Como usar o Apache Cassandra em aplicaçőes Java EE – Parte 2
Artigo no estilo: Curso
O artigo irá apresentar uma visăo geral do Apache Cassandra incluindo conceitos chave, modelo de dados, constraints, ferramentas, boas práticas, entre outros. Além disso, irá demonstrar através da implementaçăo de uma aplicaçăo simples como combinar esse banco de dados com as tecnologias do Java EE, e para isso, será utilizado o driver da DataStax, WildFly 9, PrimeFaces 5.3, Cassandra 2.2, além de outras tecnologias.
Ao longo das últimas décadas muitas coisas aconteceram no mundo da tecnologia: mudanças em linguagens de programaçăo, novas arquiteturas, diferentes metodologias de desenvolvimento, entre outros. No entanto, uma coisa permanecia intacta: bancos de dados relacionais eram a escolha padrăo para armazenar dados. Com o crescimento acelerado da Internet e a necessidade cada vez mais comum de manipular altos volumes de dados, isso mudou um pouco. Uma nova tecnologia emergiu e vem se consolidando nos últimos anos: săo os chamados bancos de dados NoSQL.
Um dos principais problemas dos bancos de dados relacionais para lidar com grandes massas de dados é o fato de que sua arquitetura cria dificuldades para que esses bancos rodem em cluster. Dessa forma, quando surge a necessidade de escalar as alternativas normalmente săo:
· Escalabilidade Vertical: consiste em aumentar os recursos do servidor (memória, CPU, disco e etc.). Além de ter um limite máximo real, normalmente tem custos proibitivos;
· Sharding: essa técnica divide os dados da aplicaçăo em mais de um servidor, distribuindo melhor a carga. O problema é que traz uma enorme complexidade para a aplicaçăo, perde as melhores vantagens dos bancos relacionais, como integridade referencial, e continua tendo um ponto único de falha;
· Master-Slave: um servidor (Master) recebe todas as escritas e replica para as demais instâncias (Slaves), as quais podem atender apenas requisiçőes de leitura. Apesar de poder distribuir melhor a carga entre vários servidores, continua tendo um ponto único de falha e năo consegue ter escalabilidade nas operaçőes de escrita por ter apenas um servidor atendendo esse tipo de requisiçăo. Ademais, pode acarretar em custos que inviabilizam sua adoçăo.
Por esse motivo os bancos de dados NoSQL vęm se popularizando cada vez mais. Executar em cluster com naturalidade, ter alta disponibilidade, facilidade de rodar na nuvem săo aspectos comuns nesses novos bancos, pois nasceram justamente para resolver esse tipo de problema. Nesse contexto, o Apache Cassandra se destaca por possuir um modelo arquitetural que proporciona todas essas funcionalidades de uma maneira que minimiza a complexidade existente nesse tipo de ambiente.
Assim, nas próximas seçőes este artigo irá apresentar o Apache Cassandra de maneira mais detalhada, com o intuito de proporcionar ao leitor um embasamento teórico para o melhor entendimento da tecnologia, bem como irá demonstrar por meio de um exemplo prático algumas das funcionalidades explicadas. Além disso, também será exposta uma abordagem para usá-lo em conjunto com a plataforma Java EE. E para tornar o exemplo mais próximo do nosso dia a dia, outras tecnologias serăo usadas, como o PrimeFaces e seus novos recursos de responsividade, CDI e DeltaSpike.
Conhecendo o Apache Cassandra
O Cassandra é um banco de dados NoSQL orientado a colunas desenvolvido em Java. Criado pelo Facebook e depois doado para a Fundaçăo Apache, hoje é reconhecido na indústria de software como um banco de dados massivamente escalável, de alta disponibilidade, distribuído, dentre outras características essenciais para suportar volumes de dados colossais, com crescimento exponencial e carga excessiva de requisiçőes.
