


De que trata o artigo:
Descrição e demonstração da montagem, instalação e manipulação dos pacotes JAR e das classes Java desenvolvidas pelo usuário do banco de dados para serem utilizados em conjunto com as funções da linguagem procedural do PostgreSQL.
Para que serve:
Descrever a estrutura de um pacote JAR manipulado pelo PL/Java, bem como mostrar como construir o arquivo deployment descriptor para uma instalação/remoção/atualização automática da estrutura adjacente às classes Java. Descreve também como instalar e manipular os pacotes e classes Java depois de instalados na base de dados.
Em que situação o tema é útil:
Possibilidade de migração das regras de negócio, escritas em Java, da camada de aplicação para o banco de dados, aumentando os recursos do mesmo com a utilização e manipulação direta dos dados pelo Java.
Neste artigo, daremos inicio a uma nova série sobre a utilização da linguagem procedural PL/Java do PostgreSQL. Em edições anteriores da SQL Magazine (72 e 73) tivemos dois artigos sobre o tema. No primeiro deles descrevemos algumas características da linguagem e no segundo mostramos como preparar um servidor de banco de dados para utilizar o PL/Java no desenvolvimento das funções.
Neste primeiro artigo desta nova série, pretendemos descrever a estrutura de um pacote JAR criado pelo usuário, com suas classes Java, para ser carregado na base de dados. Mostraremos como escrever o deployment descriptor para fazer a instalação automática de toda estrutura adjacente das classes Java, bem como as funções de instalação e manipulação dos pacotes JAR.
A versão do PL/Java aqui discutida é a 1.4.0, com o PostgreSQL na versão 8.3.7 em ambiente Linux (CentOS 5.2).
Estrutura dos pacotes JAR
Antes de mostrar alguns exemplos práticos de como escrever as funções utilizando o PL/Java, é necessário entendermos alguns aspectos referentes à própria instalação das classes Java desenvolvidas pelo usuário.
Todos os exemplos mostrados a partir deste ponto serão baseados em funções e classes Java disponibilizadas em um pacote JAR chamado examples.jar (ler Nota DevMan 1). Este pacote é criado junto com os arquivos de instalação do PL/Java. Em nosso ambiente de demonstração, que montamos no artigo publicado na SQL Magazine 73, o pacote JAR foi instalado no diretório /var/lib/pgsql/pljava, conforme pode ser visto na Figura 1.
É um arquivo compactado usado para distribuir um conjunto de classes Java. É usado para armazenar classes compiladas e metadados associados que podem constituir um programa. Podem ser criados e extraídos usando o utilitário jar da JDK, bem como ferramentas de compressão (como o Winzip).
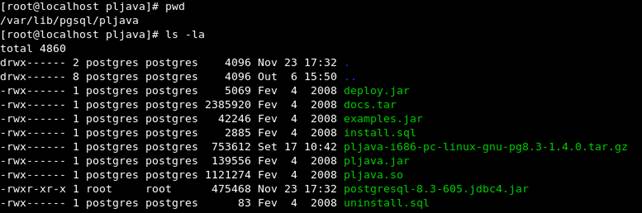
Figura 1. Localização do pacote JAR examples.jar.
Toda classe Java desenvolvida pelo usuário, e que será usada pelas funções do PL/Java, deve ser instalada na base de dados através de um pacote JAR. Na Figura 2 podemos ver a estrutura geral do JAR que é utilizado pelo PL/Java e na Figura 3, a estrutura do arquivo examples.jar. Esta estrutura é semelhante a um arquivo EAR (ler Nota DevMan 2).
É um formato de arquivo usado pelo Java EE (Java Enterprise Edition) para empacotar um ou mais módulos de uma aplicação em um único arquivo. Com isso, a aplicação destes módulos em um servidor de aplicação pode acontecer de maneira simultânea e segura. Arquivos EAR possuem um arquivo XML que descreve como os módulos serão aplicados. Um arquivo EAR tem a mesma estrutura de um arquivo JAR, com uma ou mais entradas que representam os módulos de uma aplicação e um diretório de metadados, chamado META-INF, que contém um ou mais descritores de aplicação.
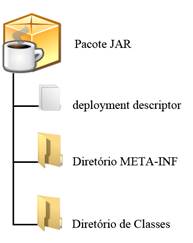
Figura 2. Estrutura geral de um pacote JAR do PL/Java.
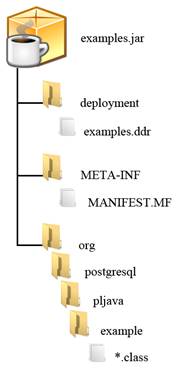
Figura 3. Estrutura do pacote examples.jar.
