Fornecer uma atualização das novidades do EJB 3.1 para desenvolvedores, arquitetos, interessados na tecnologia ou aqueles que, de alguma forma, estejam envolvidos em projetos que utilizam EJBs.
O tema é útil para empresas que utilizam EJBs e desejam manter seus produtos com tecnologia de ponta ou, até mesmo, melhorar sua produtividade. É importante também para profissionais que desejam ampliar seus conhecimentos atualizando-se com o que está por vir na tecnologia.
A nova tecnologia traz melhorias muito importantes em recursos já existentes, dentre os quais se destacam o serviço de agendamento (Timer Service) e a padronização de nomes JNDI globais. Adicionalmente, há alguns recursos novos que ampliam as possibilidades de uso dos componentes EJB, especialmente o novo tipo de componente Singleton Bean.
Um ponto importante que pode ser percebido com o advento da especificação da nova tecnologia, bem como com a motivação da comunidade, é a forte preocupação com a simplicidade de uso. Agora, as interfaces passam a ser opcionais, há a possibilidade de chamadas assíncronas de forma simplificada e pode-se implantar EJBs na camada web.
Adicionalmente, há a possibilidade de se utilizar EJBs no ambiente Java SE e também contar com versões mais leves de servidores (EJB Lite).
Este artigo apresenta os novos recursos disponíveis na tecnologia Enterprise Java Beans 3.1. Foi realizado um estudo da especificação (JSR 318) de modo a cobrir e esclarecer tais novidades, com a preocupação de fornecer exemplos reais e apresentar dicas baseadas na experiência com a arquitetura Java EE.
Para aqueles que já conhecem EJBs, é uma ótima oportunidade de se atualizar, para os que estão iniciando, é um momento igualmente oportuno, afinal, o uso dessa tecnologia está mais fácil do que nunca.
Dentre as inovações trazidas pela nova tecnologia, esse artigo destacará:
Não deixe de ler nessa edição a entrevista sobre Java EE 6 e EJB 3.1 realizada no JavaOne 2009 com o especialista Reza Rahman.
Java EE é a plataforma Java para criação de aplicações web e aplicações corporativas distribuídas de larga escala (com uso de EJBs). Essa tecnologia possui uma série de aspectos para a criação de sistemas de qualidade, tais como: segurança, performance, distribuição, concorrência (multi-threading), escalabilidade, controle transacional, persistência e outras tantas necessidades arquiteturais. A idéia central é que o desenvolvedor deve se preocupar apenas com a regra de negócio e com a aplicação, deixando que a plataforma Java EE cuide da infra-estrutura. Com ela é possível criar aplicações de forma independente de plataforma e de servidor, obtendo o que se chama de WODA (Write Once Deploy Anywhere), ou seja, você escreve a aplicação uma única vez e implanta em qualquer servidor compatível.
Java EE 6 (JSR 316) possui recursos promissores que inovam ainda mais a plataforma tanto no mundo web quanto EJB, e é claro, com o compromisso de manter a compatibilidade com as versões anteriores. Essa é uma especificação guarda-chuva, ou seja, relaciona outras especificações, sendo que em todas há a preocupação de simplificar ainda mais o trabalho de desenvolvimento e implantação das aplicações.
Enterprise Java Beans (EJBs) é a tecnologia Java padronizada para a criação de componentes em uma arquitetura distribuída, escalável, confiável e robusta. Em uma aplicação n-camadas com esse tipo de necessidade arquitetural, usualmente utiliza-se EJBs para a camada de negócios. Para executar uma aplicação que utiliza EJBs é necessário um servidor de aplicação, o qual é chamado de contêiner.
Uma das principais e recentes mudanças ocorridas no EJB foi em sua versão 3.0, quando sua utilização se tornou mais simples e produtiva, mantendo todo o poder da tecnologia. Agora, com EJB 3.1 (JSR 318) a curva de aprendizado se torna ainda mais rápida e há recursos que prometem alavancar ainda mais o seu uso.
O Glassfish é um servidor de aplicações Java EE maduro, robusto e livre. É a implementação de referência para a especificação do EJB 3.0, e agora do EJB 3.1, em sua versão V3. Todos os códigos aqui tratados já podem ser codificados e testados com o Glassfish. Mas é necessário utilizar uma versão recente (promoted build ou nightly build). A versão aqui utilizada foi a b57, que vem junto com o NetBeans 6.8 M1.
Nos tópicos a seguir serão apresentadas as principais novidades do EJB. A versão 3.1 vem recheada de novidades e melhorias que tornam a tecnologia mais poderosa, produtiva e fácil de aprender. Esse artigo procura detalhar cada um desses novos recursos, com exemplos de código e dicas importantes.
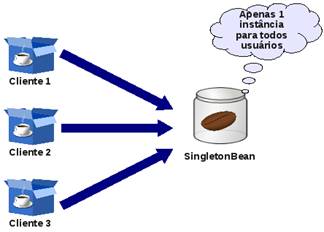
Esse tipo de componente EJB segue os preceitos do Design Pattern Singleton, cuja responsabilidade é garantir que exista somente uma instância de uma classe na aplicação. O componente Singleton Bean garante que apenas uma instância do componente existirá e será compartilhada por todos os usuários da aplicação (Figura 1), e o que é melhor, com toda a infra-estrutura fornecida pelo contêiner, como nos demais componentes EJB. Segundo a especificação, em um ambiente distribuído haverá uma instância por JVM, o que merece um pouco de atenção.
Em muitos cenários há a necessidade de armazenar informações de forma compartilhada a todos os usuários da aplicação. Para isso, na web há o escopo de application, já com EJBs não havia um modo. Uma das formas seria utilizar uma classe Java simples (POJO) contendo atributos estáticos, mas daí surge uma questão: como fica o acesso concorrente (multi-threading) a essas informações, segurança, transação e outros tantos serviços fornecidos pelo contêiner? Singleton Beans se aplicam muito bem a essa necessidade.
