvs db_vg
LV VG Attr LSize Origin Snap% Move Log Copy% Convert
lvol_01 db_vg -wi-ao 10.00g
lvol_02 db_vg -wi-ao 50.00g
lvol_03 db_vg -wi-ao 50.00g
lvol_04 db_vg -wi-ao 9.98g
########## Trecho 6 ##########
sysadmin@rjosrvuuxx01:~$ sudo lvdisplay /dev/db_vg/lvol_0*
--- Logical volume ---
LV Name /dev/db_vg/lvol_01
VG Name db_vg
LV UUID qRY5U9-DiYo-YyCC-meP7-DkQd-7dy9-Wndqk9
LV Write Access read/write
LV Status available
# open 1
LV Size 10.00 GiB
Current LE 2560
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:2
--- Logical volume ---
LV Name /dev/db_vg/lvol_02
VG Name db_vg
LV UUID rvCeKG-UdyT-MmaT-xCv3-LnQe-2r35-s5hOuG
LV Write Access read/write
LV Status available
# open 1
LV Size 50.00 GiB
Current LE 12800
Segments 2
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:3
--- Logical volume ---
LV Name /dev/db_vg/lvol_03
VG Name db_vg
LV UUID zlMppE-6LpI-sE4V-XMvO-etZs-zzoQ-CvymTE
LV Write Access read/write
LV Status available
# open 1
LV Size 50.00 GiB
Current LE 12800
Segments 2
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:4
--- Logical volume ---
LV Name /dev/db_vg/lvol_04
VG Name db_vg
LV UUID KfMVnC-SSw4-2JQT-mIgv-VLH5-pGG1-J32CFL
LV Write Access read/write
LV Status available
# open 1
LV Size 9.98 GiB
Current LE 2555
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:5Baseado nos dados obtidos na execução dos procedimentos da Listagem 1, concluímos a fase de mapeamento do servidor RJOSRVUXX01 e consolidamos as informações coletadas, conforme observado na Figura 3.
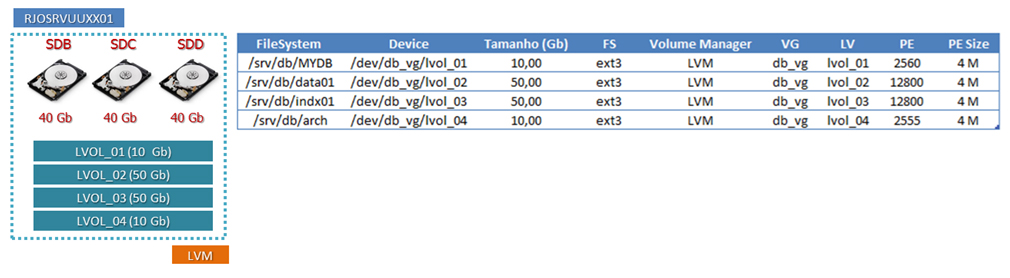
Figura 3. Dados a serem migrados do servidor RJOSRVUUXX01.
Mapeamento do servidor RJOSRVUUXX02
Na Listagem 2, temos todos os passos associados com o mapeamento do servidor RJOSRVUXX02, que possui um único File System a ser migrado sob gerência do LVM. Como pode ser observado, serão executados comandos específicos de LVM para efetuar o mapeamento dos dados que serão migrados.
Para facilitar a compreensão da sequência de comandos exibida na Listagem 2, a dividimos em várias partes e agora explicaremos cada uma separadamente:
1- Conforme observado na Figura 2, o host RJOSRVUXX02 também possui seus File Systems sob gestão de um gerenciador de volumes. Para concluir a etapa de levantamento dos dados, é necessário associar cada File System que será migrado com seu respectivo LVOL. Utilizando o comando df –h ou outro de sua preferência, verifique os LVOLs e seus respectivos Mount Points e VGs.
Podemos notar que existe apenas o lvol lvol_01 associado ao Mount Point /srv/app;
2- Agora vamos documentar os PVs responsáveis por armazenar o lvol-01 por meio do comando pvs. Notamos que o VG app_vg só possui um PV (/dev/sdb1), de 80 GB;
3- Nesse momento, o único PV já está devidamente mapeado. Agora vamos registrar como esse PV encontra-se do ponto de vista físico, ou seja, qual a controladora, target e LUN do mesmo. Essa informação pode ser utilizada em caso de Rollback e oferece uma visão clara da distribuição física dos discos/LUNs entre os barramentos e controladores existentes no servidor.
