


Ao longo deste artigo introduziremos os conceitos fundamentais de um framework muito popular empregado no desenvolvimento de aplicações de processamento em lote: o Spring Batch.
Este tipo de solução é comum em ambientes nos quais são necessários a leitura, o processamento e a persistência de grandes volumes de dados.
O foco deste texto recai principalmente na apresentação dos elementos fundamentais que compõem o desenho do framework, usando como pano de fundo um projeto prático.
Ao final do artigo, esperamos que o leitor tenha adquirido uma visão clara da arquitetura do Spring Batch, fundamental para que consiga explorar todos os seus recursos de maneira plena e consistente na construção de suas soluções.
Todo ambiente de negócio em que grandes volumes de dados são continuamente gerados e processados acabará se tornando um potencial cliente de sistemas de processamento em lotes. Imagine, por exemplo, grandes operadoras de telefonia que recebem, por dia, milhares de ligações de clientes para reclamar de um serviço, buscar informações gerais ou, ainda, cancelar ou atualizar seus planos.
Todas as informações geradas a partir dessas experiências são muito valiosas e, quando combinadas com dados provenientes de outros sistemas e/ou serviços – como ERPs e CRMs – resultam em um material extremamente estratégico que pode ser usado – e frequentemente o é – para melhorar a experiência do público.
Neste caso que acabamos de citar, a leitura e a persistência desses dados são apenas os primeiros passos de uma série de outros que ocorrem no interior desses grandes sistemas.
Todo registro de entrada, quando armazenado, representa um evento bastante pontual, uma experiência bastante particular.
Quando combinados com toda uma base histórica previamente disponível, ganham uma importância muito mais evidente, pois somam-se a inúmeras ocorrências similares que, então, permitem a analistas traçar perfis de comportamento de seus clientes ao longo do tempo.
Além disso, nada impede que registros cheguem a uma plataforma por inúmeros pontos de entrada e, internamente, sejam combinados para representar uma informação de forma mais rica, mais completa.
Voltando ao exemplo de atendimento ao cliente, é possível que os diversos componentes envolvidos – atendimento automático, transferência para e entre agentes, dentre outros – utilizem sistemas de informação/armazenamento separados e, para que a interação do cliente seja representada de forma plena, algumas transformações e combinações devam ser realizadas.
Outro cenário típico de processamento de dados em lotes é o de sistemas de fechamento contábil utilizado pelas empresas, na organização de sua saúde financeira. Periodicamente, a cada fim de mês, todos os registros de entrada e saída de capital são combinados e processados para que um balanço final possa ser obtido. Novamente, percebemos que há um volume importante de registros que deve ser lido e processado para que possa, enfim, ser empregado em análises e tomadas de decisão.
Torna-se simples constatar, pelos exemplos supracitados, o quão amplo é o leque de cenários em que este tipo de sistema pode ser aplicado. Logo mais, na parte prática do artigo, veremos em detalhes outro exemplo bastante corriqueiro.
Ao mesmo tempo que esta arquitetura de sistemas é comum e sua empregabilidade tende a ser alta, seus componentes essenciais variam muito pouco em comportamento. Em linhas gerais, os elementos centrais destinam-se a:
· Organizar o processamento em lotes de itens;
· Ler itens em alguma fonte de dados;
· Escrever itens em alguma fonte de dados;
· Registrar todas as operações realizadas ao longo da vida útil do sistema.
As fontes de dados mais comuns, por sua vez, são bancos de dados relacionais, arquivos de texto em formatos como XML ou CSV e filas e tópicos de sistemas de mensageria. Essas fontes servem tanto para consumo quanto para escrita de itens, mas a operação de escrita ou leitura sobre elas é algo bem conhecido da grande maioria dos desenvolvedores, e sua implementação tende a não variar em lógica, mas no conteúdo do que se lê ou escreve.
Por esta breve descrição de apenas parte do que sistemas dessa natureza fazem, já identificamos características e operações que tendem a se repetir em toda implementação. Sendo assim, escrevê-lo a cada projeto que iniciamos seria, sem dúvidas, um consumo desnecessário de tempo e recursos; traria, também, o risco que todo código-fonte novo tem, por mais bem escrito e testado que esteja: a possibilidade de falhar.