Para criar um EJB como Singleton Bean basta utilizar a annotation @Singleton na classe do componente. Veja um exemplo simples na Listagem 1.
package br.com.globalcode.ejb31;
import javax.ejb.Singleton;
@Singleton
public class SingletonHelloBean implements SingletonHelloRemote {
public String getMessage() {
return "Hello. Welcome to Singleton EJB 3.1 World.";
}
}Outro recurso muito interessante do Singleton Bean é a possibilidade de capturar eventos de callback no âmbito da aplicação, ou seja, executar operações na inicialização e no encerramento de sua aplicação. Para executar uma operação durante a inicialização basta usar a annotation @PostConstruct em algum método desejado para esse propósito, já para o evento de encerramento deve-se utilizar a annotation @PreDestroy. Observe um exemplo desse recurso na Listagem 2.
package br.com.globalcode.ejb31;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import javax.ejb.Singleton;
@Singleton
public class CallbackHelloBean implements CallbackHelloRemote {
private String message;
@PostConstruct
public void initialization() {
Logger.getLogger(CallbackHelloBean.class.getName()).log(Level.INFO, "***** Starting EJB 3.1 Sample App *****", (Object) null);
message = "Hello. Welcome to Singleton EJB 3.1 with Callback methods World";
}
@PreDestroy
public void shutdown() {
Logger.getLogger(CallbackHelloBean.class.getName()).log(Level.INFO, "***** Stopping EJB 3.1 Sample App *****", (Object) null);
}
public String getMessage() {
return message;
}
}Um possível cenário para o uso de Singleton Bean seria compartilhar informações do banco de dados, mantidas em memória, para todos os clientes. Sem o recurso de callback, uma estratégia seria carregar as informações na primeira chamada de método ao componente (lazy loading), mas se o processo demorasse cinco minutos o primeiro usuário teria que aguardar esse tempo.
Usando o novo recurso você pode carregar informações antes da primeira chamada a algum componente EJB. No exemplo da Listagem 2 não há garantia de que esse evento ocorra exatamente na inicialização. Nesse caso, o contêiner garante apenas que o evento de inicialização ocorra em algum momento após a aplicação ter sido carregada (após o deploy da aplicação ou inicialização do servidor) e antes de qualquer chamada de método, o que pode demorar algum tempo. Opcionalmente, para garantir a execução do método anotado com @PostConstruct de forma imediata durante a inicialização (eager initialization), deve-se adicionar a annotation @StartUp na classe do componente (Listagem 3).
package br.com.globalcode.ejb31;
...
import javax.ejb.Startup;
...
@Startup
@Singleton
public class EagerCallbackHelloBean implements EagerCallbackHelloRemote {
...
@PostConstruct
public void initialization() {...}
...
}Também é possível determinar a ordem na qual os Singleton Beans serão inicializados. Para isso, utiliza-se a annotation @DependsOn na classe do bean, informando quais outros beans precisam ser inicializados primeiro.
Veja um exemplo que utiliza essa annotation na Listagem 4. Nesse código o contêiner irá garantir que o SingletonA será inicializado antes do SingletonB e esse antes do SingletonC.
@Singleton
public class SingletonA {
@PostConstruct
public void initialization() {...}
}
@DependsOn(“SingletonA”)
@Singleton
public class SingletonB {
@PostConstruct
public void initialization() {...}
}
@DependsOn({“SingletonB”})
@Singleton
public class SingletonC {
@PostConstruct
public void initialization() {...}
}Por padrão, um Singleton Bean é thread-safe, o que significa que cada um de seus métodos possui acesso sincronizado, em outras palavras, se múltiplas chamadas a métodos do bean ocorrerem ao mesmo tempo apenas uma por vez será executada.
Existem cenários nos quais isso não é desejado, por exemplo, os dados são compartilhados apenas para consulta. Nesse caso, existe a annotation @Lock, que permite escolher o modo de concorrência (LockType). Quando não for especificado, o padrão será equivalente a @Lock(LockType.WRITE) que, como explicado no início desse parágrafo, indica acesso sincronizado. Se utilizar @Lock(LockType.READ) o acesso concorrente é permitido, ou seja, múltiplas chamadas executarão simultaneamente, o que é útil nos cenários apenas de consulta, ou de forma geral, quando os dados e operações não são sensíveis à concorrência. A annotation @Lock pode ser utilizada nos métodos ou na classe, quando utilizada na classe se aplica a todos os métodos.
Na Listagem 5 há um exemplo real que incorpora os principais recursos de um Singleton Bean. Esse exemplo serve como solução para um cenário no qual se deseja garantir que, em uma única instalação, deverá haver apenas uma instância da entidade Empresa (sistema mono-empresa).
package br.com.globalcode.ejb31realsamples;
import javax.annotation.PostConstruct;
import javax.ejb.Lock;
import javax.ejb.LockType;
import javax.ejb.Singleton;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
@StartUp
@Singleton
public class EmpresaServiceBean implements EmpresaServiceRemote {
@PersistenceContext
private EntityManager em;
private Empresa empresa;
@PostConstruct
private void carregarEmpresa() {
empresa = em.find(Empresa.class, new Integer(1));
}
@Lock(LockType.WRITE)
public void atualizarEmpresa(Empresa empresa) {
empresa.setId(1);
empresa = em.merge(empresa);
}
@Lock(LockType.READ)
public Empresa getEmpresa() {
return empresa.clone();
}
}Nesse código apenas uma instância do componente EmpresaServiceBean existirá. O método carregarEmpresa() será executado imediatamente após a inicialização da aplicação, o método atualizarEmpresa() possui acesso sincronizado e o método getEmpresa() aceita acesso concorrente.
Para a concorrência também é possível utilizar a annotation @AccessTimeout, a fim de determinar o tempo máximo que uma chamada ao método deverá aguardar em caso de lock (existe outra chamada em andamento que não liberou o lock). Ao ocorrer o timeout será lançada uma exceção do tipo javax.ejb.ConcurrentAccessTimeoutException.
