Desenvolver camadas de acesso a dados pode ser muito trabalhoso, principalmente pela necessidade de se ter que escrever código SQL, além de se precisar lidar com a diferença de paradigmas entre o modelo de objetos e o relacional. Conhecer e utilizar um framework de ORM simplifica a implementação e pode minimizar o esforço de realizar tarefas que se repetem para cada classe persistente.
Atualmente, a maioria das aplicações utiliza uma linguagem orientada a objetos na construção do software, e um banco de dados relacional para a persistência – armazenamento – dos dados. Mesmo que haja outras soluções, esta ainda é a mais utilizada e, infelizmente, ela precisa lidar com o que é comumente chamado diferença de impedância entre o modelo de objetos e o modelo relacional. Esta diferença existe porque o paradigma orientado a objetos baseia-se em princípios de engenharia de software, enquanto o paradigma relacional baseia-se em princípios matemáticos – a álgebra relacional. Para juntar os dois modelos em uma aplicação é necessário entendê-los e conhecer suas diferenças. E, principalmente, é fundamental entender o processo de mapear objetos para o modelo relacional e como implementar esse mapeamento. A técnica de mapear uma representação de dados de um modelo de objetos para um modelo relacional é chamada Mapeamento Objeto-Relacional (ORM), que será mais amplamente discutida na próxima seção. Em projetos de desenvolvimento atuais, cada vez mais complexos, isso pode se tornar uma tarefa pesada e exigir muito tempo do programador.
O padrão Enterprise JavaBeans (EJB) de Java 2 Enterprise Edition (J2EE) já apresentava mecanismos de persistência baseados em contêineres ou baseados em beans, nas classes chamadas entity beans. No entanto essa proposta ainda sofria em certo grau com o descompasso entre modelo relacional e o modelo orientado a objetos.
Como uma alternativa ao modelo proposto pelo EJB2, surgiu o Hibernate – um framework de Mapeamento Objeto-Relacional. Seu objetivo era oferecer uma capacidade de persistência melhor e mais simples do que o proposto pelo EJB2. Em razão de ser uma solução simples, prática e de código aberto, logo o Hibernate se popularizou, tornando-se “de fato” o padrão de persistência em Java.
Uma consequência do sucesso do Hibernate como solução em ORM foi a participação ativa de Gavin King – o criador da ferramenta – no comitê da Java Specification Requests (JSR) 220. A JSR 220 descreve uma padronização de ORM, chamada Java Persistence API (JPA), que foi incluída na versão 3 do EJB. A especificação da JPA passou a ser implementada no Hibernate a partir da versão 3 do framework.
Este artigo está divido em duas partes. Na primeira estudaremos os conceitos relacionados ao Hibernate, sua arquitetura e uma introdução à configuração das opções disponíveis para o mapeamento objeto-relacional. A aplicação prática do que será apresentado aqui deixaremos para a segunda parte da matéria.
De uma maneira bem simples, pode-se afirmar que Mapeamento Objeto-Relacional é a persistência, ou seja, o armazenamento de objetos criados em uma aplicação, para tabelas em um banco de dados relacional, usando metadados que descrevem tal mapeamento. Metadados são dados que descrevem outros dados, e serão estudados com mais detalhes em uma próxima seção. Essencialmente, o ORM trabalha convertendo dados que estão representados como objetos na aplicação, para a representação de tabelas em bancos de dados relacionais, e vice-versa. Ou seja, além de persistir os objetos na forma de tabelas, ele também recupera os dados convertendo-os em objetos. Uma solução de persistência deve ser automática e transparente. Transparente no sentido de que as classes persistentes não devem saber da existência e nem depender do mecanismo de persistência. Automática porque a solução de persistência deve liberar o desenvolvedor de ter que lidar com detalhes tais como, escrever comandos SQL e trabalhar com a API JDBC.
Para entender mais facilmente o ORM, iniciaremos falando sobre o mapeamento de propriedade, que consiste no mapeamento de um atributo de uma classe para uma coluna de uma tabela. Um atributo pode ser mapeado para zero ou mais colunas em um banco de dados relacional. Vejamos um exemplo para esclarecer a afirmação anterior. Se um atributo é resultado de cálculo dentro da aplicação – tal como a média de um objeto Aluno – ele não precisa ser salvo no banco de dados, portanto não é necessário que seja mapeado. Por sua vez, os atributos nome e cpf de Aluno precisam ser mapeados, e neste caso o mapeamento é de um atributo para uma coluna. E se um atributo é outro objeto – tal como o objeto Endereco de Aluno – isso seria uma associação entre classes que necessita ser mapeada. Então os atributos do objeto Endereco precisariam ser mapeados, o que nos leva à definição de que um atributo será mapeado para zero ou mais colunas do banco de dados.
