Neste artigo é realizado um exemplo de Fragmentaçăo de dados, técnica muito utilizada em Sistemas de Banco de Dados Distribuídos. Para isso a linguagem SQL será utilizada no Oracle 11g Express Edition e será criada e configurada uma rede wireless no Windows 7 para a comunicaçăo entre as máquinas e compartilhamento de informaçőes dos seus bancos de dados.
Fragmentaçăo
Segundo Oszu e Valduriez (2001), em Sistemas de Banco de Dados Distribuídos, por razőes de desempenho, confiabilidade e disponibilidade, é desejável que os dados sejam distribuídos pelas máquinas de uma rede de forma replicada. Uma das técnicas muito utilizadas para esse fim é a fragmentaçăo, onde as relaçőes de um banco de dados săo divididas em fragmentos menores e cada fragmento é tratado como um objeto de banco de dados separado. Nessa técnica, cada réplica năo é a replicaçăo completa, mas apenas um subconjunto dessa relaçăo, assim é exigido menos espaço e consequentemente menos itens de dados precisam ser administrados.
A Fragmentaçăo pode ser horizontal, vertical ou híbrida. Na primeira, uma relaçăo é particionada em suas tuplas (linhas) e cada fragmento gerado tem um subconjunto das tuplas da relaçăo original. Na fragmentaçăo vertical săo produzidos fragmentos que contęm um subconjunto dos atributos (colunas) da relaçăo original, bem como sua primary key. Também chamada de fragmentaçăo mista ou aninhada, a fragmentaçăo híbrida consiste na aplicaçăo das duas técnicas citadas anteriormente, uma após a outra. Ela é utilizada porque, na maioria dos casos, uma fragmentaçăo vertical ou horizontal năo será suficiente para atender aos requisitos de aplicativos do usuário.
Existem duas versőes da Fragmentaçăo Horizontal: primária e derivada. A Fragmentaçăo Horizontal Primária é executada com o uso de predicados definidos sobre a própria relaçăo, já a Fragmentaçăo Horizontal Derivada surge do particionamento de uma relaçăo, que é resultado da definiçăo de predicados sobre outra relaçăo. Neste artigo será utilizada a técnica de Fragmentaçăo Horizontal Primária.
O principal objetivo da fragmentaçăo é minimizar o tempo de processamento dos aplicativos do usuário, logo, mesmo sendo baseadas em uma relaçăo completa, as consultas săo executadas sobre os fragmentos.
Estudo de caso – Cadastro de Funcionários
Criaçăo e configuraçăo da rede.
Em Sistemas de Bancos de Dados Distribuídos, a rede é um dos recursos mais importantes, logo, para que se configure a distribuiçăo as várias máquinas que compartilham informaçőes, as mesmas precisam estar interconectadas através de uma rede, de maneira transparente.
Para realizar a comunicaçăo entre a máquina 1 e a máquina 2 do estudo de caso Cadastro de Funcionários será criada e configurada uma rede ad hoc, que é uma rede sem fio que dispensam o uso de um ponto de acesso comum aos computadores conectados a ela, de modo que todos os dispositivos da rede funcionam como se fossem um roteador, encaminhando comunitariamente informaçőes que vęm de dispositivos vizinhos.
Para a criaçăo da rede, execute o prompt de comando do Windows como administrator e digite o comando a seguir:
netsh wlan set hostednetwork ssid=remoteServer key=serverkey12O resultado da execuçăo pode ser visto na Figura 1.