Assim como nos demais tipos de EJBs, é possível controlar e demarcar transações usando as annotations @TransactionManagement e @TransactionAttribute, como se faz com EJB 3.0. Além disso, tudo que pode ser feito por meio de annotations pode ser realizado através dos tradicionais deployment descriptors, úteis quando se deseja alterar o comportamento da aplicação sem ter que recompilar o código.
No EJB 3.1 o uso de interfaces se tornou opcional com o propósito de simplificar o uso de EJBs.
Anteriormente, com os EJBs 2.x, para criar um EJB era necessário criar interfaces home e de componente, que podiam ser locais ou remotas e tinham muitas particularidades em sua criação, além da necessidade de implementar interfaces de beans (por exemplo, javax.ejb.SessionBean que exige os métodos ejbXXX()). No EJB 3.0, a interface home já havia deixado de ser necessária e as interfaces de componente, obrigatórias, se tornaram interfaces Java simples (business interface), o que simplificou muito seu uso.
Como mencionado, agora com EJB 3.1, o uso de interface não é mais obrigatório. Isso pode gerar alguns questionamentos: a interface não é importante? Não devo usar mais interfaces? E as vantagens do uso de interfaces, como flexibilidade e baixo acoplamento? Um componente de negócio não deve ter uma interface?
O uso de interfaces é altamente recomendado e você irá utilizá-las nos componentes de negócio exatamente como no EJB 3.0. O propósito de torná-las opcionais é facilitar a criação de componentes para quem está iniciando com EJBs ou até mesmo para não obrigar o uso de interfaces quando não for necessário. Imagine utilizar um EJB como controller ou um action na camada web (chamado por um Servlet FrontController, por exemplo). Como as interfaces passaram a ser opcionais para EJBs, você pode utilizá-las apenas quando considerar aplicável, o que não era possível nas versões anteriores. Vale salientar que agora também é possível adicionar EJBs diretamente na camada web (.war). Nesse cenário é muito provável que se utilize EJBs sem necessitar de uma interface, como pode ser visto na Listagem 6. Observe que a classe não implementa nenhuma interface.
package br.com.globalcode.ejb31realsamples;
import java.util.ArrayList;
import java.util.List;
import javax.ejb.Stateful;
@Stateful
public class CarrinhoDeComprasBean {
private List<Produto> produtos = new ArrayList<Produto>();
public void addProduto(Produto produto) {
produtos.add(produto);
}
}Este é outro recurso que trouxe grandes novidades. O uso da Timer Service API ficou muito mais simples e poderoso.
A criação de operações agendadas com Timer Service no EJB 3.0 é mais simples do que com EJB 2.x, mas é limitado em relação às reais necessidades das aplicações e o agendamento somente pode ser feito programaticamente. Veremos mais sobre tais limitações neste artigo. O agendamento com EJB 3.1 é muito mais completo e permite sua criação através de annotations (ou Deployment Descriptor) com um estilo similar ao Unix cron.
Veja na Listagem 7, primeiramente, como utilizar o recurso com EJB 3.0. Note que o método agendar() realiza um agendamento programaticamente. Esse método precisa ser chamado manualmente para que o agendamento seja efetivamente registrado no contêiner. No momento configurado, 5h30m diariamente, o método anotado com @Timeout será chamado pelo contêiner.
package br.com.globalcode.ejb31realsamples;
import java.io.Serializable;
import java.util.Calendar;
import java.util.Date;
import java.util.List;
import javax.annotation.Resource;
import javax.ejb.EJB;
import javax.ejb.Stateless;
import javax.ejb.Timeout;
import javax.ejb.TimerService;
@Stateless
public class FaturamentoService30Bean implements FaturamentoService30Remote {
@EJB
private VendasServiceRemote vendasService;
@Resource
private TimerService timerService;
public void agendar() {
Serializable info = null;
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.HOUR_OF_DAY, 5);
calendar.set(Calendar.MINUTE, 30);
calendar.set(Calendar.SECOND, 0);
long intervalo = 24L * 60 * 60 * 1000;
Date inicio = calendar.getTime();
timerService.createTimer(inicio, intervalo, info);
}
@Timeout
private void gerarNotasFiscaisDoDia() {
//simulação
List<Pedido> pedidos = vendasService.getPedidosComEntregaParaHoje();
for (Pedido pedido : pedidos) {
gerarNotaFiscal(pedido);
}
}
private void gerarNotaFiscal(Pedido pedido) {
//simula uma geração de Nota Fiscal
}
}O modelo de agendamento do EJB 3.0 funciona muito bem apenas para os casos nos quais a tarefa deve ser executada apenas uma vez ou em ciclos bem definidos, por exemplo, a cada dia, hora, minuto, segundo ou semanalmente. Por causa disso, existem outros requisitos que não são cobertos, tais como:
Com o agendamento do EJB 3.0 é muito complexo atender a essas necessidades, mas o novo mecanismo do EJB 3.1 inovou, permitindo os chamados Calendar-based Timers.
O modelo definido pelo EJB 3.1 também é chamado de Automatic Timer, conforme a especificação. Seu uso é relativamente simples, de forma que, basta criar um método em um componente EJB e marcá-lo com a annotation @Schedule.
Esse método deve respeitar as seguintes características:
A sua sintaxe é [public | protected | default] void <nome-método>( [Timer timer] ).
Após o deploy do componente, o método demarcado com essa annotation será executado no intervalo determinado.
Cumpre observar que, conforme a especificação, não é possível criar um agendamento para o método de um stateful session bean. Essa característica ainda poderá ser adicionada em uma versão futura, conforme também denota a especificação.
