Naturalmente, à medida que introduzimos componentes para prover redundância a uma solução, aumentamos sua complexidade e potencialmente adicionamos uma sobrecarga para fazer estes componentes conversarem entre si, ou seja, ao melhorar a disponibilidade podemos estar comprometendo o tempo de resposta e o desempenho de uma aplicação.
Ao longo deste artigo vamos explorar como tirar o melhor proveito de soluções como o Apache Web Server e Hazelcast para construir um ambiente de alta disponibilidade que tenta extrair o melhor de cada uma das soluções com o objetivo de minimizar a sobrecarga ocasionada pelas mesmas.
Eventualmente uma aplicação ou sistema pode se tornar crítico a ponto de “nunca” poder parar. As razões pelas quais esses sistemas devem estar sempre disponíveis são as mais diversas, mas em geral pode-se dizer que há questões financeiras e/ou de segurança que podem ser impactadas por eventos de indisponibilidade.
Ao pesquisarmos na internet encontramos inúmeros casos internacionais reportando queda de ações de determinadas empresas devido à indisponibilidade dos sistemas das mesmas. Mas não precisamos ir tão longe para pesquisar por falhas em serviços de grandes corporações. Há alguns anos, mais precisamente em 2009, o sistema de pagamentos de uma grande rede brasileira de cartões de débito e crédito ficou algumas horas fora do ar nas vésperas do Natal, o que fez com que muitos consumidores optassem por utilizar cartões que eram aceitos pela máquina da empresa concorrente, que, coincidentemente ou não, bateu o recorde do volume de transações.
Garantir a disponibilidade de um sistema não é uma tarefa trivial, pois deve-se levar em conta aspectos que vão muito além de componentes de software, como redundância de partes elétricas e outros componentes de infraestrutura como links, firewalls, roteadores e assim por diante.
As primeiras tentativas de criar sistemas redundantes em Java eram extremamente complexas e confusas e em geral eram “amarradas” a servidores de aplicação e ao uso das primeiras encarnações dos EJBs, que apresentavam um modelo de publicação complicado e um modelo de desenvolvimento improdutivo.
Hoje temos à nossa disposição dezenas de frameworks que oferecem, além de alta disponibilidade, outros benefícios como escalabilidade e desempenho. Independentemente de qual framework seja adotado, em geral há características comuns que são inseridas quando se quer prover um ambiente de alta disponibilidade através da adição de servidores em redundância: a complexidade aumenta e há um overhead intrínseco que é introduzido por soluções que utilizam a rede como meio de comunicação.
Neste artigo vamos explorar alguns conceitos de infraestrutura envolvidos para construir um ambiente tolerante a falhas, porém focando principalmente no ponto de vista do Software, de forma a instruir o leitor em boas práticas na criação de aplicações que ofereçam alta disponibilidade, avaliando como podemos configurar alguns componentes em particular de maneira otimizada, minimizando o overhead ocasionado pela adição de mais servidores e frameworks de replicação de dados.
Nas próximas seções vamos mostrar como configurar o Apache para atuar como balanceador de carga bem como o Hazelcast, que atuará como solução de replicação da Sessão HTTP, porém primeiramente vamos discutir alguns dos principais conceitos envolvidos na construção desse tipo de ambiente.
A grosso modo, podemos dizer que um componente possui tolerância a falhas (FT-Fault Tolerance) se o mesmo puder continuar a oferecer seu serviço, mesmo de forma degradada, quando parte de seus subcomponentes encontrarem-se em falha. Para lidar com esse tipo de cenário, ou seja, prover FT a um componente, normalmente empregam-se técnicas de redundância, as quais, por sua vez, consistem em prover e configurar partes sobressalentes para os subcomponentes que fazem parte de um equipamento ou serviço.
Como sabemos, criar um ambiente com FT não é uma tarefa trivial e tende a se tornar cada vez mais complexa à medida que novos componentes ou serviços são introduzidos na arquitetura de um sistema. Com o objetivo de lidar com esse problema foi criada uma metodologia para avaliar subcomponentes suscetíveis a interrupções, conhecida como Análise de Ponto Único de Falha (SPOF, Analysis-Single Point of Failure Analysis). No geral, a sigla SPOF refere-se a um subcomponente ou serviço que, em caso de falha, poderá ocasionar a perda total de um componente ou sistema.