Figura 1. Comando para criaçăo da rede ad hoc.
Nesse caso, como já havia uma rede hospedada, o comando apenas fez a alteraçăo das informaçőes da rede. Após a criaçăo da rede, para que esta fique disponível de modo que os usuários se conectem é necessário que a rede seja iniciada. Para isso, digite o comando para iniciaçăo de redes ad hoc no prompt de comando do Windows:
netsh wlan start hostednetworkCriada e ativada a rede, a maquina 2 poderá conectar-se a ela usando o nome de usuário e senha configurados para a rede. Depois de conectado é importante testar a conectividade utilizando o comando de rede Ping, que deve ser executado no prompt de comando do Windows. A conectividade estará estabelecida com sucesso caso năo haja perda de pacotes no resultado do comando, conforme a Figura 2.
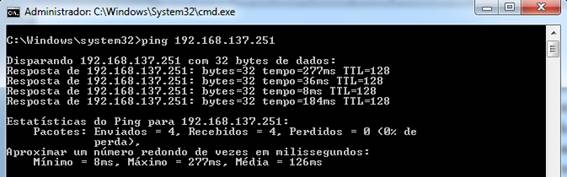
Figura 2. Comando para testar a conectividade entre as máquinas interligadas.
Caso a rede năo fique disponível para os usuários da máquina na qual esta foi configurada, verifique o firewall do Windows, que pode impedir a disponibilidade da rede por questőes de segurança. Assim, será necessário configurá-lo para permitir conexőes de entrada. Para isso, percorra o caminho Painel de Controle/Sistema e Segurança/Firewall do Windows/Configuraçőes avançadas para habilitar conexőes de entrada no Windows.
Ao clicar em configuraçőes avançadas, a tela da Figura 3 será exibida. Clique em Propriedades do firewall do Windows.

Figura 3.Tela de configuraçőes avançadas do firewall do Windows.
Será aberta uma tela, como a exibida na Figura 4. Em conexőes de entrada, escolha a opçăo permitir para todos os perfis e clique em Ok.
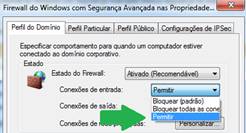
Figura 4. Tela de configuraçăo das permissőes de conexőes de entrada.
Configuraçăo do serviço para a criaçăo do link
Para a criaçăo de um link é necessário que se especifique o nome da conexăo que contém os detalhes da máquina que se deseja conectar. Essas conexőes săo configuradas no arquivo tnsnames, que se encontra na pasta de instalaçăo do Oracle, em C:/oraclexe/app/oracle/product/11.2.0/server/network/ADMIN.
Na Figura 5 vemos o arquivo tnsnames e as linhas em evidęncia devem ser adicionadas ao arquivo, conforme a Listagem 1, para a configuraçăo do serviço que será utilizado para acessar a máquina 2 do estudo de caso.
Listagem 1. Trecho a adicionar no arquivo tnsnames
REMOTE =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.137.251)(PORT = 1521))
(CONNECT_DATA =
(SERVICE_NAME = XE)
)
)
)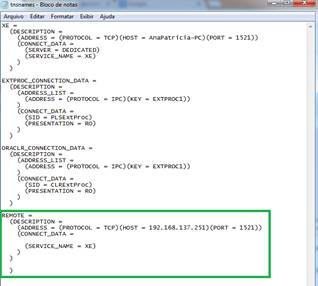
Figura 5. Arquivo tnsnames do Oracle.
Observe que um nome é dado ŕ conexăo criada. O protocolo do endereço IP, bem como o próprio IP da máquina que se deseja conectar devem ser definidos no arquivo. A porta de comunicaçăo e o nome do serviço do SGBD que será utilizado também devem ser especificados. Nesse caso como a fragmentaçăo será em SGBSs homogęneos (iguais), a porta utilizada será 1521 (pertencente ao Oracle) e o nome do serviço será XE, o padrăo do Oracle.
Sintaxes para a criaçăo e autenticaçăo do link
Para que os dois bancos se comuniquem, é trivial a definiçăo de um link. Com o link definido é possível que um banco de dados acesse objetos em outro banco de dados. A sintaxe para a criaçăo de um link pode ser observada na Figura 6.
Na criaçăo de um link, é obrigatória a especificaçăo de um usuário e senha, tais parâmetros deverăo receber o usuário e senha do banco de dados Oracle da máquina que se deseja acessar. O padrăo de usuário de bancos de dados Oracle é system ou sys, e é necessária ainda a especificaçăo do serviço configurado no arquivo de serviços do Oracle. Veremos o passo a passo da configuraçăo mais ŕ frente. A sintaxe para a autenticaçăo do link pode ser observada na Figura 7.
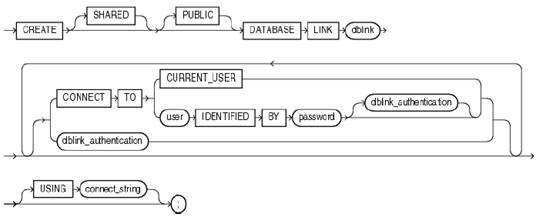
Figura 6. Esquema da sintaxe para a criaçăo de um link - ()dblink_authentication