O segredo para o uso deste recurso é o entendimento de como utilizar a annotation @Schedule. A Tabela 1 descreve os principais atributos dessa annotation e seus valores.
|
Atributo |
Descrição |
Valores |
|
second |
Utilizado para definir um ou mais segundos de um minuto. |
[0,59] Valor Padrão: “0” – segundo 0 do minuto. |
|
minute |
Utilizado para definir um ou mais minutos de uma hora. |
[0,59] Valor Padrão: “0” – minuto 0 da hora. |
|
Hour |
Utilizado para definir uma ou mais horas de um dia. |
[0,23] Valor Padrão: “0” – hora 0 do dia. |
|
dayOfMonth |
Utilizado para definir um ou mais dias de um mês. |
[1,31] [-7, -1] – utilizado para indicar n dias antes do último dia do mês. Last – utilizado para indicar o último dia do mês. {x y}onde x = {"1st", "2nd", "3rd", "4th", "5th", "Last"} y = {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"} Utilizado para indicar uma única ocorrência de um dia de semana no mês. Ex.: "2nd Sat" – Segundo sábado do mês. Valor Padrão: "*" – todos os dias do mês. |
|
month |
Utilizado para definir um ou mais meses de um ano. |
[1,12] {"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", Dec"} Valor Padrão: "*" – todos os meses do ano. |
|
dayOfWeek |
Utilizado para definir um ou mais dias de uma semana. |
[0,7] {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"} 0 e 7 significam Domingo. Valor Padrão: "*" – todos os dias da semana. |
|
Year |
Utilizado para definir um ano em particular. |
Ano com quatro dígitos. Valor Padrão: "*" – todos os anos. |
Com a combinação desses atributos são inúmeras as possibilidades de agendamento. Porém, antes de apresentar alguns exemplos é importante conhecer como atribuir os valores para cada atributo. A Tabela 2 relaciona as possíveis formas de atribuição.
|
Forma de atribuição |
Exemplos |
|
Valor simples |
hour="10" – às 10:00h da manhã dayOfWeek="Fri" – às sextas dayOfWeek="5" – às sextas dayOfMonth="1st Sun" – primeiro domingo do mês month="Jan" – no mês de Janeiro month="1" – no mês de Janeiro year="2009" – no ano de 2009 |
|
Faixa de valores |
minute="1-5" – nos cinco primeiros minutos da hora dayOfWeek="Mon-Fri" – de segunda a sexta dayOfMonth="1-15" – nos primeiros 15 dias do mês |
|
Lista de valores |
second="15,45" – nos segundos 15 e 45 minute="1-5, 30, 55" – nos minutos de 1 a 5, 30 e 55 dayOfWeek="Mon, Fri, Sun" – segunda, sexta e domingo |
|
Wild card |
* indica todos os possíveis valores para o atributo minute="*" – todos os minutos hour="*" – todas as horas month="*" – todos os meses |
|
Incrementos |
Segue a sintaxe x/y, onde x significa início e y frequência. Em x pode-se usar * significando 0. Esta notação somente é aceita para segundos, minutos e horas. second="*/20" – nos segundos 0, 20 e 40 second="5/20" – nos segundos 5, 25 e 45 minute="45/5" – nos minutos 45, 50 e 55 |
Observe alguns exemplos de como utilizar o agendamento baseado em calendário na Tabela 3.
|
Agendamento |
Código |
|
Toda sexta-feira à meia-noite |
@Schedule(dayOfWeek="Fri") |
|
Todo dia útil |
@Schedule(dayOfWeek="Mon-Fri") |
|
A cada hora todos os dias |
@Schedule(hour="*") |
|
A cada 30 minutos todos os dias, iniciando no minuto 0 ou 30 |
@Schedule(hour="*/30") ou @Schedule(minute="0, 30", hour="*") |
|
Todo dia 5 e dia 20 às 09:00h |
@Schedule(hour="9", dayOfMonth="5,20") |
|
No último dia do mês e no dia 15 às 08:00h |
@Schedule(hour="8", dayOfMonth="Last, 15") |
|
Todo dia das mães |
@Schedule(dayOfMonth="2nd Sun", month="May") |
|
No primeiro dia do mês às 06:30h |
@Schedule(minute="30", hour="6", dayOfMonth="1st") |
|
No penúltimo dia do mês às 23:00h |
@Schedule(hour="23", dayOfMonth="-1") |
|
Na última sexta-feira de cada mês às 19:00h |
@Schedule(hour="19", dayOfMonth="Last Fri") |
|
Toda sexta-feira 13 |
@Schedule(dayOfMonth="13", dayOfWeek="Fri") |
Além de todas as possibilidades apresentadas na Tabela 3, é possível combinar mais de um agendamento para um mesmo método. Para isso utiliza-se a annotation @Schedules. Por exemplo, de segunda a quinta-feira às 8:00h e às 18:00h e sexta-feira às 8:00h e às 17:00h:
@Schedules( {
@Schedule(hour="8, 18", dayOfWeek="Mon-Thu"),
@Schedule(hour="8, 17", dayOfWeek="Fri")
} )Também é possível especificar o fuso horário através do atributo timeZone. Por exemplo, todo os dias às 19:00h, horário de São Paulo (horário de Brasília):
@Schedule(hour="19", timezone="America/Sao_Paulo")Observe um exemplo de código mais completo envolvendo agendamento na Listagem 8.