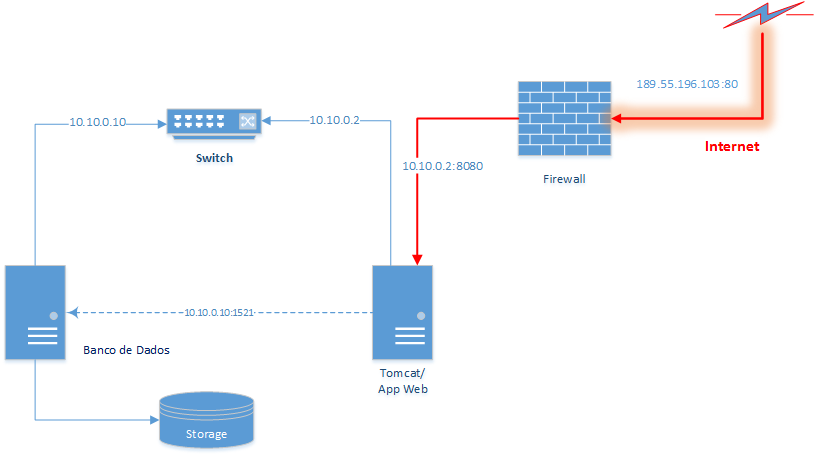
Para entender melhor esse conceito, consideremos o diagrama da Figura 1, que representa uma estrutura muito simplificada de um Data Center, sem qualquer redundância em seus serviços, o qual disponibiliza uma aplicação Web que pode ser acessada através da Internet.
Esse Data Center é formado apenas por seis componentes “macro”:
Uma requisição oriunda da Internet irá acessar aplicações web hospedadas no Data Center utilizando o endereço IP do Link Externo (189.55.196.103). Esta requisição chegará no Firewall, que redirecionará os acessos na porta 80 a este IP de Internet para o endereço do servidor Tomcat na rede interna (10.10.0.2:8080). Este, por sua vez, poderá se comunicar com um banco de dados pela mesma rede (10.10.0.10:1521).
Se olharmos de forma “macro” o diagrama da Figura 1, perceberemos que se qualquer um dos seis componentes falhar, o acesso às aplicações hospedadas nos servidores Tomcat não será mais possível. Por outro lado, ao olhar de forma “micro”, avaliando apenas os servidores de banco e web, notamos que os próprios servidores podem apresentar diversos SPOFs como, por exemplo:
Para eliminar estes SPOFs e introduzir FTs aos servidores é necessária uma mudança considerável na infraestrutura. No caso de fontes de alimentação, geralmente basta equipar os servidores com múltiplas fontes de energia que devem ser alimentadas por “tomadas” independentes. Para resolver o problema de falha nos discos, usualmente são empregadas técnicas de virtualização de armazenamento como RAID.
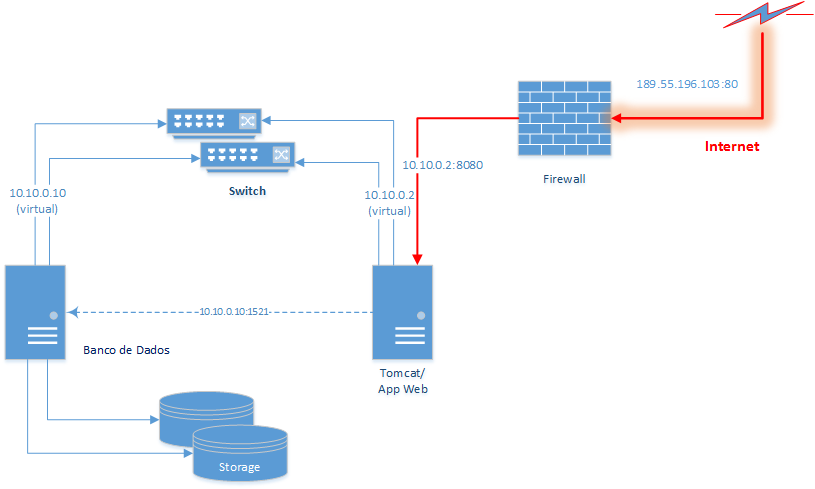
No caso de placas de rede, o problema é um pouco mais complicado, pois além de disponibilizar uma placa adicional é necessário fazer com que as duas interfaces de rede comportem-se como se fossem uma só, utilizando técnicas de virtualização de IP conhecidas como Network Bonding (veja a seção Links), que geralmente são oferecidas “out of the box” em algumas distribuições do Linux para servidor. Porém o problema não para por aí. Se não houver também redundância nos switches, apenas 50% do problema estará resolvido. Assim, para oferecer FT na rede seria necessário adquirir switches com a habilidade de funcionar em redundância e fazer a ligação de cada interface física de rede em um deles, como demonstra a Figura 2.