Antes de analisar outros detalhes, a seguir serăo apresentados alguns conceitos importantes para facilitar o entendimento do restante do artigo:
· Cluster: consiste num grupo de máquinas (nós) onde os dados săo distribuídos e armazenados. Pode ser composto de um único nó (single-node cluster) ou vários nós em diversos data centers. A Figura 1 apresenta um exemplo;
· Data center: uma subdivisăo dos nós do cluster, os quais estăo ligados para propósitos de segregaçăo de replicaçăo e carga. Por exemplo, é possível configurar o Cassandra para replicar dados apenas entre nós do mesmo data center, o que normalmente envolve menos latęncia do que replicar através de múltiplos data centers. Năo se trata necessariamente de um data center físico;
· Nó: uma máquina que faz parte do cluster e que consequentemente armazena dados da base;
· Keyspace: tem o conceito similar a um database no PostgreSQL, onde tabelas săo agrupadas para uma finalidade específica. Normalmente para separar dados de aplicaçőes diferentes;
· Família de colunas (Column-Family): nas versőes mais atuais do Cassandra esse termo foi substituído por Tabela. Trata-se de um conjunto de pares chave/valor (nome da coluna/valor da coluna) onde săo armazenadas as informaçőes da base. Pode-se dizer que com o CQL3 (Cassandra Query Language) esse termo ficou obsoleto.
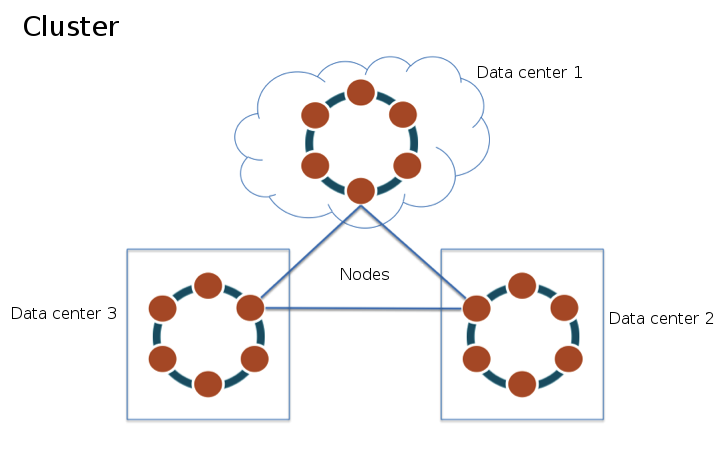
Figura 1. Representaçăo de um cluster multi-data center – Adaptado de DataStax.
CQL – O SQL do Cassandra
O CQL (Cassandra Query Language), como o próprio nome já diz, é a linguagem de consulta para o Cassandra. Atualmente na versăo 3.3, é a interface primária para estabelecer comunicaçăo com essa base de dados. Além disso, por possuir muitos aspectos similares ao SQL, năo se restringindo apenas ao nome, o CQL3 facilita bastante o aprendizado de profissionais que estăo habituados a trabalhar com bancos de dados relacionais. Antes do CQL a interface padrăo do Cassandra era a Thrift API (vide BOX 1).
Nos primórdios do Cassandra a única opçăo disponível para consulta era a Thrift API, uma interface baseada no protocolo RPC e que era bastante burocrática e difícil de entender ŕ primeira vista. Em seguida houve algumas melhoras com o advento do CQL, mas ainda assim muitas características da Thrift API estavam presentes. Somente com o CQL3 o Cassandra pôde ter uma forma de comunicaçăo mais intuitiva, simples e produtiva.
O CQL3 também impactou a forma de modelar dados para o Cassandra. Assim, caso vocę esteja interessado em se aprofundar no assunto é importante entender que existe uma fase “pré-CQL3” e outra “pós-CQL3”. Isso irá facilitar os estudos e evitará confusăo ao aprender dicas e boas práticas diferentes para cada uma dessas fases. Neste artigo, iremos focar no CQL3.
Acessando o CQL
A maneira mais comum de acessar o CQL é através da ferramenta cqlsh, como pode ser observado na Figura 2. Trata-se de um cliente de linha de comando que vem junto com a instalaçăo do Cassandra (CASSANDRA_HOME/bin/cqlsh).