O diretório de classes é a única estrutura de diretórios obrigatória no arquivo JAR. Este diretório vai seguir o mesmo padrão de definição de um pacote Java, como por exemplo, a classe Security, do arquivo examples.jar, que tem a definição de pacote org.postgresql.pljava.example. Todas as classes deste arquivo estão neste diretório (Figura 3).
O arquivo deployment descriptor é opcional. Diferente do deployment descriptor para Java, que é no formato XML, este arquivo contém comandos SQL, ou seja, é um arquivo de script SQL, com entradas específicas, que diz ao PL/Java o que fazer quando o arquivo JAR é instalado ou removido da base de dados. Ele nada mais é do que um arquivo texto que descreve como e o que criar/remover do database, podendo manipular esquemas, tabelas, índices, funções, triggers e etc.
Este arquivo pode ficar dentro de um diretório, como no arquivo examples.jar (Figura 3), ou na raiz do arquivo JAR, como na Figura 2. Pode ser usada qualquer extensão para o arquivo, ou até mesmo sem extensão. Na Figura 3 podemos observar que o deployment descriptor está no diretório deployment, com o nome examples.ddr. A próxima seção mostrará como escrever o seu conteúdo.
O diretório META-INF também é opcional. Caso o deployment descriptor seja usado, é necessário que exista este diretório com um arquivo Manisfest (ler Nota DevMan 3). Este arquivo tem o nome MANIFEST.MF e tem a função de informar onde está localizado o deployment descriptor. O arquivo Manifest, para o PL/Java, deve conter as informações mostradas na Listagem 1. A Listagem 2 mostra o conteúdo do arquivo MANIFEST.MF de examples.jar.
Determina o funcionamento de um arquivo JAR. Ele é apenas um documento de texto que pode indicar a classe principal de uma aplicação, bem como outros arquivos necessários para que a aplicação funcione. A especificação do formato JAR define como obrigatório apenas a existência do arquivo Manifest, com o nome MANIFEST.MF, em um diretório chamado META-INF. O arquivo Manifest segue a especificação definida pela Sun Microsystems.
Cada linha no arquivo Manifest possui o formato palavra-chave: valor. A linha 1 da Listagem 2 informa a versão do arquivo Manifest (seguindo a especificação da Sun Microsystems). A linha 2 indica a localização do deployment descriptor e qual o arquivo que será usado.
A linha 3 mostra a palavra-chave SQLJDeploymentDescriptor. Esta por sua vez, diz ao PL/Java que o arquivo especificado pela palavra-chave Name, na linha 2, é o deployment descriptor do arquivo JAR que está sendo instalado na base de dados.
Verifique a seção Links para mais informações sobre a especificação de um arquivo Manifest e pacotes JAR.
Listagem 1. Formato do arquivo Manifest.
Name: <Localização do deployment descriptor dentro do arquivo JAR>
SQLJDeploymentDescriptor: TRUEListagem 2. Conteúdo do arquivo MANIFEST.MF do arquivo examples.jar.
1. Manifest-Version: 1.0
2. Name: deployment/examples.ddr
3. SQLJDeploymentDescriptor: TRUEEstrutura do Deployment Descriptor
Quando criamos um arquivo JAR e desejamos que uma sequência de comandos (SQL ou não) seja executada durante a instalação/remoção do JAR na base de dados, precisamos criar e incluir o arquivo deployment descriptor, criando assim, um arquivo auto-instalável/removível. A especificação da estrutura deste arquivo é descrita na Listagem 3.
As ações/comandos que são executados se dividem em dois grupos: um grupo de ações de instalação e outro de remoção. Estas ações são manipuladas pelas funções install_jar, replace_jar e remove_jar, que estão instaladas no esquema sqlj. Estas funções serão descritas com mais detalhes na seção seguinte.
A função install_jar executa o grupo de ações de instalação. A função remove_jar manipula o grupo de ações de remoção. Já a função replace_jar age sobre os dois grupos de ações, executando as ações de remoção e depois as de instalação.
Listagem 3. Estrutura do arquivo deployment descriptor.
SQLActions[]={"<grupo de ações>" [,"<grupo de ações>"]}
onde <grupo de ações> é:
<ações de instalação> | <açoes de remoção>
<ações de instalação> é:
BEGIN INSTALL [<comando>;]... END INSTALL
<açoes de remoção> é:
BEGIN REMOVE [<comando>;]... END REMOVE
<comando> é:
<SQL | gerenciamento do BD> | <tag de implementação>
<tag de implementação> é:
BEGIN <id da tag> <SQL | gerenciamento do BD> END <id da tag>
<id da tag> é:
postgresql
oracle
sybase e etc.Cada grupo de ação é opcional, onde podemos ter o grupo de ações de instalação sem ter o de remoção e vice-versa. Além disso, toda a escrita no arquivo é case insensitive.