Utilizando o utilitário lsscsi, verifique o caminho físico da LUN que será migrada. Neste caso temos o disco físico /dev/sdb associado ao device path 1:0:0:0. O disco /dev/sda não está marcado em negrito, pois é a área de Boot do servidor;
4- Por meio do comando pvdisplay, observe o número de Extents (áreas de 4 MB) associado ao PV /dev/sdb1. Podemos notar que ele apresenta 20479 Extents. Para efeitos de planejamento de migração, é muito importante registrar essa informação, que além de poder ser útil em caso de Rollback, ajuda a ter uma visão clara sobre os PVs que estão sendo tratados durante processo de migração de dados;
5- Até o presente momento utilizamos o comando df –h para verificar os LVOLs que serão migrados. Porém, podemos ter mais algum LVOL não montado ou um raw device, por exemplo, que não seria identificado por esse comando. Dessa forma, verifique se todos os LVOLs foram mapeados ou se faltou mais algum utilizando o lvs.
Com isso podemos confirmar que no VG app_vg só existe o lvol_01 com o tamanho de 79,90 GB;
6- Agora, por meio do comando pvdisplay, vamos observar a atual parametrização do LVOL lvol-01 e sua quantidade de Extents. Essa informação será utilizada mais adiante no artigo. Podemos observar que o lvol_01 possui 20455 Extents (em áreas de 4 MB).
Listagem 2. Sequência de comandos para mapeamento do host RJOSRVUXX02.
########## Trecho 1 ##########
sysadmin@rjosrvuuxx02:~$ df -h | tail -1
/dev/mapper/app_vg-lvol_01 79G 54G 25G 68% /srv/app
########## Trecho 2 ##########
sysadmin@rjosrvuuxx02:~$ sudo pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 app_vg lvm2 a- 80.00g 96.00m
########## Trecho 3 ##########
sysadmin@rjosrvuuxx02:~$ sudo lsscsi --size
[0:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sda 8.58GB
[1:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdb 85.8GB
########## Trecho 4 ##########
sysadmin@rjosrvuuxx02:~$ sudo pvdisplay /dev/sdb1
--- Physical volume ---
PV Name /dev/sdb1
VG Name app_vg
PV Size 80.00 GiB / not usable 3.00 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 20479
Free PE 24
Allocated PE 20455
PV UUID BTmBkB-eMlG-XD8R-afM3-Ia9m-RnDo-o6EWQx
########## Trecho 5 ##########
sysadmin@rjosrvuuxx02:~$ sudo lvs app_vg
LV VG Attr LSize Origin Snap% Move Log Copy% Convert
lvol_01 app_vg -wi-ao 79.90g
########## Trecho 6 ##########
sysadmin@rjosrvuuxx02:~$ sudo lvdisplay /dev/app_vg/*
--- Logical volume ---
LV Name /dev/app_vg/lvol_01
VG Name app_vg
LV UUID sR8iIj-lUct-SUeM-d6p9-2pKI-0LxR-SsPdGa
LV Write Access read/write
LV Status available
# open 1
LV Size 79.90 GiB
Current LE 20455
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:2A partir da coleta de dados realizada com a execução dos procedimentos da Listagem 2, concluímos a fase de mapeamento do servidor RJOSRVUXX02 e consolidamos as informações coletadas, conforme observado na Figura 4.
Figura 4. Dados a serem migrados do servidor RJOSRVUUXX02.
Mapeamento do servidor RJOSRVUUXX03
Na Listagem 3, temos todos os passos associados com o mapeamento do servidor RJOSRVUXX03, que possui um único File System a ser migrado. Diferentemente dos outros dois servidores já mapeados (RJOSRVUXX01 e 02), o servidor RJOSRVUXX03 não possui seus discos/LUNs gerenciados pelo LVM. O File System encontra-se no estado Hard Partition, ou seja, não dinâmico. Sendo assim, serão executados comandos específicos do sistema operacional para efetuar o mapeamento dos dados que serão migrados.