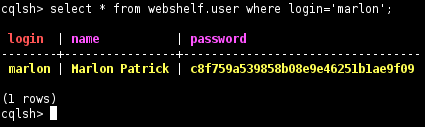
Figura 2. Executando comandos CQL através do cqlsh.
Caso queira optar por uma ferramenta gráfica, o DataStax DevCenter é uma ótima opçăo (vide Figura 3). Esta ferramenta é baseada no Eclipse e traz algumas views especializadas para o Cassandra:
· View Connections: Espaço onde vocę pode gerenciar todas as conexőes que criou para algum cluster do Cassandra.
· View Schema: Aqui săo listados todos os objetos de uma determinada conexăo, o que permite uma visualizaçăo hierárquica da estrutura do banco (keyspace > tabela > coluna);
· View CQL Scripts: Através dessa view é possível gerenciar scripts CQL: criar, editar, deletar;
· View Results: Exibe o resultado da última consulta executada; e
· Editor CQL: Editor que possibilita escrever e executar comandos CQL, faz destaque de palavras reservadas, tem code completion e ainda possibilita escolher a conexăo onde o comando será executado para cada arquivo aberto.
Escolher entre uma ferramenta e outra normalmente é uma questăo de preferęncia. O DevCenter é mais indicado para quem está iniciando devido a diversas facilidades que uma IDE pode proporcionar, como: wizards para criaçăo de conexőes, keyspaces e tabelas, abas para se trabalhar com múltiplos servidores, gerenciamento de scripts, destaque de palavras reservadas, entre outros. O cqlsh, por sua vez, é mais utilizado por quem tem familiaridade com a linha de comando e năo está muito a fim de abrir uma IDE pesada na sua máquina. Como facilidade, o cqlsh tem o recurso de tab completion, bastante útil a quem está acostumado com a “telinha preta”.

Figura 3. Executando comandos CQL através do DevCenter.
Modelagem – Desnormalizar é preciso
Quando se fala de modelagem de dados em bancos NoSQL, normalmente temos que deixar de lado quase tudo que é considerado boa prática no mundo relacional. No Cassandra năo é diferente, e mais, várias das boas práticas da modelagem relacional săo consideradas anti-padrőes.
Nesse banco a normalizaçăo dos dados é considerada um destruidor de performance. Portanto, quase sempre é melhor desnormalizar para escalar a base. Por isso, năo se preocupe tanto com a repetiçăo dos dados ou com a quantidade maior de escritas que isso provoca. O Cassandra sabe lidar muito bem com essa situaçăo.
Outra diferença é que nos bancos relacionais o foco da modelagem săo as tabelas (entidades), onde a partir das mesmas diversos relacionamentos săo obtidos através de joins e chaves estrangeiras. Já as boas práticas do Cassandra instruem a guiar sua modelagem baseado nas consultas. Assim, um padrăo recomendado é ter uma tabela por consulta. Por exemplo, se sua aplicaçăo precisa consultar Usuários por nome e por login, serăo criadas duas tabelas: usuario_por_nome e usuario_por_login, ambas com os mesmos dados (desnormalizaçăo).
O problema da normalizaçăo e do foco em entidades é que essas técnicas acabam distribuindo os dados de forma inadequada, e para um banco como o Cassandra, isso pode significar ter que consultar vários nós do cluster para encontrar a informaçăo, o que pode acarretar um grande problema de desempenho. As recomendaçőes apresentadas visam minimizar ao máximo o acesso a múltiplos nós.
Partition Key
Todas as tabelas do Cassandra precisam definir uma chave denominada Partition Key. Esta tem como principal utilidade determinar em qual nó do cluster um dado será armazenado e trata-se de um conceito fundamental a todos que lidam com essa base de dados.
No que se refere ŕ modelagem, a partition key tem relaçăo direta com os filtros de uma consulta. Isso porque no Cassandra qualquer query precisa filtrar a tabela no mínimo pelas colunas que compőem sua partition key. A lógica dessa restriçăo é que sem a partition key o Cassandra năo tem como saber em qual nó a informaçăo está armazenada.