A solução natural para alcançar alta produtividade e qualidade no desenvolvimento de software, especialmente à luz do paradigma da orientação a objetos, todos nós sabemos: reuso. Quanto mais frameworks, bibliotecas e plataformas estiverem disponíveis e, principalmente, maduras, maiores serão as chances de combiná-las na construção de um produto ou serviço de alta qualidade, em um intervalo de tempo razoavelmente pequeno. Logo, devemos trabalhar constantemente nossa habilidade de não apenas identificar frameworks interessantes para os mais variados cenários de aplicação, mas também nos mantermos constantemente atentos ao código que produzimos, a fim de identificarmos qualquer possibilidade de reuso da lógica que desenvolvemos.
É neste contexto que o Spring vem, há anos, mostrando ser uma iniciativa muito bem-sucedida. Altamente modularizado, atende a praticamente todos os principais escopos técnicos de desenvolvimento de soluções de software. A Java Magazine tem sido, por anos, uma grande divulgadora deste framework, reservando em seu acervo excelentes artigos de profissionais renomados no mercado brasileiro, sobre várias das bibliotecas que compõem o que chamaremos aqui de ‘Ecossistema Spring’. Da biblioteca básica de injeção de dependências e gerenciamento de contextos a outras mais complexas como Spring Data ou Spring Integration, fica sempre a impressão de um material muito bem produzido e fácil de utilizar.
Ao longo deste artigo, estudaremos as características fundamentais do Spring Batch. Esta é a oferta da Spring para a construção de sistemas de processamento em lotes. Marcado por sua estabilidade, é um framework muito bem escrito, fácil de utilizar e largamente empregado pela comunidade. Dito isso, iniciaremos com uma breve revisão sobre os principais pontos de sua arquitetura para, então, avaliar parte de seus recursos e de sua API no desenvolvimento de uma aplicação prática.
O que é o Spring Batch?
O Spring Batch oferece inúmeros recursos e funções essenciais não apenas para o processamento de grandes volumes de dados, mas, também, acompanhamento e registro de toda esta execução. A biblioteca prevê suporte para o gerenciamento de transações, análise estatística, reinicialização e cancelamento de tarefas, rastreamento e registro dos ciclos de execução de lotes, dentre outros recursos. O mais interessante em tudo isso é que grande parte do esforço que o desenvolvedor terá usando este framework estará relacionado à configuração dos componentes já existentes, acelerando significativamente e garantindo, ao mesmo tempo, alta qualidade no processo de criação de software.
É importante salientar que, embora sistemas de processamento em lote sejam executados periodicamente, esta não é uma funcionalidade oferecida nativamente pelo framework; por outro lado, é bastante simples integrá-lo com muitas das bibliotecas desenhadas para este fim. Historicamente, observa-se uma combinação muito bem-sucedida entre Spring Batch e Quartz Scheduler, e maiores informações sobre sua utilização podem ser encontradas adiante, na seção Links.
Principais componentes
Antes de começarmos a desenvolver nossa aplicação prática, é importante que nos acostumemos com o vocabulário utilizado pelo framework para representar os principais conceitos que formam o domínio do problema. Para facilitar este nosso estudo, observe os componentes ilustrados na Figura 1. É sobre esta estrutura fundamental que passaremos a conversar a partir de agora.
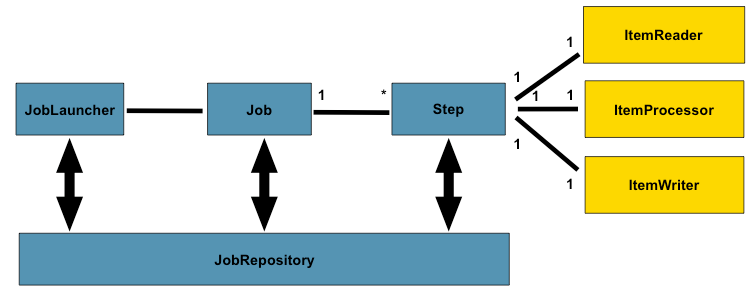
Figura 1. Composição do Spring Batch.
Job
Este é o conceito mais genérico e mais importante dentro do Spring Batch. O próprio nome já sugere o seu significado dentro do framework: um trabalho! Em outras palavras, é o que será efetivamente executado pelo sistema.
