


Com uma grande quantidade de informações e uma extensa variedade de produtos e serviços, cada vez mais nos deparamos com dificuldades para escolher entre as alternativas apresentadas. Frente a este cenário, geralmente confiamos nas recomendações que são passadas por outras pessoas e tomamos como base sua satisfação em relação àquilo que estão nos recomendando. Essas recomendações acontecem de muitas formas, normalmente através de jornais, revistas, revisores de filmes e livros, entre outros.
O objetivo de um sistema de recomendação é melhorar a capacidade do processo de indicação, muito comum na relação social entre seres humanos. Nesses sistemas, os usuários fornecem as recomendações como entrada e o sistema as direciona para os indivíduos potencialmente interessados; como acontece no Netflix, quando classificamos um filme indicando o número de estrelas. Um dos grandes desafios desse tipo de sistema é realizar o casamento correto entre as pessoas que estão recomendando e as pessoas que estão recebendo a recomendação. Esse relacionamento é conhecido como relacionamento de interesse. Entre as principais técnicas para recomendação de conteúdo, podemos destacar a filtragem demográfica e a filtragem colaborativa.
A filtragem demográfica utiliza a descrição de um indivíduo para aprender o relacionamento entre um item em particular e o tipo de indivíduo que poderia se interessar por ele. Nessa abordagem, os dados pessoais do usuário são requisitados através de formulários e combinados com o seu perfil de consumo, permitindo estabelecer um relacionamento de interesse para cada tipo de indivíduo. Já na filtragem colaborativa, esse relacionamento é determinado através do comportamento comum de diferentes usuários, ou seja, a filtragem colaborativa considera que existe um perfil de consumo comum entre as pessoas que gostam das mesmas coisas. Essa abordagem é vantajosa porque não precisa coletar mais informações sobre o usuário, além das informações sobre o seu comportamento de consumo no próprio portal.
É muito comum um usuário gostar de diversos itens do mesmo portal, e ao mapear todos esses interesses, geramos um grande volume de dados. Isso acontece porque os portais oferecem uma grande quantidade de produtos, e cada produto visitado precisa gerar um log de acesso. Lidar com esse volume de dados nos leva a um cenário de Big Data, quando muitas vezes temos a necessidade de realizar processamento paralelo e distribuído. Isso se torna ainda mais importante quando aplicamos algoritmos de machine learning, que normalmente são caros do ponto de vista computacional. Felizmente, para isso, podemos contar com a ajuda do Apache Mahout e do Hadoop.
O Apache Mahout é uma biblioteca de machine learning de código aberto cujos principais objetivos são: processar recomendações, classificações e agrupamentos. Mantido pela Apache Software Foundation, o Mahout nasceu em 2008 como um subprojeto do Apache Lucene, outra ferramenta de código aberto destinada a problemas de busca e recuperação de informações. Em 2010 o Apache Mahout se tornou um projeto de software independente, que visa escalabilidade e eficiência. Por isso compatibilizou seus algoritmos com o Hadoop.
O Hadoop, por sua vez, é uma ferramenta de código aberto que implementa o paradigma Map-Reduce, introduzido pelo Google e criado para realizar processamento paralelo e distribuído. Assim, o Hadoop é capaz de processar grandes conjuntos de dados dividindo uma tarefa em pequenas partes e processando essas partes em máquinas distintas.
Este artigo mostra como utilizar o Apache Mahout e o Hadoop para construir um recomendador de vídeos inteligente e escalável. Em nosso experimento utilizaremos a base de dados aberta MovieLens, que é provida por um grupo de estudo especialista em recomendação de conteúdo da Universidade de Minnesota.