package br.com.globalcode.ejb31realsamples;
import java.util.List;
import javax.ejb.EJB;
import javax.ejb.Schedule;
import javax.ejb.Stateless;
@Stateless
public class FaturamentoServiceBean implements FaturamentoServiceRemote {
@EJB
private VendasServiceRemote vendasService;
@Schedule(hour = "5", minute = "30", dayOfMonth = "*")
private void gerarNotasFiscaisDoDia() {
List<Pedido> pedidos = vendasService.getPedidosComEntregaParaHoje();
for (Pedido pedido : pedidos) {
gerarNotaFiscal(pedido);
}
}
private void gerarNotaFiscal(Pedido pedido) {
//simula uma geração de Nota Fiscal
}
}Por padrão, um Timer é persistente, o que significa que ele sobrevive a falhas, ao encerramento da aplicação (shutdown) e a eventos como passivation/activation ou load/store. Para modificar esse comportamento deve-se utilizar o atributo persistent com valor false, por exemplo:
@Schedule( ..., persistent=false)A anotação @Schedule aceita ainda uma String como informação adicional através do atributo info, o que pode ser útil caso haja múltiplos agendamentos em uma classe e seja preciso identificar qual agendamento foi disparado. No caso, ficaria:
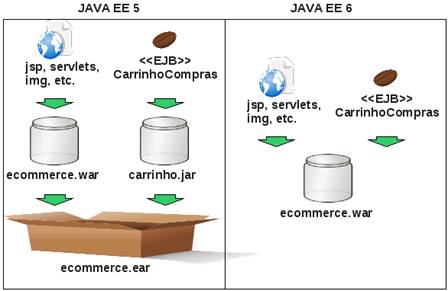
@Schedule( ..., info="TimerRelatorioSemanal")A tecnologia Java EE 5, que inclui EJB 3.0, define uma estrita modularização de seus componentes. Ela determina que uma aplicação web deve ser empacotada dentro de um arquivo .war, EJBs dentro de um .jar com conteúdo específico e uma aplicação enterprise em um .ear que, de modo geral, empacota arquivos .jar e .war.
Essa modularização continua sendo recomendada para aplicações n-camadas. Entretanto, para aplicações Web-centric esse processo pode ser um tanto quanto burocrático, dificultando a utilização de EJBs em uma aplicação com essa arquitetura.
Tal necessidade motivou a possibilidade, com EJB 3.1, de se empacotar EJBs diretamente no arquivo .war da aplicação web, como pode ser visto na Figura 2.
Há duas formas de realizar esse procedimento: a primeira consiste em empacotar classes de componentes EJB dentro da pasta WEB-INF/classes do .war, a segunda alternativa consiste em adicionar um .jar contendo EJBs dentro da pasta WEB-INF/lib. Vale salientar que esse .jar não se refere a um módulo EJB, mas sim a um .jar convencional.
De acordo com a especificação, um pacote .war deve conter no máximo um ejb-jar.xml, que, por sua vez, é opcional. Esse arquivo, se existir, deverá ser colocado ou na pasta WEB-INF do .war ou na pasta META-INF do .jar da pasta WEB-INF/lib.
Além das características já mencionadas, um EJB empacotado dentro de um .war deve possuir as mesmas exigências de Class Loading e compartilhar o mesmo Component Environment Namespace. Isso garante que um componente web terá acesso a esse EJB e vice-versa. Além disso, esse EJB terá acesso a todos os componentes registrados no serviço de nomes tal qual um componente web. Por existir o compartilhamento, deve-se tomar cuidado apenas para que o nome do componente não conflite com o nome de outro componente ou recurso já registrado no namespace da aplicação web, algo que não é necessário ao se utilizar um módulo EJB independente.
Até a versão EJB 3.0, a única forma de se criar um mecanismo de chamadas assíncronas era através de Message Driven Beans (MDBs), que é uma ferramenta poderosa, confiável e tolerante a falhas de middleware orientado a mensagens (MOM). MDB se aplica muito bem ao modelo de chamadas assíncronas, contudo, há certo nível de complexidade ao se trabalhar com filas de mensagens. A tecnologia geralmente utilizada para essas filas é JMS. Em determinados cenários, nos quais se deseja apenas o modelo de chamada assíncrona, o uso de MDBs pode ser trabalhoso, principalmente nos casos em que a tolerância a falhas e outras garantias inerentes a filas de mensagens não são necessárias.
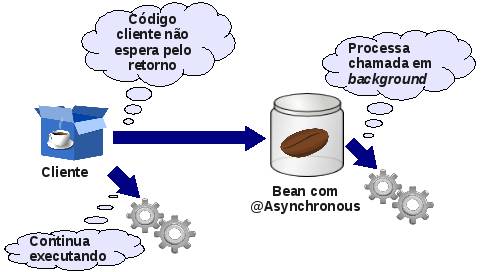
Com o propósito de permitir chamadas assíncronas de forma simplificada, no EJB 3.1 há a possibilidade de demarcar métodos como assíncronos através do uso da annotation @Asynchronous (ou através do deployment descriptor). Essa demarcação pode ser feita para os métodos da classe do componente, para a própria classe, para os métodos das interfaces ou nas próprias interfaces. Quando aplicado à classe ou interface, todos os seus respectivos métodos serão tratados como assíncronos.
Em uma chamada convencional (síncrona) o código chamador aguarda o método chamado terminar sua execução para prosseguir. Com a chamada assíncrona (Figura 3), enquanto o método executa em uma thread separada, o código chamador continua executando sem aguardar pelo resultado, o que permite criar chamadas com certo grau de paralelismo e/ou permitir que o usuário interaja com a interface gráfica, enquanto o método chamado de um enterprise bean continua executando.
O desenvolvedor deverá levar em conta que, para um método assíncrono, o tipo de retorno deve ser void ou Future<V>.
No caso de um método com retorno void, não há nenhuma forma pela qual o componente possa devolver um valor para quem o chamou, claro, é void, mas o detalhe importante é que esse método não pode lançar nenhuma Application Exception, pois nesse caso não há como ela ser propagada.
No segundo caso, provavelmente menos comum que o primeiro, o método retorna um objeto que implementa a interface java.util.concurrent.Future<V>, onde V indica um tipo de objeto parametrizado para a interface (uso de generics). Esse objeto permite o retorno de forma assíncrona, que o cliente poderá obter em algum momento futuro.
Além da obtenção do retorno, o objeto Future permite que Application Exceptions sejam propagadas e obtidas pelo código cliente. Ao criar o método com esse tipo de retorno o desenvolvedor deverá devolver uma instância de javax.ejb.AsyncResult<V>.