Figura 7. Esquema da sintaxe para a autenticaçăo de um link.
Na Listagem 2 encontra-se o código SQL para a criaçăo do link que identificará o banco de dados que será acessado na máquina 2.
Listagem 2. Código SQL para a criaçăo do link do banco de dados que será acessado pela máquina 1
CREATE DATABASE LINK REMOTE_DB_MAQUINA2
CONNECT TO SYSTEM
IDENTIFIED BY “keymaquina2”
USING REMOTEDepois de criado, o link pode ser usado para referenciar objetos, como se fosse uma instância do banco que está sendo manipulada, como pode ser observado a seguir:
FUNCIONARIO_TB2@REMOTE_DB_MAQUINA2;Criaçăo das Tabelas FUNCIONARIO_TB1 e FUNCIONARIO_TB2
A Listagem 3 mostra o comando SQL utilizado para a criaçăo da tabela FUNCIONARIO_TB1, que será criada no banco da máquina 1.
Listagem 3. Criaçăo da tabela funcionario_tb1.
CREATE TABLE FUNCIONARIO_TB1(
ID_FUNCIONARIO INT PRIMARY KEY,
NOME_FUNCIONARIO VARCHAR(80) NOT NULL,
CPF_FUNCIONARIO VARCHAR(14) NOT NULL,
CATEGORIA_FUNCIONARIO VARCHAR(20) NOT NULL,
SALARIO_FUNCIONARIO NUMERIC(8,2) NOT NULL
);Na Figura 8 pode-se observar a saída para o comando.
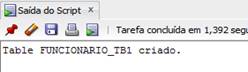
Figura 8. Saída para o comando de criaçăo da tabela funcionario_tb1.
A Figura 9 mostra a tabela criada.
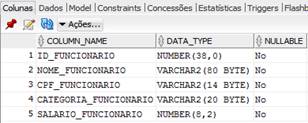
Figura 9. Tabela funcionario_tb1 criada.
A tabela também deverá ser criada no banco de dados da maquina 2, como na Listagem 4. As Figuras 10 e 11 apresentam a saída para o comando e a tabela criada, respectivamente.
Listagem 4. Sintaxe para a criaçăo da tabela funcionário do banco de dados da maquina 2.
CREATE TABLE FUNCIONARIO_TB2(
ID_FUNC INT PRIMARY KEY,
NOME_FUNC VARCHAR(80) NOT NULL,
CPF_FUNC VARCHAR(14) NOT NULL,
CATEGORIA_FUNC VARCHAR(20) NOT NULL,
SALARIO_FUNC NUMERIC(8,2) NOT NULL
);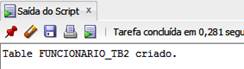
Figura 10. Saída para o comando de criaçăo da tabela funcionario_tb2.
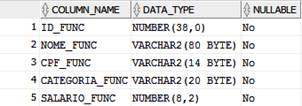
Figura 11. Tabela funcionario_tb2 criada.
De modo que năo haja conflito de chaves na inserçăo de funcionários, é interessante que a chave seja automática. Para isso, é necessária a criaçăo de uma sequence (Listagem 5) para o atributo identificador da tabela FUNCIONARIO_TB1 e um trigger (Listagem 6) que será acionado sempre que uma operaçăo de inserçăo for realizada na tabela FUNCIONARIO_TB1.
Listagem 5. Criaçăo da sequence para gerar chave automática para tabela funcionario_tb1.
CREATE SEQUENCE AUTO_INCREMENT_FUNCIONARIO
INCREMENT BY 1
START WITH 1;A sequence AUTO_INCREMENT_FUNCIONARIO define que a chave será incrementada de um em um e que esta será iniciará a partir do 1.