Outro ponto que devemos esclarecer é que há uma separação muito bem desenhada entre o conceito de um trabalho e a sua execução. Quando configuramos um job, estamos declarando tudo aquilo que precisa ser feito quando este for colocado em execução. Esta, por sua vez, representa um evento específico em que tudo o que foi configurado e planejado é efetivamente realizado.
Esta separação de conceitos – e responsabilidades – está ilustrada na Figura 2. Nela, vemos que existem dois tipos de objetos que separam muito bem esses dois componentes: Job e JobInstance. Enquanto a tarefa em si é, digamos, ler um arquivo CSV, processá-lo, transformar os registros de acordo com algumas regras de negócio e, por fim, persistir toda esta informação em um banco de dados relacional, podemos querer que este mesmo procedimento seja realizado, digamos, mensalmente.
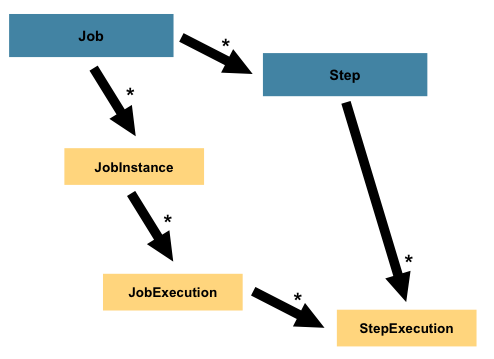
Figura 2. Análise mais granular do conceito de um job.
O Job, neste cenário, representa o escopo do trabalho a ser realizado. JobInstance, por sua vez, destina-se à representação de um evento particular em que o trabalho será executado. Uma combinação destes dois tipos de objetos seria, por exemplo:
· Um Job configurado para coletar todos os registros de movimentação financeira realizada por uma empresa ao longo de um mês, efetuando algumas agregações, cálculos de fluxo de caixa, dentre outras operações e, por fim, registrando tais resultados em alguma fonte de dados. Chamemos este Job de calculo_contabil;
· Como um ano é composto de 12 meses e o trabalho de fechamento contábil é executado mensalmente, teremos a configuração de cada um desses eventos a partir de um objeto JobInstance diferente. Logo, para um exercício anual, teríamos 12 instâncias de JobInstance para o Job calculo_contabil. Todos esses objetos JobInstance representam o mesmo trabalho a ser feito, mas cada um mapeia as características deste trabalho para um mês do ano;
· A partir dessa combinação, o mesmo Job calculo_contabil teria, digamos, objetos JobInstance intitulados calculo_contabil_Jan, calculo_contabil_Fev, calculo_contabil_Abr, calculo_contabil_Mai, calculo_contabil_Jun, calculo_contabil_Jul, calculo_contabil_Ago, calculo_contabil_Set, calculo_contabil_Out, calculo_contabil_Nov e calculo_contabil_Dez.
JobInstance, no entanto, não representa o nível mais granular deste domínio. Imagine que, por qualquer motivo (uma queda de energia, ausência de rede, falta de memória), a execução do fechamento contábil do mês de janeiro (calculo_contabil_Jan) resultasse em falha (ou fosse interrompida abruptamente). Seria necessário que, em algum momento, essa execução fosse reiniciada, o que significa que o JobInstance calculo_contabil_Jan teria que ser executado, no mínimo, mais uma vez.
Para representar as várias execuções de um mesmo JobInstance, o Spring Batch oferece um tipo de objeto chamado JobExecution. Assim, podemos mapear não apenas os eventos particulares de um Job a partir de objetos JobInstance, mas cada execução de cada evento, ao longo da vida útil de nossa aplicação. Voltando ao exemplo que iniciamos anteriormente, a combinação desses três tipos de objetos (Job, JobInstance e JobExecution) ficaria:
· O mesmo Job mencionado acima, calculo_contabil;
· As mesmas 12 instâncias de JobInstance, para o Job calculo_contabil, sendo cada instância dedicada à representação do trabalho de um mês do ano;
· Duas instâncias de JobExecution para o JobInstance calculo_contabil_Jan:
o calculo_contabil_Jan_01, referente à primeira execução que falhou;
o calculo_contabil_Jan_02, referente à nova execução iniciada quando, por exemplo, a energia do prédio foi reestabelecida e o servidor voltou a operar.
Isto é tudo o que prec ...

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