Para facilitar a compreensão da sequência de comandos exibida na Listagem 3, a dividimos em várias partes e agora explicaremos cada uma separadamente:
1- Por meio do comando df –h, verifique os File Systems que serão migrados. Podemos notar que existe somente o device /dev/sdb1 com o Mount Point /srv/monitor;
2- Nesse momento, vamos documentar como o disco/LUN /dev/sdb encontra-se do ponto de vista físico, ou seja, qual sua controladora, target e LUN. Essa informação pode ser utilizada em caso de Rollback e oferece uma visão clara da distribuição física dos discos/LUNs entre os barramentos e controladores existentes no servidor.
Utilizando o utilitário lsscsi, verifique o caminho físico da LUN que será migrada. Neste caso, temos o disco físico /dev/sdb associado ao device path 1:0:0:0. O disco /dev/sda não está marcado porque é a área de Boot do servidor;
3- Como o device /dev/sdb1 não está sob gerência do LVM, precisamos utilizar ferramentas do próprio sistema operacional para coletar dados para o planejamento do processo de migração. Assim, por meio do utilitário FDISK, verifique a atual parametrização do device, como tamanho e tipo de partição.
Neste caso, o disco/LUN /dev/sdb possui 85.9 GB e somente uma partição (1) com o Id 83 do tipo Linux. Outro ponto importante é verificar as informações de geometria física, como o tamanho em cilindros ou o tamanho em quantidade de blocos de 512 bytes, que serão utilizadas para recriar as partições no novo disco/LUN com as mesmas características físicas do disco/LUN antigo;
4- No momento da migração de dados, precisamos recriar esse File System no novo disco/LUN. Para isso é importante entender como o File System está montado e é utilizado atualmente, bem como saber: Qual o tipo de File System (ext3, ext4, ReiserFS, etc.)? Quais as opções de montagem? Está em apenas leitura ou leitura e escrita? A partir do comando mount –v, verifique a atual parametrização do File System e se não existe nenhuma opção de montagem diferente das parametrizações default.
Em nosso caso, o File System /srv/monitor é do tipo ext3 e possui opções default de montagem em modo Read-Write.
Listagem 3. Sequência de comandos para mapeamento do host RJOSRVUXX03.
########## Trecho 1 ##########
sysadmin@rjosrvuuxx03:~$ df -h | tail -1
/dev/sdb1 79G 65G 14G 82% /srv/monitor
########## Trecho 2 ##########
sysadmin@rjosrvuuxx03:~$ sudo lsscsi --size
[0:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sda 8.58GB
[1:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdb 85.8GB
########## Trecho 3 ##########
sysadmin@rjosrvuuxx03:~$ sudo fdisk -l /dev/sdb
Disk /dev/sdb: 85.9 GB, 85899345920 bytes
86 heads, 10 sectors/track, 195083 cylinders, total 167772160 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xbc8fdd60
Device Boot Start End Blocks Id System
/dev/sdb1 2048 167772159 83885056 83 Linux
########## Trecho 4 ##########
sysadmin@rjosrvuuxx03:~$ mount -v | grep /srv/monitor
/dev/sdb1 on /srv/monitor type ext3 (rw)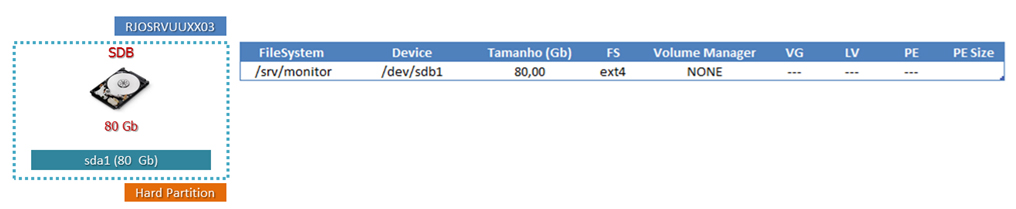
Figura 5. Dados a serem migrados do servidor RJOSRVUUXX03.
A partir da coleta de dados realizada com a execução dos procedimentos da Listagem 3, concluímos a fase de mapeamento do servidor RJOSRVUXX03 e consolidamos as informações coletadas, conforme observado na Figura 5.
Planejamento
A etapa de planejamento é uma das mais importantes do processo de migração de dados. Todo tempo gasto nessa etapa se traduz em conforto operacional, segurança e tempo poupado durante a migração dos dados. O contrário também é verdadeiro, ou seja, toda migração mal planejada ou calcada em informações inexatas resultam em problemas, os quais podem causar perda de dados.