Listagem 6. Criaçăo do gatilho para chamar a sequence auto_increment_funcionario.
CREATE OR REPLACE TRIGGER INCREMENT_FUNCIONARIO_TRG
BEFORE INSERT ON FUNCIONARIO_TB1
FOR EACH ROW
BEGIN
SELECT AUTO_INCREMENT_USUARIO.NEXTVAL INTO:NEW.ID_FUNCIONARIO FROM DUAL;
END;O gatilho INCREMENT_FUNCIONARIO_TRG será disparado sempre depois de uma inserçăo na tabela funcionario_tb1. Nele será chamada a sequence AUTO_INCREMENT_FUNCIONARIO, assim, a chave primária da tabela sempre será incrementada automaticamente após uma inserçăo.
Predicado de fragmentaçăo da tabela funcionario_tb1.
Um predicado de fragmentaçăo deverá ser criado de modo a se definir uma condiçăo para o particionamento da relaçăo original. O atributo da tabela funcionario_tb1 que será usado para definiçăo dos predicados será CATEGORIA_FUNCIONARIO, definindo a condiçăo para que o funcionário seja manipulado no banco de dados da máquina 2:
P: (CATEGORIA_FUNCIONARIO = “terceirizado”) ^ (SALARIO_FUNCIONARIO ≤ 3000)Conforme o predicado, no banco de dados da máquina 2 apenas serăo inseridos funcionários terceirizados e que recebem salário igual ou inferior a R$ 3.000,00.
Operaçăo de Inserçăo
Para que os dados que serăo inseridos na tabela FUNCIONARIO_TB1 (máquina 1) sejam fragmentados e inseridos na tabela FUNCIONARIO_TB2 (máquina 2), será necessária a criaçăo de um trigger (gatilho), que sempre deverá ser acionado depois de solicitada uma inserçăo na tabela funcionario_tb1. Observe na Listagem 7 a sintaxe.
Listagem 7. Trigger para a operaçăo inserir.
CREATE OR REPLACE TRIGGER INSERIRFUNCIONARIO
BEFORE INSERT ON FUNCIONARIO_TB1
FOR EACH ROW
BEGIN
IF (:NEW.CATEGORIA_FUNCIONARIO = ‘TERCEIRIZADO’ AND :NEW.SALARIO_FUNCIONARIO <= 3000) THEN
INSERT INTO FUNCIONARIO_TB2@REMOTE_DB_MAQUINA2 VALUES (DEFAULT, :NEW.NOME_FUNCIONARIO, :NEW.CPF_FUNCIONARIO, :NEW.CATEGORIA_FUNCIONARIO, :NEW.SALARIO_FUNCIONARIO);
END IF;
END;Para que o Oracle compare linguisticamente, ignorando caracteres maiúsculos e minúsculos, é necessário alterar a sessăo corrente de modo a definir que esta năo seja case sensitive, como na Listagem 8.
Listagem 8. Comando para alterar a sessăo.
ALTER SESSION SET NLS_SORT='WEST_EUROPEAN_CI';
ALTER SESSION SET NLS_COMP='ANSI';O gatilho INSERIRFUNCIONARIO sempre será acionado depois que for realizada uma operaçăo de inserçăo na tabela FUNCIONARIO_TB1. Caso o funcionário que está sendo inserido seja terceirizado e o valor do seu salário seja menor ou igual a R$ 3.000,00 também será inserido na tabela funcionario_tb2. Funcionários com atributos fora do requisito definido no predicado serăo inseridos somente na tabela FUNCIONARIO_TB1. Na Figura 12 observe um exemplo de inserçăo nessa tabela.