Com uma rede tolerante a falhas, resta eliminar os SPOF no Firewall e nos serviços lógicos. Para atacar o primeiro caso, além de modificar novamente a infraestrutura com a introdução de Firewalls atuando em redundância, dependemos da aquisição de um Link redundante, o que por sua vez requer uma estrutura de roteamento do fornecedor do Link. Já para eliminar os SPOF atrelados aos servidores de banco e Web, dependemos de soluções particulares para cada um.
No caso dos servidores de Web, que são o foco deste artigo, precisamos levar em conta duas questões para avaliar como vamos atacar o problema do SPOF:
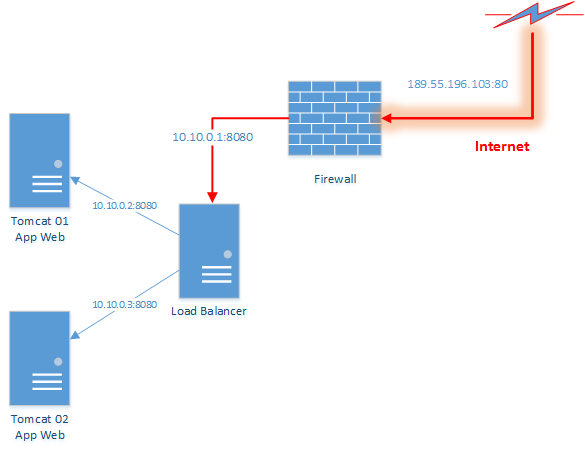
A primeira pergunta é respondida com uma técnica conhecida como balanceamento de carga (LB-Load Balancing), que consiste em colocar um appliance ou servidor entre o firewall e os servidores de aplicação que atuará como um proxy, que sabe quais conjuntos de servidores podem efetivamente atender a uma requisição vinda da internet. Esquematicamente podemos representar o balanceamento de carga conforme a Figura 3.
A solução de balanceamento de carga resolve a questão de FT dos servidores Web e também a questão de escalabilidade horizontal de uma aplicação, que em teoria, pode passar a atender mais requisições simultâneas à medida que adicionarmos mais servidores Web. Entretanto, a solução introduz um novo SPOF, que é o próprio LB. Como nosso objetivo principal é focar na parte de alta disponibilidade dos servidores que contêm uma aplicação Web, vamos deixar de lado a questão de FT do LB, porém o leitor interessado pode consultar algumas referências na seção Links, que mostram como criar clusters de LBs baseadas em IPs virtuais.
Em seguida, passando à segunda questão, somos levados a pensar se devemos nos preocupar em preservar ou não o estado contido em uma sessão HTTP. Se a aplicação não faz uso da HttpSession, o que na prática só é verdade no caso de aplicações que não disponibilizam interfaces para interação humana, como Web Services e similares; não há com o que se preocupar. Por outro lado, em geral qualquer aplicação web baseada em frameworks como JSF ou GWT, precisará armazenar dados na sessão de um usuário em algum momento. Nesse caso temos que decidir se a sessão HTTP será replicada entre todos os nós ou não. O fato de replicar a sessão implica que vamos oferecer algo conhecido como Transparent Failover, o que quer dizer que se um dos servidores Web falhar, o usuário não vai “perceber” que ocorreu um problema e continuará utilizando normalmente a aplicação, por exemplo, sem precisar se logar novamente. Caso optemos por não replicar a sessão, temos um problema a menos para resolver, porém em alguns casos isso pode ser inaceitável.
Neste artigo vamos mostrar como configurar e disponibilizar um ambiente com servidores Web em alta disponibilidade, com balanceamento de carga e replicação de sessão utilizando os seguintes componentes e frameworks:
Nos próximos tópicos vamos fazer uma breve descrição de cada um desses componentes para entendermos como os mesmos poderão ser integrados para formar uma solução de alta disponibilidade e, em seguida, mostrar como devemos configurá-los de forma que os mesmos possam efetivamente se comunicar.
