


É evidente que cada vez mais as empresas enxergam os dados que detém como um de seus ativos, algo de valor que pode trazer vantagem competitiva ao saber lidar com eles. Saber interpretar os dados pode ajudar a entender mais sobre o negócio e a tomar decisões com mais eficácia. Empresas de sucesso como Google, Facebook e Amazon estão o tempo todo coletando e estudando os dados que seus usuários geram. Através desses estudos, eles podem entender melhor a sua audiência reconhecendo padrões, tendências e oportunidades, de forma a sempre tentar oferecer para os usuários algo que faça mais sentido para eles.
É importante empregar a tecnologia correta para lidar com esses dados de forma que seja eficiente e fácil de trabalhar com eles (quanto mais rápido for possível extrair informação dos dados, menor a chance de perder oportunidades). Um dos aspectos tecnológicos a ser considerado é a forma como os dados são armazenados. Saber usar a tecnologia certa faz a diferença quando é preciso processar milhões ou até bilhões de registros em poucos segundos.
Quando se pensa em banco de dados, é comum que a representação mais óbvia para ilustrar uma tabela seja algo similar a uma planilha em que temos um identificador para cada linha e uma série de colunas, cada uma com um valor. Em se tratando de um banco de dados orientado a linhas, a forma como os dados são guardados segue exatamente esse princípio e ele faz todo o sentido quando estamos tratando de dados transacionais ou cadastrais.
Sistemas transacionais são muito comuns e para esse tipo de sistema é importante que o banco de dados responda rapidamente para consultas referentes a um determinado atributo identificador (como um CPF de uma pessoa, um código de barras de um produto, etc.). Nessa situação, normalmente temos um volume grande de consultas, inserções e alterações dos dados das tabelas, mas que impactam em um volume pequeno de registros. Esse tipo de cenário é chamado de OLTP (Online Transction Processing).
Agora, considere uma tabela que guarde todos os registros de vendas de uma determinada empresa e que é necessário saber o montante total dessas vendas. Esse tipo de consulta é muito comum para a geração de relatórios, e situações dessa natureza normalmente precisam varrer grandes quantidades de dados, sendo que eles sofrem pouca ou nenhuma alteração com o decorrer do tempo. Esse tipo de cenário é chamado de OLAP (Online Analytical Processing).
Em um sistema orientado a linhas, para realizar a consulta descrita no parágrafo anterior seria preciso percorrer todas as linhas da tabela e ler todas as colunas, independentemente de elas serem necessárias ou não para se obter o resultado da consulta dada a forma como o dado é armazenado. E se a coluna que guarda o valor da venda fosse armazenada de forma totalmente independente das outras colunas da tabela? Seria muito menos custoso ler apenas os dados dessa coluna para se obter o resultado da consulta. Essa é justamente a proposta quando se trata de armazenamento colunar.
A forma como um sistema de banco de dados com armazenamento colunar (também conhecido como orientado a colunas) guarda os dados é bem diferente da forma mais tradicional orientada a linhas, considere como exemplo a tabela representada na Figura 1.
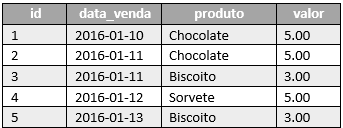 ...
... 
Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






