Figura 1: Cassandra e Lucene
Atualmente existem diversas características dos bancos NOSQL, em diferentes arquiteturas, formas de armazenamento de informaçăo e estruturas de dados. No entanto apesar dessa grande variedade no número e variedades eles compartilham uma coisa em comum. Eles normalmente buscam pela chave primária. Apesar de conseguir-se manter altamente disponível, inserir e recuperar informaçőes de forma bastante rápida, o fato de que a maioria dos bancos NOSQL somente recuperem pela chave, torna um pouco difícil adaptar a aplicaçăo para o seu uso, já que nem sempre vocę consegue buscar apenas pela chave no banco. Para năo abrir măo da alta disponibilidade e recuperar informaçőes năo apenas em chave, uma boa opçăo certamente é “terceirizar” esse serviço. Por esse motivo será apresentado o Lucene trabalhando em conjunto com um banco nosql, mais precisamente o Cassandra, juntando o bom de dois mundos em sua aplicaçăo.
O Apache Lucene é uma API de busca e indexaçăo de documentos, escrito em Java. Ele é composto por basicamente duas etapas: indexaçăo e pesquisa. Dado o texto primeiro passo é a indexaçăo que processa os dados originais e gera uma estrutura que facilita a busca e gera palavras-chaves, em seguida vem ŕ busca que visa estar buscando a partir das palavras-chaves indexadas e retorna pela semelhança do texto com a consulta. A vantagem é que o Lucene abstrai ao ponto que năo é necessário que o desenvolvedor saiba algoritmo de indexaçăo. Os índices podem ser criados em ambientes distribuídos, aumentando o desempenho e a escalabilidade da ferramenta.
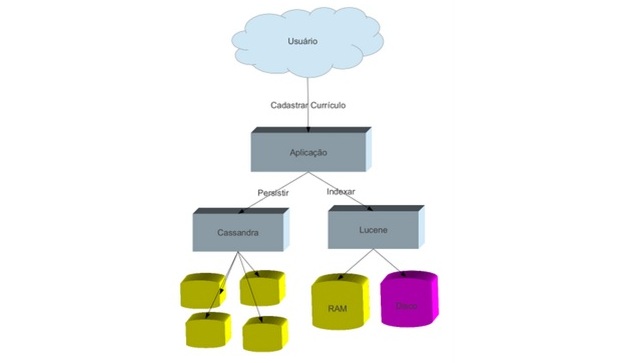
Apresentado um pouco da ferramenta o objetivo agora será apresentar uma prática envolvendo os dois mundos: banco nosql e o Lucene. Para essa parte prática será feita uma aplicaçăo com o objetivo de estar cadastrando currículos. A idéia é bastante simples:
Como o objetivo da aplicaçăo será web, estaremos utilizando a plataforma Java EE em sua versăo mais recente, a versăo 6.0.
No Lucene os índices săo armazenados a partir da interface Direcoty que no momento que eu escrevo possui basicamente duas implementaçőes: Uma para armazenar na memória RAM e para armazenar no disco rígido. Como o objetivo é garantir uma alta disponibilidade estaremos utilizando a opçăo de estar trabalhando com os índices na memória RAM, mas para năo perdemos tais índices estaremos fazendo um backup no disco rígido. Para fazer tal procedimento, usaremos o recurso schedule do EJB 3.1 para de tempos em temos, jogar o que está na memória para o HD.
Listagem 1: Exemplo de gravaçăo em disco
@Schedule(minute = "*/1", hour = "*") public void reindex() { try { Directory disco = FSDirectory.open(new File(Constantes.getIndexDirectory())); luceneManager.backup(directory, disco); } catch (Exception e) { Logger.getLogger(ScheduleService.class.getName()).log(Level.SEVERE, null, e); } }
Desse modo quando a aplicaçăo cair e levantar novamente basta estar carregando as informaçőes do disco para a memória principal novamente. Vale salientar que o diretório precisa ser único para toda a aplicaçăo.