O servidor Apache nasceu praticamente ao mesmo tempo que a linguagem Java (~1994), porém levou um certo tempo para que ambos pudessem ser integrados. O Apache inicialmente era utilizado para disponibilizar as primeiras aplicações web com conteúdo dinâmico baseadas em CGI (Common Gateway Interface), a qual serviu como alicerce para criação da primeira versão da linguagem PHP.
Atualmente o Apache é disponibilizado em uma estrutura modular, que permite a adição ou remoção de funcionalidades via configuração. Por exemplo, se desejarmos que o tráfego de requisições ocorra de maneira ‘confidencial’, podemos instalar o módulo SSL (mod_ssl) para configurar quais caminhos, e.g. /secure, deverão ser solicitados utilizando HTTPS em vez de HTTP.
Nesta seção vamos focar em configurar apenas um dos módulos do Apache no Linux Mint, o módulo mod_jk, que é responsável por fazer o balanceamento de carga entre o Apache e o Tomcat. Porém, vamos fazer algumas observações com respeito aos módulos prefork e worker, que podem ter impacto na quantidade de requisições e tempo de resposta.
A seguir estão enumerados os passos para fazer a instalação básica do Apache:
O próximo passo é customizar a instalação do Apache para fazer a configuração inicial do balanceamento de carga. Para isso, primeiramente vamos entender como se dispõe a estrutura de configuração do servidor, que pode ser representada como mostrado na Figura 4
Se acessarmos o diretório no qual o Apache foi instalado (/etc/apache2) e listarmos o seu conteúdo veremos que há um arquivo chamado apache2.conf. Neste arquivo são apresentadas as configurações básicas do servidor e também são definidos quais módulos listados no diretório mods-enabled serão efetivamente carregados de acordo com a diretiva “Include” da API do Apache.
O diretório mods-enabled contém diversos arquivos terminados com os sufixos .load ou .conf, os quais são responsáveis, respectivamente, por carregar um módulo compilado do Apache e por configurar o comportamento deste módulo. Os módulos compilados do Apache ficam todos em uma pasta chamada modules, porém podem ser colocados em qualquer diretório, desde que a diretiva LoadModule contida nos arquivos *.load aponte para o caminho correto.
Nesta estrutura vemos também que há um diretório chamado mods-available, que é muito similar ao mods-enabled, porém o seu conteúdo é simplesmente ignorado na inicialização do servidor. Este diretório contém apenas arquivos que podem ser pensados como “templates” de configuração para apresentar módulos do Apache, que devem ser copiados para o diretório mods-enabled para serem efetivados. Assim, quando quisermos habilitar um novo módulo, podemos partir de uma configuração localizada em mods-available, copiar para mods-enabled e customizá-la.
Finalmente, vamos observar de maneira mais detalhada o arquivo de configuração jk.conf e modificá-lo para fazer a configuração do balanceamento de carga (mod_jk). Inicialmente faremos apenas a configuração do serviço para o monitoramento do balanceamento de carga, pois ainda não temos os nós do Tomcat disponíveis para serem balanceados. Posteriormente vamos revisitar esta configuração para “plugar” as instâncias do Tomcat.
Omitindo os comentários do arquivo jk.conf, a configuração do mesmo deverá ficar semelhante à mostrada na Listagem 1.
<IfModule jk_module>
JkWorkersFile /etc/libapache2-mod-jk/workers.properties
JkLogFile /var/log/apache2/mod_jk.log
JkLogLevel info
JkShmFile /var/log/apache2/jk-runtime-status
JkWatchdogInterval 60
<VirtualHost localhost:80>
JkMount /jkstatus* jkstatus
</VirtualHost>
</IfModule>As configurações do Apache por vezes podem parecer um pouco confusas, misturando XML com texto livre, porém, em geral, quando há uma linha que contém texto simples nos arquivos .conf, a mesma se refere à configuração de algum atributo de um módulo, ou seja, cada linha pode ser pensada como um par [chave,valor]. No caso do arquivo jk.conf, o significado de cada propriedade “encapsulada” no elemento <IfModule jk_module> é apresentado a seguir:

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.