Nas Listagens 9, 10, 11 e 12 há alguns trechos de código que denotam a criação de métodos que permitirão a chamada assíncrona.
@Session
public class FaturamentoServiceBean implements FaturamentoServic {
@Asynchonous
public void efetuarPagamento() {
...
}
}@Session
@Asynchonous
public class FaturamentoServiceBean implements FaturamentoServic {
public void efetuarPagamento() {...} //Assíncrono
public void emitirNotaFiscal() {...} //Assíncrono
}
@Stateless
public class HelloBean implements HelloRemote {
@Asynchronous
public Future<String> lerMensagem() {
return new AsyncResult<String>("Hello World.");
}
} @Session
public class GerenciadorPedidosBean implements GerenciadorPedidos {
@Asynchonous
public Future<StatusPedido> efetuarPedido() {
StatusPedido status = ...
return new AsyncResult<StatusPedido>(status);
}
}Ao utilizar a annotation @Asynchronous no método da interface não é necessário especificar o retorno Future no método da classe, pois nesse caso o contêiner encapsula o objeto AsyncResult automaticamente. Entretanto, como a assinatura ficaria diferente, não se pode implementar a interface diretamente, mas sim utilizar a annotation @Remote ou a @Local. As Listagens 13 e 14 mostram como ficam a interface e a classe do componente, respectivamente.
@Remote
public interface GerenciadorPedidos {
@Asynchronous
public Future<StatusPedido> efetuarPedido();
}@Session
@Remote(GerenciadorPedidos.class)
public class GerenciadorPedidosBean {
public StatusPedido efetuarPedido() {
StatusPedido status = ...
return status;
}
}Do ponto de vista do cliente do componente, ao efetuar uma chamada de forma assíncrona, o desenvolvedor pode utilizar o objeto Future<V>, se retornado, para:
O objeto Future<V> retornado não é exatamente o mesmo retornado pelo EJB, mas sim uma instância gerada pelo contêiner, ou seja, não é a mesma referência. Isso se deve ao fato de que, quem gerencia as chamadas aos EJBs é o contêiner, sendo assim ele irá prover a infra-estrutura necessária para que o objeto Future seja retornado a quem o chamou. Portanto, o desenvolvedor deve considerar que a informação desejada será obtida de forma transparente, não importando a implementação de Future<V>.
Considere a seguinte chamada assíncrona:
Future<StatusPedido> future = gerPedidos.efetuarPedido();Para se obter o valor de retorno é necessário chamar o método get() no objeto Future. Se o retorno ainda não estiver pronto o método get() ficará esperando. Além disso, se esse método retornar uma Application Exception, deve-se utilizar um bloco try/catch e capturar a exceção java.util.concurrent.ExecutionException, conforme a Listagem 15.
try {
StatusPedido status = future.get();
} catch (InterruptedException ex) {
...
} catch (ExecutionException ex) {
Throwable appEx = ex.getCause(); //Exception original
...
}Através da chamada ao método boolean cancel(boolean mayInterruptIfRunning), do objeto Future, é possível solicitar um cancelamento de uma chamada assíncrona. Se esse método retornar false significa que o cancelamento não é mais possível, ou depende do bean, pois a tarefa já iniciou sua execução. Nesse caso, pode-se efetuar essa chamada passando no parâmetro mayInterruptIfRunning o valor true, para que, mesmo assim, efetue-se uma tentativa de cancelamento. Essa última forma só é possível se o código do bean for implementado de forma adequada, como na Listagem 16, cujo código utiliza o método context.wasCancelCalled() a fim de se testar se o cancelamento foi efetuado com mayInterruptIfRunning=true e abortar sua execução.
@Resource
private SessionContext ctx;
...
@Asynchronous
public Future<String> metodo() {
...
if (ctx.wasCancelCalled()) {
...
}
}A chamada assíncrona apenas coloca o método em um estado pronto para execução dentro de uma nova thread. A partir daí, a responsabilidade é do contêiner, ou seja, é ele quem controla a execução desse método.
Confira nas Listagens 17 e 18 um exemplo de código real que envolve um cenário de processamento de pagamentos. Nele, o método simularUmaTransacao() simula uma transação financeira, por exemplo, de cartão de crédito, que demora um certo tempo para concluir, justificando a necessidade de uma chamada assíncrona.
package br.com.globalcode.ejb31realsamples;
import java.util.concurrent.Future;
import javax.ejb.Asynchronous;
import javax.ejb.Remote;
@Remote
public interface PagamentoServiceRemote {
public Future<StatusPagamento> confirmarPagamento(InfoPagamento infoPagamento);
@Asynchronous
public Future<StatusPagamento> processarPagamento(InfoPagamento infoPagamento);
}package br.com.globalcode.ejb31realsamples;
import java.util.concurrent.Future;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.ejb.AsyncResult;
import javax.ejb.Asynchronous;
import javax.ejb.Remote;
import javax.ejb.Stateless;
@Stateless
@Remote(PagamentoServiceRemote.class)
public class PagamentoServiceBean {
public StatusPagamento processarPagamento(InfoPagamento infoPagamento) {
simularUmaTransacao(infoPagamento);
return StatusPagamento.AGUARDANDO_CONFIRMACAO;
}
@Asynchronous
public Future<StatusPagamento> confirmarPagamento(InfoPagamento infoPagamento) {
simularUmaTransacao(infoPagamento);
return new AsyncResult<StatusPagamento>(StatusPagamento.OK);
}
private void simularUmaTransacao(InfoPagamento infoPagamento) {
for (int i = 0; i < 30; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException ex) {
Logger.getLogger(ConfirmacaoPagamentoServiceBean.class.getName())
.log(Level.SEVERE, null, ex);
}
}
}
}Mais detalhes podem ser obtidos no JavaDoc da interface java.util.concurrent.Future.