Figura 12. Exemplo de inserçăo na tabela funcionario_tb1.

Na Figura 13 pode ser observada a tabela FUNCIONARIO_TB1 com os dados inseridos. Como neste exemplo foi inserido um funcionário com atributos que atendem aos requisitos definidos no predicado, os dados também foram inseridos na tabela funcionario_tb2. Isso pode ser observado através de um select (Listagem 10) sobre a view (Listagem 9) que seleciona os dados da tabela remota FUNCIONARIO_TB2, como na Figura 14.
Figura 13. Dados inseridos na tabela funcionario_tb1.
Listagem 9. View para selecionar os dados da tabela funcionario_tb2.
CREATE VIEW FUNCIONARIO_TB_REMOTE AS
SELECT * FROM FUNCIONARIO_TB2@REMOTE_DB_MAQUINA2;Listagem 10. Select sobre a view funcionario_tb_remote.
SELECT * FROM FUNCIONARIO_TB_REMOTE;
Figura 14. Dados inseridos na tabela funcionario_tb2.
A Figura 15 mostra um novo exemplo de inserçăo onde os atributos categoria e salário năo atendem aos requisitos do predicado.

Figura 15. Novo exemplo de inserçăo na tabela funcionario_tb1.
A Figura 16 apresenta os dados inseridos na tabela FUNCIONARIO_TB1 e a Figura 17 mostra que a tabela FUNCIONARIO_TB2 năo sofreu nenhuma nova inserçăo.

Figura 16. Novos dados inseridos na tabela funcionario_tb1.

Figura 17. Tabela funcionario_tb2 sem novas inserçőes.
Operaçăo de atualizaçăo
As atualizaçőes na tabela FUNCIONARIO_TB1 serăo realizadas conforme o predicado definido para realizaçăo da operaçăo de inserçăo, de modo que os dados de funcionários inseridos na tabela FUNCIONARIO_TB2 também sejam corretos e mantenham a regra de permanęncia no banco de dados. Um novo trigger deverá ser criado para realizar as operaçőes de atualizaçăo, como mostra a Listagem 11.
Listagem 11. Trigger para atualizaçăo da tabela funcionario_tb1
CREATE OR REPLACE TRIGGER ATUALIZARFUNCIONARIO
BEFORE UPDATE ON FUNCIONARIO_TB1
FOR EACH ROW
BEGIN
IF(:NEW.CATEGORIA_FUNCIONARIO = ‘TERCEIRIZADO’ AND :NEW.SALARIO_FUNCIONARIO <= 3000) THEN
UPDATE FUNCIONARIO_TB2@REMOTE_DB_MAQUINA2 SET NOME_FUNC = :NEW.NOME_FUNCIONARIO, CPF_FUNC = :NEW.CPF_FUNCIONARIO, CATEGORIA_FUNC = :NEW.CATEGORIA_FUNCIONARIO, SALARIO_FUNC = :NEW.SALARIO_FUNCIONARIO WHERE :OLD.ID_FUNCIONARIO = :OLD.ID_FUNCIONARIO;
END IF;
END;O gatilho ATUALIZARFUNCIONARIO sempre será acionado depois de uma atualizaçăo na tabela FUNCIONARIO_TB1. Para que haja atualizaçăo na tabela funcionario_tb2 o predicado definido deve ser atendido, caso isso năo ocorra, a atualizaçăo será feita apenas na tabela FUNCIONARIO_TB1. Observe um exemplo de atualizaçăo na Figura 18.

Figura 18. Exemplo de atualizaçăo na tabela funcionario_tb1.
A Figura 19 mostra a tabela FUNCIONARIO_TB1 e a Figura 20 a tabela FUNCIONARIO_TB2 com os dados atualizados.

Figura 19. Dados atualizados na tabela funcionario_tb1.