Outro ponto importante é respeitar todas as diretrizes de negócio, como a janela produtiva do ambiente em questão, Downtime máximo permitido para a aplicação (quando aplicável), possibilidade de Rollback em caso de problemas, incluir tempo de Rollback no planejamento da janela de migração, entre outras.
Trabalharemos com a ideia de que existem três pilares básicos a serem considerados no momento da escolha da estratégia de migração: tempo, complexidade operacional e segurança de execução. Esses pilares são grandezas diretamente proporcionais, ou seja, procedimentos com nível de complexidade baixo resultam em menor nível de segurança. Já procedimentos com maior nível de complexidade e que demandam mais tempo e atenção, costumam proporcionar maior conforto operacional e segurança durante a execução da atividade. No entanto, ainda cabe um estudo caso a caso, e essa opinião é influenciada pela cultura individual de cada administrador.
Matriz de Compatibilidade
Todo equipamento ou software utilizado no segmento Enterprise tem sua devida documentação nos respectivos fabricantes bem atualizada. É altamente recomendado que as matrizes de compatibilidade e conectividade sejam validadas. Normalmente, para se conectar um dado equipamento, o fabricante recomenda a atualização de patches do sistema operacional e a re-parametrização de drivers scsi, fc ou da controladora Fiber Channel. Em alguns casos, quando existe alguma solução de alta disponibilidade envolvida como Clusters, pode ser necessário habilitar parâmetros específicos nas portas do Storage ou até mesmo flags de controle nas LUNs mapeadas aos servidores.
Todas essas informações referentes a pré-requisitos de conectividade e suporte dos equipamentos envolvidos costumam estar descritas nas documentações, ou podem ser obtidas juntamente ao suporte técnico do fabricante do equipamento ou produto.
Se essas informações não forem validadas antes da migração, podem resultar em problemas e inviabilizar o sucesso da atividade. Não é incomum administradores sofrerem problemas de conectividade entre sistema operacional e Storage por não se adequarem às matrizes de compatibilidade mantidas pelos fabricantes dos equipamentos e softwares de infraestrutura.
Backup dos Dados
As ferramentas utilizadas nesse artigo garantem a consistência dos dados, no entanto existem fatores externos como falha humana, quedas de energia, bugs de sistema operacional, entre outros, que podem comprometer o sucesso da atividade. Portanto, tenha certeza de que existam backups íntegros para casos extremos de necessidade. Caso haja disponibilidade de tempo, também simule um restore parcial de alguns dados, a título de validação.
Em alguns casos, backups podem ser armazenados em dispositivos que podem sofrer desgaste e ação do tempo e do ambiente, como fitas (DDS, LTO, DLT). Deste modo, é sempre interessante verificar se a mídia está em bom estado.
Estratégias de Migração
Conforme abordado anteriormente, é possível realizar a migração dos dados utilizando diversas técnicas, como migração via Storage, via Fabric (SAN) e via aplicação. Porém, esse artigo pretende abordar técnicas de migrações que são executadas via ferramentas do próprio sistema operacional ou recursos do gerenciador de volumes LVM.
As técnicas que serão utilizadas para migrar nosso ambiente proposto são:
· LVM – PV MOVE: Procedimento que utiliza o próprio gerenciador de volumes para migrar os dados por meio do comando PVMOVE. Essa técnica consiste em migrar um PV do disco/LUN origem para o disco/LUN destino;
· LVM – Split Mirror: Técnica que consiste num re-layout do volume, transformando-o em um espelhamento (RAID 1), e depois do momento de sincronismo do espelhamento, efetua SPLIT dos dados. Dessa forma, o dado é migrado entre a LUN origem (um lado do mirror) e a LUN destino (outro lado do mirror);
· Migração via ferramentas do sistema operacional: Essa é a técnica utilizada quando os dados a serem migrados não estão sob gestão do LVM ou algum outro gerenciador. Normalmente os File Systems são montados por meio do caminho lógico /dev/sdNx, ou seja, encontram-se em estado Hard Partition, conforme discutido anteriormente. Neste caso, realizaremos o procedimento utilizando o comando RSYNC, pois é uma ferramenta freeware disponível em praticamente todos os sabores de Unix e distribuições Linux, e oferece muitos recursos para manter a consistência dos dados, além de poder ser executada de forma incremental.