Neste ponto vale ressaltar que năo se deve confundir partition key com primary key. Por exemplo, digamos que uma tabela definiu sua chave primária da seguinte forma:
PRIMARY KEY (user_login, status, book_isbn)Nesse cenário, a primary key é composta pelas colunas user_login, status e book_isbn, enquanto a partition key se resume ŕ primeira coluna, que no caso é user_login. As demais săo conhecidas como clustering columns.
Clustering Column
Outro importante aspecto do Cassandra săo as Clustering Columns. Essas colunas fazem parte da primary key, mas năo da partition key. No exemplo apresentado anteriormente, as colunas status e book_isbn seriam as clustering columns.
A funçăo dessas colunas é determinar a ordenaçăo pela qual os dados serăo organizados no disco para uma determinada partition key. É como uma ordenaçăo padrăo. Assim, no exemplo supracitado, uma vez que a tabela foi filtrada pela coluna user_login (partition key), os dados apresentados estarăo ordenados pelas colunas status e book_isbn, mesmo que năo se use um ORDER BY. Essa ordenaçăo padrăo ainda pode ser definida na criaçăo da tabela como ASC ou DESC para cada uma das clustering columns. Como essa ordenaçăo já é garantida no momento de armazenar a informaçăo no disco, existe um enorme ganho de desempenho, pois o banco de dados năo precisa fazer isso em memória para cada consulta.
Vale informar que o Cassandra só aceita ordenaçăo (ORDER BY) baseado nas clustering columns. Deste modo, a ordenaçăo dos dados para uma consulta pode modificar a forma como modelamos as tabelas. Isto porque o nosso objetivo deve ser executar o SELECT sem precisar especificar uma cláusula ORDER BY e mesmo assim sempre obter os dados na ordem desejada.
Outra maneira que as clustering columns podem afetar a modelagem é que essa ordenaçăo padrăo também irá trazer ótima performance nos filtros por intervalos, por exemplo, um período de data. Assim, se vocę perceber que sua consulta irá precisar desse tipo de filtragem, é fundamental escolher bem as clustering columns.
Distribuiçăo – A chave para a escalabilidade horizontal
Um dos pontos fortes do Cassandra é a sua arquitetura distribuída com suporte a diversas configuraçőes e tamanhos de cluster, desde um único nó a até centenas de nós, como acontece em algumas empresas como eBay, Netflix e Apple.
Essa distribuiçăo é feita de forma automática, năo necessitando que desenvolvedores e arquitetos se preocupem em implementar algum tipo de sharding via aplicaçăo. Um componente conhecido como partitioner é o responsável por essa tarefa.
Um partitioner basicamente é uma funçăo que gera um token (hash) a partir da partition key e entăo distribui os dados entre os nós do cluster baseado nesse token de maneira uniforme e transparente para o desenvolvedor. Em outras palavras, cada nó é responsável por um range compreendido pelo token.
Exemplo de distribuiçăo de dados
Para exemplificar o funcionamento do mecanismo de distribuiçăo de dados, vamos supor que exista uma tabela chamada pessoas_por_nome, que tem como partition key o campo Nome. Dessa forma, essa coluna será usada pelo particionador para gerar os hashes sempre que uma nova linha for inserida na tabela. Para ilustrar melhor essa situaçăo, apresentamos na Tabela 1 alguns valores para a coluna Nome e os seus respectivos hashes, que foram gerados por um partitioner hipotético.
|
Partition Key |
Hash |
|
José |
-2245462676723223822 |
|
Maria |
7723358927203680754 |
|
Joăo |
-6723372854036780875 |
|
Isabel |
1168604627387940318 |
Tabela 1. Partition keys e seus respectivos hashes.
Agora, imagine que o cluster dessa aplicaçăo é composto por quatro máquinas, como exemplificado na Figura 4, e que cada um dos nós é responsável por armazenar os dados de um determinado range do hash gerado pelo partitioner. Por exemplo, nesse cluster o nó C armazenará as linhas que tenham um hash de 0 a 46116860118427387903.