Listagem 2: Método para execuçăo após levantamento da aplicaçăo
@ApplicationScoped public class LuceneManager implements Serializable{ private static final long serialVersionUID = -8280220793266559394L; @Produces private Directory directory; @Inject public void init() { directory = new RAMDirectory(); try { levantarServico(); } catch (IOException e) { Logger.getLogger(LuceneManager.class.getName()).log(Level.SEVERE, null, e); } } public void levantarServico() throws IOException { Directory disco = FSDirectory.open(new File(Constantes.getIndexDirectory())); backup(disco, directory); } public void backup(Directory deDiretorio, Directory paraDiretoria) throws IOException { for (String file : deDiretorio.listAll()) { deDiretorio.copy(paraDiretoria, file, file); // newFile can be either file, or a new name } } }
Uma vez criado o diretório e definido onde estarăo as informaçőes o próximo passo é criar os índices, conforme falado anteriormente ele será a chave tanto para a inserçăo quando a busca das informaçőes. Agora o que falta é a criaçăo do Document que representa para a troca de informaçőes entre o Lucene e sua aplicaçăo. Ele é composto por campos que por sua vez por informaçőes. A relaçăo entre o Lucene e a aplicaçăo se dará da seguinte forma:
Listagem 3: Criando documento
private Document criarDocumento(Pessoa pessoa) throws IOException { Document document = new Document(); document.add(new Field(Constantes.ESTADO_INDICE,pessoa.getEndereco().getEstado(), Store.YES, Index.NOT_ANALYZED_NO_NORMS)); document.add(new Field(Constantes.ID_INDICE,pessoa.getNickName(), Store.YES, Index.NOT_ANALYZED_NO_NORMS,TermVector.WITH_POSITIONS_OFFSETS)); document.add(new Field(Constantes.TUDO, getConteudoCurriculo(pessoa), Store.NO, Index.ANALYZED)); return document; }
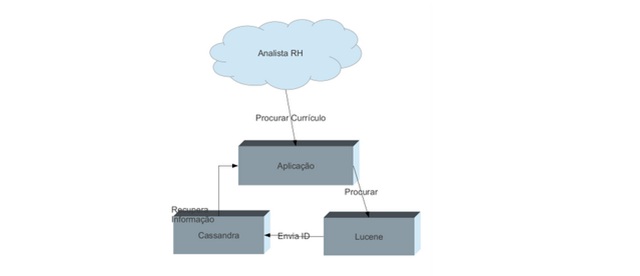
Uma vez essa informaçăo armazenada no Cassandra e indexada no Lucene, o ciclo da aplicaçăo se dará da seguinte forma:
Figura 2: Funcionamento para o usuário
Figura 3: Funcionamento para o analista
Pronto! Dessa forma quanto a inserçăo quanto a busca serăo feitas de maneiras rápidas, o Cassandra possui o recurso de índices secundários que permite que existam campos de busca além da chave, mas isso faz com que o banco perca velocidade com o crescimento desses campos especiais. Uma outra forma de deixar a busca ainda mais rápida seria deixar os resultados dessa busca em um cachę, mas isso serăo cenas para um próximo capítulo.
Falando um pouco mais sobre o Lucene existem alguns frameworks que já se integram com o Lucene. É o caso do hibernate search que é o hiberante, para banco relacional, utilizando o Lucene, solr é um servidor de busca que usa o Lucene como motor de busca e o solandra que é um solr para o Cassandra.
Nesse artigo foi apresentado um problema existente na maioria dos bancos NOSQL, a busca de campos além da chave. Para resolver tal problema foi demonstrado um trabalho em conjunto com o Lucene, ferramenta de indexaçăo de documentos, além de apresentar alguns conceitos da ferramenta.

Faça a sua matrícula
Pagamento anual
12x no cartão
De: R$ 69,00
Por: R$ 64,90
Total: R$ 778,80
Garanta o desconto
Pagamento recorrente
Cobrado mensalmente no cartão
De: R$ 79,00
Por: R$ 64,90 /mês
Total: R$ 778,80
Garanta o desconto
Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programaçăo antes de começar a estudar com vocęs, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda năo tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocęs e logo percebi que săo os melhores do Brasil. É um passo a passo incrível. Só năo aprende quem năo quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocęs estăo fazendo parte da minha jornada nesse mundo da programaçăo, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que năo tem como năo aprender, estăo de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tăo presente na vida acadęmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tăo bom quanto o de vocęs. Estou aprendendo muito, muito obrigado por existirem. Estăo de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.