Para melhor compreensão do leitor, a Tabela 1 procura ilustrar as estratégias de migração que abordaremos nesse artigo, juntamente com um breve sumário de suas respectivas vantagens e desvantagens do ponto de vista de migração de dados.
Tabela 1. Estratégias de migração e suas vantagens e desvantagens.
Baseado nas informações coletadas na fase de mapeamento dos dados a serem migrados referentes aos servidores RJOSRVUXX01, 02 e 03, as seguintes estratégias de migração serão utilizadas:
1. RJOSRVUXX01 – Estratégia LVM PV Move;
2. RJOSRVUXX02 – Estratégia LVM Split Mirror;
3. RJOSRVUXX03 – Estratégia Rsync.
Planilha De/Para
A Planilha De/Para é uma nomenclatura não oficial para um documento que relaciona os discos/LUNs, File Systems e Volumes armazenados nos dispositivos que serão migrados com as informações dos novos dispositivos que receberão os dados oriundos do processo de migração. O objetivo desse documento é manter informações importantes sobre os dados que serão migrados e facilitar qualquer tipo de consulta de forma rápida.
A quantidade de informações nesse documento pode variar em função dos Storages ou gerenciadores de volumes envolvidos. Não existe um padrão exigido pelo mercado ou qualquer definição das informações que devem existir nesse documento, no entanto, conforme foi sinalizado anteriormente, quanto mais informação houver, melhor.
Quando temos acesso administrativo ao Storage, além do acesso aos sistemas operacionais dos servidores, é interessante do ponto de vista do mapeamento, incluir na Planilha De/Para informações de controle adicionais como nome e número da LUN, serial number, identificação do Storage utilizado, entre outros dados específicos da camada Storage. Em situações de verificação ou Rollback, o fácil acesso a esses dados se traduz em uma tomada de decisão mais rápida.
Em nosso artigo, não temos a necessidade do mapeamento dessas informações oriundas da camada Storage. Portanto, nosso documento De/Para será mais simples, apenas relacionando a LUN antiga à nova LUN, conforme pode ser observado na Tabela 2.
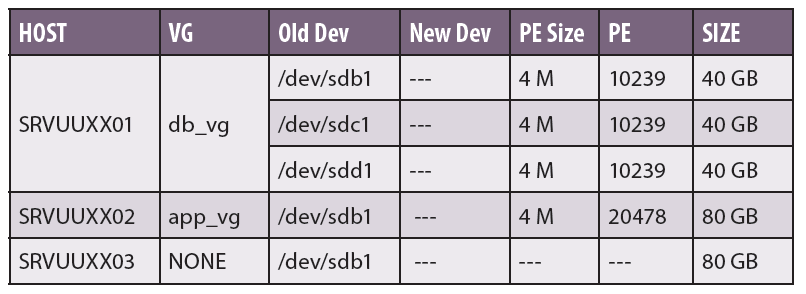
Tabela 2. Exemplo de documento De/Para.
Note que a coluna New Dev ainda encontra-se em branco e será preenchida na parte dois deste artigo, somente depois que os novos discos forem mapeados nos três servidores e tenhamos o endereçamento lógico desses em nível de sistema operacional.
Conclusão
A primeira parte deste artigo procurou trazer aos leitores a complexidade e a abrangência de um projeto de migração de dados, abordando algumas estratégias e metodologias que podem ser empregadas durante o planejamento e a execução das migrações de dados corporativos ou até mesmo pessoais.
Como podemos perceber, existem muitas outras tarefas em uma migração de dados do que simplesmente movimentar os dados entre o dispositivo de origem e o dispositivo de destino. Como exemplo, temos tarefas relacionadas a processos internos da companhia, gestão de mudanças, atualização dos controles internos das equipes de infraestrutura, janelas de execução, procedimentos de rollback, vasto planejamento prévio, levantamento detalhado dos dados, planilha De/Para, entre outros.
Na segunda parte desta série, serão apresentados os procedimentos técnico-operacionais, incluindo todos os comandos necessários para realizar a migração dos File Systems e volumes LVM existentes nos servidores RJOSRVUXX01, 02 e 03. Adicionalmente, serão tratados aspectos como a validação dos dados pós-migração e o Clean-Up do ambiente envolvido.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.