As chamadas assíncronas não substituem os MDBs ou filas de mensagens, são apenas uma forma mais simplificada, como já mencionado. Em cenários de alta confiabilidade e escalabilidade prefira o uso de MDBs.
Esse recurso simplifica muito a criação de aplicações clientes de EJBs, pois permite a portabilidade sem muito esforço.
Ao desenvolver aplicações distribuídas, podem ocorrer certas situações nas quais se faça necessário o lookup dos componentes remotos de forma programática, por exemplo, em um Service Locator ou um cliente Desktop. Nessas situações não há o recurso de injeção de dependência. Para compreender melhor o benefício dessa padronização é preciso entender o problema.
Context context = new InitialContext();
Object o = context.lookup("app/GerenciadorPedidosBean/remote");
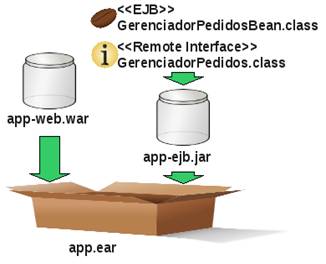
GerenciadorPedidos gerPedidos = (GerenciadorPedidos) o;Considere os trechos de código das Listagens 20 e 21 e leve em conta a estrutura de deploy da Figura 4. Nessa figura é apresentada uma estrutura tradicional de empacotamento de componentes em uma aplicação Java EE, na qual os componentes web são empacotados no arquivo app-web.war, a classe do EJB (GerenciadorPedidosBean) e sua interface remota (GerenciadorPedidos) são empacotadas no arquivo app-ejb.jar e esses arquivos, por sua vez, são empacotados no arquivo app.ear.
package br.com.globalcode.ejb;
@Stateless(name="GerenciadorPedidos") //name seria GerenciadorPedidosBean se não especificado
public class GerenciadorPedidosBean implements GerenciadorPedidos {...}package br.com.globalcode.ejb;
@Remote
public interface GerenciadorPedidos {...}A Tabela 4 relaciona o nome JNDI global do componente quando implantando em cada um dos principais contêineres de mercado. Observe que o nome utilizado por cada fabricante difere dos demais.
|
Servidor |
Nome JNDI Global (Não padronizado) |
|
JBoss |
"app/GerenciadorPedidosBean/remote" |
|
GlassFish |
"app/GerenciadorPedidosBean/remote" |
|
WebSphere |
"GerenciadorPedidos" |
|
OC4J |
"app-ejb/GerenciadorPedidosBean/GerenciadorPedidos" |
Ao utilizar injeção de dependência não há preocupação, pois o próprio servidor resolve a localização do componente desejado, através do atributo beanName. Exemplo:
@EJB(beanName="GerenciadorPedidos")
private GerenciadorPedidos gerenciadorPedidos;O principal problema ocorre quando é preciso efetuar um lookup programático, conforme o código da Listagem 19. Ao mudar a aplicação para um servidor de outro fabricante esse código deixa de funcionar. Para evitar esse problema existem alternativas, por exemplo, utilizar o namespace local (“java:comp/env”) e efetuar um mapeamento desse nome lógico para o nome físico do componente registrado no servidor. Mas, nesse caso, é necessário criar um deployment descriptor específico de fabricante, o que torna o processo muito trabalhoso. Existe ainda um atributo da annotation que define o bean (@Stateless, por exemplo) denominado mappedName, mas, conforme a especificação de EJB 3.0, ele não é obrigatório, de forma que muitos fabricantes o ignoram.
Com o propósito de eliminar a necessidade de configurações específicas e permitir a portabilidade de uma forma ainda mais transparente, a nova especificação propõe três formatos de nomes. Ao implantar um componente o contêiner irá registrá-lo automaticamente com cada um desses nomes. A padronização utiliza a seguinte sintaxe para nomes JNDI globais:
java:global[/<app-name>]/<module-name>/<bean-name>[!<fully-qualified-interface-name>]
java:app[/<module-name>]/<bean-name>[!<fully-qualified-interface-name>]
java:module/<bean-name>[!<fully-qualified-interface-name>]Os elementos que compõe essa sintaxe são definidos por:
Reiterando, essa padronização se refere ao formato dos nomes que o contêiner utilizará para registrar os componentes EJB no momento da implantação. Vale salientar que, através de XMLs (Deployment Descriptors), os nomes JNDI podem ser alterados e seguir qualquer critério, mas isso não deve ser necessário ao se utilizar EJB 3.1.
Nos casos em que há apenas uma interface, o contêiner registra nomes adicionais no JNDI para cada uma dessas formas, sem preencher o parâmetro [!<fully-qualified-interface-name>]. Se não houver nenhuma interface esse parâmetro também é ignorado. Na existência de mais de uma interface será criada um nome adicional para cada uma. Note que um mesmo componente pode ser localizado através de diferentes nomes.
Para um melhor entendimento é necessário considerar as diferentes possibilidades de empacotamento de EJBs: .jar apenas, .jar dentro de um .ear, .war apenas, e .war dentro de um .ear. Em cada uma das situações o contêiner irá criar automaticamente um conjunto de nomes diferentes. Tome os códigos das Listagens 20 e 21 como base. Na sequência, são exibidos os nomes JNDI globais criados automaticamente pelo contêiner para cada tipo de empacotamento. Esses nomes poderão ser utilizados para efetuar o lookup de um modo compatível com qualquer contêiner.