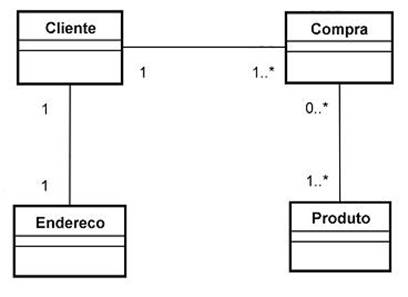
No modelo de objetos uma classe pode se relacionar com outra através de associação e agregação. A multiplicidade desses relacionamentos pode ser 1:1 (um para um), 1:N (um para muitos), N:1 (muitos para um) ou N:M (muitos para muitos). Na Figura 1 pode ser observado um exemplo que contempla as multiplicidades acima. O diagrama usa a notação UML (Unified Modeling Language), uma linguagem padrão para modelagem orientada a objetos. Pode-se notar que o relacionamento entre Cliente e Endereco é 1:1, entre Cliente e Compra é 1:N e entre Compra e Produto é N:M. Genericamente falando, em UML, o asterisco é o mesmo que N (muitos).
Similarmente, as tabelas no modelo relacional se relacionam usando as mesmas cardinalidades. Os relacionamentos no modelo de objetos são implementados através de referências, e no modelo de dados são realizados através de associações de chaves estrangeiras.
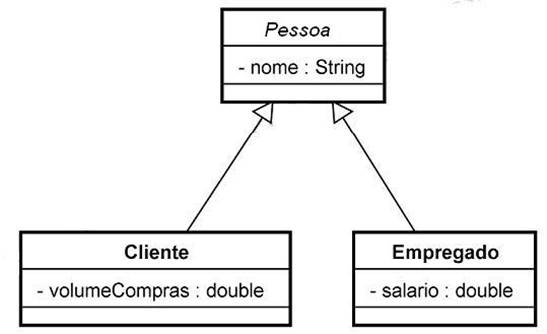
A estratégia mais simples de mapeamento de classes para tabelas é de uma tabela para cada classe persistente. É uma abordagem que funciona bem até que nos deparemos com a necessidade de mapear herança.
No modelo de objetos é possível modelar tanto o relacionamento “tem um” (associação) quanto o relacionamento “é um” (herança). Já no modelo relacional existe apenas o relacionamento “tem um”. Como os SGBDs não suportam herança de tipos, o mapeamento não é tão simples e existem estratégias diferentes para representar uma hierarquia, das quais as três mais simples serão apresentadas a seguir. Para um melhor entendimento, usaremos a hierarquia mostrada na Figura 2, onde Pessoa é uma classe abstrata. Isto é, Pessoa é uma classe que não pode ser instanciada.
A partir da próxima seção será mostrado como o Hibernate é organizado e como configurá-lo para que ele realize o mapeamento objeto-relacional.
Segundo o padrão ISO/IEEE 1471-2000, arquitetura de software é a organização fundamental de um sistema incorporada em seus componentes, seus relacionamentos com outros sistemas, e os princípios que conduzem o seu desenho e sua evolução. E isto é o que será apresentado nesta seção: os componentes do Hibernate e seus relacionamentos.
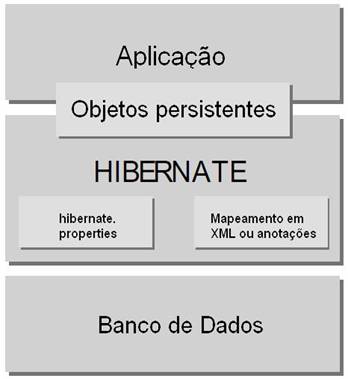
Na Figura 3 é mostrada uma visão em alto nível da arquitetura do Hibernate. Como é possível observar, o framework é uma camada entre a aplicação Java e o banco de dados, utilizando configurações para fornecer o serviço de persistência. No entanto, o framework de ORM é flexível o suficiente para suportar diferentes abordagens (várias arquiteturas), ou seja, seus componentes podem ser combinados de várias maneiras, de forma a atender necessidades específicas de cada problema. A seguir é apresentada a abordagem mais simples de utilização do Hibernate, que a documentação oficial chama de arquitetura “mínima”.
 ...
... 
Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.