Cada grupo de ação inicia com as palavras-chave begin install (para instalação) ou begin remove (para remoção), seguido do bloco de comandos que serão executados durante a instalação/remoção do arquivo JAR, e finaliza com as palavras-chaves end install ou end remove.
A Listagem 4 mostra um exemplo completo de um deployment descriptor, onde podemos ver, na linha 2, o início do bloco das ações de instalação com os comandos que serão executados quando o pacote JAR for instalado na base de dados. A linha 3 mostra uma tag de implementação, que modifica um parâmetro do PostgreSQL. Temos também a criação de uma função nas linhas 4 e 5 e o final das ações de instalação na linha 6. As linhas de 7 a 9 mostram as ações de remoção. A Listagem 5 mostra partes do arquivo examples.ddr do pacote JAR examples.jar.
Listagem 4. Exemplo completo de um deployment descriptor.
1. SQLActions[ ] = {
2. "BEGIN INSTALL
3. BEGIN PostgreSQL SET search_path TO locadora END PostgreSQL;
4. CREATE FUNCTION getRelAnual(int) RETURNS float8
5. AS 'Locadora.getRelAnual(int)' LANGUAGE java;
6. END INSTALL",
7. "BEGIN REMOVE
8. DROP FUNCTION getRelAnual(int);
9. END REMOVE"}Listagem 5. Partes do arquivo examples.ddr do pacote examples.jar.
SQLActions[ ] = {
"BEGIN INSTALL
CREATE SCHEMA javatest;
BEGIN PostgreSQL SET search_path TO javatest,public ENd postgreSQL;
CREATE FUNCTION javatest.java_getTimestamp()
RETURNS timestamp
AS 'org.postgresql.pljava.example.Parameters.getTimestamp'
LANGUAGE java;
...
CREATE TABLE javatest.username_test
(
name text,
username text not null
) WITH OIDS;
...
CREATE TRIGGER insert_usernames
BEFORE INSERT OR UPDATE ON username_test
FOR EACH ROW
EXECUTE PROCEDURE insert_username (username);
...
END INSTALL",
"BEGIN REMOVE
DROP SCHEMA javatest CASCADE;
END REMOVE"
}O comando executado dentro do bloco de ações pode ser de três tipos:
A ideia por trás da utilização da tag de implementação é escrever comandos (SQL ou não) que são específicos do SGBD onde as classes estão sendo instaladas. Por exemplo, os comandos abaixo só serão executados sem erros no PostgreSQL:
SET search_path TO javatest,public;
insert into tb_teste values (now(), 1);Se o pacote JAR for instalado apenas em bases do PostgreSQL, estes comandos poderão ser escritos fora de uma tag de implementação. Mas se tentarmos instalar o JAR em outros SGBDs, ocorrerão erros, pois os comandos estão utilizando partes de código que não fazem parte do padrão SQL, como a função now(), do comando INSERT.
Para resolver este problema, foi criada a tag de implementação onde é passado o identificador da tag (<id da tag>), que nada mais é do que o nome do SGBD em que o pacote JAR está sendo instalado. Podem existir várias tags de implementação para SGBDs diferentes no mesmo deployment descriptor. Cada comando dentro da tag só será executado para o SGBD específico onde o PL/Java está instalado.
A Listagem 6 mostra um exemplo com os comandos acima dentro das tags de implementação, junto com tags de outros SGBDs. Neste caso, como o PL/Java está instalado no PostgreSQL, quando o deployment descriptor for executado, somente as tags com identificador igual a postgresql serão executadas. O identificador da tag também é case insensitive.
Listagem 6. Exemplos de tags de implementação em um deployment descriptor.
...
BEGIN PostgreSQL SET search_path TO javatest,public END PostgreSQL;
BEGIN PostgreSQL insert into tb_teste values (now(), 1) END PostgreSQL;
BEGIN Oracle create tablespace data datafile '/home/oracle/databases/ora10/data.dbf'
size 10M
autoextend on maxsize 200M
extent management local uniform size 64K END Oracle;
...Com o que foi explicado podemos questionar o seguinte: se o PL/Java é para o PostgreSQL, porque existe a tag de implementação para outros SGBDs?
A resposta para esta pergunta é simples. Uma das grandes vantagens do Java é a portabilidade. O engine do PL/Java é escrito em Java, sendo possível desenvolver novas interfaces, classes e métodos no engine, para serem utilizados em outros SGBDs.
As classes desenvolvidas e empacotadas em arquivos JAR também aderem a esta facilidade, utilizando a linguagem Java para serem utilizadas em qualquer ambiente. Com isso, não necessitamos criar um arquivo JAR para cada banco, basta utilizar as tags de implementação para comandos específicos do SGBD.
Estrutura do esquema SQLJ
No artigo publicado na SQL Magazine 73, mostramos um dicionário de dados de todo o esquema sqlj ...

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