Nomes JNDI para implantação do bean empacotado diretamente no app-ejb.jar:
java:global/app-ejb.jar/GerenciadorPedidos
java:global/app-ejb.jar/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:app/GerenciadorPedidos
java:app/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:module/GerenciadorPedidos
java:module/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidosNomes JNDI para implantação do bean empacotado no app-ejb.jar, que por sua vez é empacotado no app.ear:
java:global/app/app-ejb/GerenciadorPedidos
java:global/app/app-ejb/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:app/app-ejb/GerenciadorPedidos
java:app/app-ejb/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:module/GerenciadorPedidos
java:module/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidosNomes JNDI para implantação do bean empacotado diretamente no app-web.war:
java:global/app-web/GerenciadorPedidos
java:global/app-web/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:app/GerenciadorPedidos
java:app/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:module/GerenciadorPedidos
java:module/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidosNomes JNDI para implantação do bean empacotado no app-web.war, que por sua vez é empacotado no app.ear:
java:global/app/app-web/GerenciadorPedidos
java:global/app/app-web/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:app/app-web/GerenciadorPedidos
java:app/app-web/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidos
java:module/GerenciadorPedidos
java:module/GerenciadorPedidos!br.com.globalcode.ejb.GerenciadorPedidosAtualmente, o uso de lookups programáticos é desaconselhável para muitos cenários. Ao invés disso, recomenda-se o uso de injeção de dependência. Nesse caso, o nome no qual o componente é registrado ou localizado fica transparente.
EJB Lite é definido apenas como um subconjunto da EJB 3.1 API, não contendo nenhum tipo de API adicional. Sua motivação vem do fato de que nem toda aplicação que utiliza EJBs necessita de todos os recursos disponíveis em sua API, o que traz muitas vantagens. Uma delas é permitir que os fabricantes Java EE forneçam uma versão reduzida de seus servidores, minimizando a utilização de recursos e diminuindo o tempo de inicialização, ou ainda, novos fabricantes não precisam implementar todos os serviços para disponibilizar uma versão mínima que suporte EJBs. Com isso, é provável que haja mais empresas com servidores compatíveis com Java EE. De forma geral, EJB Lite é uma excelente alternativa para cenários mais simplificados que necessitem dessa tecnologia.
Conforme a especificação, o suporte a EJB Lite se limita (se é que se pode chamar de limitação com tantos recursos) a:
A API completa de EJB 3.1 define ainda outras exigências, mas que não fazem parte de EJB Lite, a saber:
Vale salientar que algumas tecnologias serão marcadas para remoção futura na especificação, conceito de pruning, indicando que nas próximas versões essas APIs se tornarão opcionais:
O objetivo dessa tecnologia é permitir o uso de EJBs no ambiente Java SE, o que pode ser muito útil em cenários de testes, processamentos batch e uso de EJBs em aplicações Desktop ou baseadas em Console.
A idéia é permitir a carga de um Embeddable Container, que, por sua vez, carregará os EJBs disponíveis no classpath da JVM. Esse tipo de contêiner é um ambiente para execução de EJBs utilizando apenas Java SE, ou seja, fora da plataforma Java EE. A forma de carregar esse tipo de contêiner é através do código:
EJBContainer ec =
javax.ejb.EJBContainer.createEJBContainer();É possível também configurar propriedades específicas, como por exemplo, definir quais módulos serão carregados.
Observe a Listagem 22, no caso apenas o módulo EJB app-ejb.jar é carregado, repare no uso da propriedade EJBContainer.EMBEDDABLE_MODULES_PROPERTY, dessa forma é possível controlar apenas os módulos EJB que serão carregados.
Properties props = new Properties();
props.setProperty(EJBContainer.EMBEDDABLE_MODULES_PROPERTY, “app-ejb”);
EJBContainer ec = EJBContainer.createEJBContainer(props);É possível configurar também as propriedades EJBContainer.EMBEDDABLE_INITIAL_PROPERTY para definir a classe que carregará o contêiner e EJBContainer.EMBEDDABLE_APP_NAME_PROPERTY para definir o nome da aplicação (<app-name>) que será utilizada para registrar os componentes no JNDI.
A especificação exige que os fabricantes forneçam suporte a EJB Lite em seus Embeddable Containers. Opcionalmente, o fabricante pode implementar a API completa de EJBs em seu ambiente embeddable.
Quanto à funcionalidade, o desenvolvedor pode contar com as mesmas características esperadas em contêineres tradicionais, limitadas a EJB Lite, o que aumenta ainda mais a portabilidade, ou seja, se o desenvolvedor não utilizar nenhum recurso muito avançado é possível executar os mesmos EJBs em um servidor de aplicação Java, em um servidor web Java ou até mesmo diretamente na JVM.
Na vídeo aula deste artigo apresentamos as novidades do EJB 3.1 na prática e também abordamos a integração entre JSF 2.0 e o EJB 3.1, destacando como ficou fácil criar componentes reutilizáveis
Os novos recursos de EJB 3.1 aqui apresentados são promissores e devem alavancar ainda mais a adoção da tecnologia, principalmente pela simplicidade de uso em situações nas quais, anteriormente, a aplicabilidade de EJBs poderia ser questionável. Verificando as evoluções da tecnologia e acompanhando as discussões da comunidade, é possível notar que há uma forte preocupação com a produtividade e em diminuir a curva de aprendizado para quem inicia na tecnologia.
Também, nota-se que há muito esforço em adequar os elementos mais comuns da API, relacionados por EJB Lite, para aplicações com arquitetura Web-centric ou Desktop, cenários nos quais o uso de EJBs não é utilizado atualmente.
Há muitos pontos de melhoria, ampliando a gama de possibilidades ao se utilizar EJBs, dentre eles: Singleton Bean, Timer Service, chamadas assíncronas e nomes JNDI globais.
Vale lembrar que os códigos aqui utilizados estão disponíveis no da Java Magazine. Basta descompactar o arquivo, instalar o NetBeans 6.8 M1 com o Glassfish V3, abrir os projetos e aproveitar. Nele há um conjunto de Hello Worlds implementados e funcionando, além de exemplos didáticos que foram criados para esse artigo.
Enfim, o que era bom ficou ainda melhor com EJB 3.1. Para aqueles que conhecem EJB, agora podem contar com uma tecnologia ainda mais poderosa. Para quem estiver iniciando, EJB ficou mais fácil de aprender!

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.