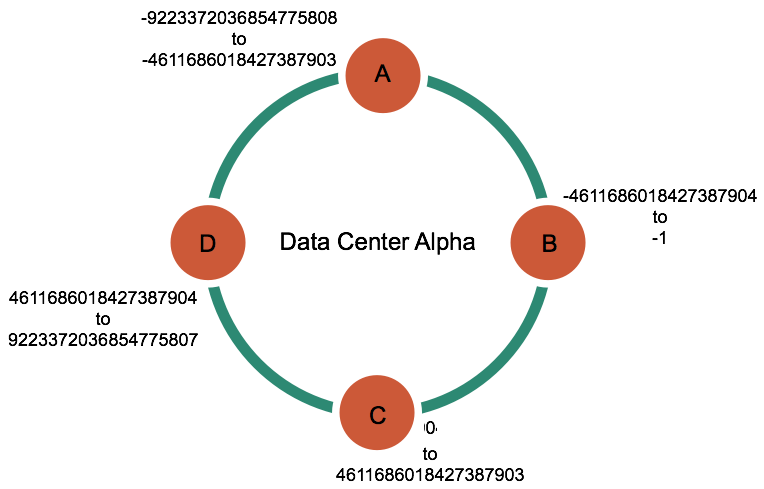
Figura 4. Nós do cluster e seus respectivos ranges - Adaptado de: DataStax.
Considerando o conjunto de dados da Tabela 1 sendo inseridos num cluster com a configuraçăo da Figura 4, teríamos uma distribuiçăo dos dados conforme a Tabela 2. Assim, a linha que tem a coluna Nome igual a Joăo seria armazenada pelo nó A, pois o partitioner gerou um hash para essa partition key o qual fica dentro do intervalo da máquina A.
|
Nó |
Início range |
Fim range |
Partition Key |
Hash |
|
A |
-9223372036854775808 |
-4611686018427387903 |
Joăo |
-6723372854036780875 |
|
B |
-4611686018427387904 |
-1 |
José |
-2245462676723223822 |
|
C |
0 |
4611686018427387903 |
Isabel |
1168604627387940318 |
|
D |
4611686018427387904 |
9223372036854775807 |
Maria |
7723358927 ... |
Confira outros conteúdos:

Black November
Desconto exclusivo para as primeiras 200 matrículas!
Pagamento anual
12x no cartão
De: R$ 69,00
Por: R$ 54,90
Total: R$ 658,80
Garanta o desconto
- Formação FullStack Completa
- Carreira Front-end I e II, Algoritmo e Javascript, Back-end e Mobile
- +10.000 exercícios gamificados
- +50 projetos reais
- Comunidade com + 200 mil alunos
- Estude pelo Aplicativo (Android e iOS)
- Suporte online
- 12 meses de acesso
Pagamento recorrente
Cobrado mensalmente no cartão
De: R$ 79,00
Por: R$ 54,90 /mês
Total: R$ 658,80
Garanta o desconto
- Formação FullStack Completa
- Carreira Front-end I e II, Algoritmo e Javascript, Back-end e Mobile
- +10.000 exercícios gamificados
- +50 projetos reais
- Comunidade com + 200 mil alunos
- Estude pelo Aplicativo (Android e iOS)
- Suporte online
- Fidelidade de 12 meses
- Não compromete o limite do seu cartão
<Perguntas frequentes>
Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programaçăo antes de começar a estudar com vocęs, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda năo tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocęs e logo percebi que săo os melhores do Brasil. É um passo a passo incrível. Só năo aprende quem năo quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocęs estăo fazendo parte da minha jornada nesse mundo da programaçăo, irei assinar meu contrato como programador graças a plataforma.
Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que năo tem como năo aprender, estăo de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tăo presente na vida acadęmica de seus alunos, parabéns!
Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!
Adauto Junior
Já fiz alguns cursos na área e nenhum é tăo bom quanto o de vocęs. Estou aprendendo muito, muito obrigado por existirem. Estăo de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.