Figura 20. Dados atualizados na tabela funcionario_tb2.
Agora, observe um exemplo de atualizaçăo com dados que năo atendem ao predicado na Figura 21. A Figura 22 apresenta a tabela atualizada.

Figura 21. Novo exemplo de atualizaçăo na tabela funcionario_tb1.

Figura 22. Nova atualizaçăo na tabela funcionario_tb1
Obviamente, como o valor do salário năo atende ao pré-requisito definido, a tabela FUNCIONARIO_TB2 năo sofrerá nenhuma modificaçăo.
Operaçăo de exclusăo
A operaçăo de exclusăo na tabela FUNCIONARIO_TB1 deverá seguir a mesma lógica das operaçőes anteriores, de modo que uma operaçăo de delete nessa tabela exclua năo só os dados da mesma, como também os dados na tabela FUNCIONARIO_TB2 correspondentes. Para isso criaremos um trigger, conforme a Listagem 12.
Listagem 12. Trigger para exclusăo de dados na tabela funcionario_tb1.
CREATE OR REPLACE TRIGGER DELETARFUNCIONARIO
BEFORE DELETE ON FUNCIONARIO_TB1
FOR EACH ROW
BEGIN
DELETE FROM FUNCIONARIO_TB2@REMOTE_DB_MAQUINA2 WHERE :OLD.ID_FUNCIONARIO = :OLD.ID_FUNCIONARIO;
END;O gatilho DELETARFUNCIONARIO sempre será disparado depois de uma operaçăo de exclusăo na tabela FUNCIONARIO_TB1, assim os dados dos funcionários fragmentados na tabela FUNCIONARIO_TB2 também serăo excluídos. Observe na Figura 23 um exemplo de exclusăo na tabela FUNCIONARIO_TB1.

Figura 23. Exemplo de exclusăo na tabela funcionario_tb1.
As Figuras 24 e 25 mostram a tabela FUNCIONARIO_TB1 e FUNCIONARIO_TB2 depois da realizaçăo da operaçăo de exclusăo. Como o código de cada linha inserida na tabela FUNCIONARIO_TB1 foi replicado na tabela FUNCIONARIO_TB2, toda exclusăo realizada na primeira também será realizada na segunda, portanto tal tabela encontra-se vazia.

Figura 24. Tabela funcionario_tb1 após operaçăo de delete.

Figura 25. Tabela funcionario_tb2 vazia após operaçăo de delete.
A técnica de fragmentaçăo mostra-se eficiente por permitir que apenas parte de uma relaçăo seja replicada, reduzindo assim o tempo e espaço com a administraçăo de relaçőes completas. Através da técnica também é possível dar respostas mais rápidas ŕs solicitaçőes de usuários, isso pode ser feito com o particionamento definido sobre a localidade do usuário, onde os dados estarăo disponíveis em locais próximos a ele. Outra vantagem é que a disputa por recursos de processamento e de entrada e saída será reduzida. Vale lembrar que năo é o administrador do banco de dados quem decide quando deve ou năo fragmentar, mas os aplicativos do usuário, logo a fragmentaçăo deverá ser realizada conforme sua necessidade.
Referęncias
Kotviski,
Adriel; O QUE SĂO REDES AD HOC?
http://www.tecmundo.com.br/internet/2792-o-que-sao-redes-ad-hoc-.htm.
Tamer Ozsu, Patrick Valduriez; PRINCÍPIOS DE SISTEMAS DE BANCOS DE DADOS DISTRIBUÍDOS. Traduçăo Principies of Distributed Database Systems [2 ed. americana] Vandenberg D. de Sousa – Rio de Janeiro: Campus, 2001. ISBN 85-352-0713-9.
Oracle
Database Online Documentation; CREATE
DATABASE LINK
http://docs.oracle.com/cd/B19306_01/server.102/b14200/statements_5005.htm
Tanenbaum, Andrew S.; REDES DE COMPUTADORES. Traduçăo de Computer networks [3 ed. original] Insight Serviços de Informática - Rio de Janeiro: Campus, 1997. ISBN 85-352-0157-2