Apache Mahout
Como visto anteriormente, o Mahout é uma biblioteca de machine learning mantida pela Apache Software Foundation cujo objetivo é facilitar o uso de algoritmos de aprendizado de máquina quando utilizados em sistemas de processamento distribuído. Quando falamos em machine learning ou aprendizado de máquina, em português, estamos nos referindo a um conjunto de técnicas que permitem a uma máquina melhorar suas análises a partir de resultados obtidos anteriormente. Essas técnicas são muito exploradas pela mineração de dados e usam principalmente métodos estatísticos e probabilísticos, bem como reconhecimento de padrões e outras ferramentas matemáticas. Embora não seja uma área de estudo nova, está em pleno crescimento, tanto que grandes corporações, como Amazon, Facebook e Google, utilizam algoritmos desse tipo em muitas de suas aplicações.
Esses algoritmos são implementados em diversos tipos de aplicações, como: jogos, sistemas de detecção de fraudes, análise da bolsa de valores, forecast de preço, entre outros. Eles também são muito comuns em sistemas de recomendação, como os da Amazon e Netflix, que sugerem produtos aos usuários com base em compras/visualizações anteriores.
O aprendizado de máquina permite solucionar problemas a partir de duas abordagens: o aprendizado supervisionado e o aprendizado não supervisionado.
Aprendizado supervisionado
O aprendizado supervisionado consiste em aprender uma função a partir de um conjunto de dados de treinamento, previamente rotulados. Após o treinamento, a máquina se torna apta a classificar um novo dado com base nas regras aprendidas durante o treino.
Muitos problemas podem ser solucionados a partir do aprendizado supervisionado, tais como: classificar mensagens de e-mail como spam, rotular páginas da web de acordo com o gênero, reconhecimento de imagens, etc. Para solucionar esses problemas podemos utilizar diversos algoritmos, por exemplo: Redes Neurais Artificiais, Máquinas de Vetor de Suporte (SVM) e classificadores Bayesianos.
Aprendizado não supervisionado
No aprendizado não supervisionado não existe uma fase inicial de treinamento, pois seu propósito é indicar o significado dos dados. Essa técnica normalmente é utilizada para segmentar os dados e formar grupos lógicos, possibilitando identificar novas tendências e comportamentos.
Os algoritmos de aprendizado não supervisionado geralmente são utilizados para mapear padrões de consumo, bem como efetuar recomendações. Entre os principais algoritmos de aprendizado não supervisionado, podemos destacar: algoritmos de agrupamento e filtragem colaborativa.
Recursos do Apache Mahout
Os algoritmos oferecidos pelo Mahout se dividem em quatro grupos: filtragem colaborativa, algoritmos de classificação, algoritmos de agrupamento e algoritmos de redução de dimensionalidade. Todos eles podem ser utilizados via API e a maior parte deles também pode ser utilizada via linha de comando, através de shell interativo.
Hadoop
Como vimos anteriormente, o Hadoop é uma ferramenta de Map-Reduce que permite realizar processamento paralelo e distribuído. Ele é formado por dois componentes principais: o Hadoop Distributed File System (HDFS), que armazena e manipula os dados que serão processados pelas máquinas que compõem o cluster; e o Map-Reduce, que gerencia todo o processamento realizado pelo cluster de máquinas. A Figura 1 ilustra esses dois componentes.
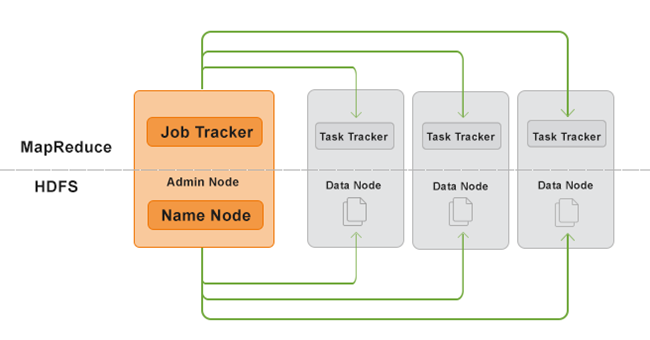
Figura 1. Componentes do Hadoop.
Hadoop Distributed File System (HDFS)

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






