


Por que eu devo ler este artigo:O tema
abordado neste artigo é útil na implementaçăo de sistemas de busca textual que
requerem alto desempenho diante de grandes volumes de dados. Através de uma
ferramenta leve e de fácil instalaçăo, o Apache Lucene oferece uma soluçăo open source e multiplataforma para
realizaçăo de consultas sobre dados textuais de diferentes origens e formatos,
tais como páginas HTML e arquivos PDF.
Autores: Wanderley Panosso e Paulo Quicoli
Com o crescimento da Web e da Computaçăo em Nuvem, fica cada vez mais óbvio um grande desafio presente quando o objetivo é desenvolver softwares que possam atender a demandas reais, porém inimagináveis em um passado năo muito distante: pesquisas eficiente e de alto desempenho. Devido ao grande volume de informaçăo complexa existente, somado ŕ quantidade de usuários que utilizariam simultaneamente esses softwares, executar pesquisas relevantes e em tempo satisfatório năo é mais uma tarefa simples e muitas vezes pode vir a ser um fator determinante para a aceitaçăo dos usuários.
O fato é que em geral SGBDs (Sistemas Gerenciadores de Bancos de Dados) convencionais normalmente năo săo mais o suficiente para armazenar e ao mesmo tempo executar pesquisas nos volumes de dados existentes e acabam se tornando um dos maiores gargalos para a escalabilidade em sistemas que requerem tais habilidades. Imagine, por exemplo, motores de pesquisa web como Google e Bing dependendo de bancos de dados relacionais famosos no mercado. Agora imagine milhőes de usuários executando consultas em um período menor que um segundo e esperando receber resultados ordenados pelas informaçőes mais relevantes sobre os termos pesquisados em um tempo aceitável. Provavelmente qualquer SGBD relacional năo seria capaz de executar tal tarefa e o motivo é que eles simplesmente năo săo feitos para isso, já que săo projetados primeiramente para garantir a integridade das informaçőes, o que é quase sempre feito por meio de transaçőes.
Por isso, para resolver esses problemas é primordial utilizar um motor de pesquisa (Search Engine) ou sistema de recuperaçăo de informaçăo (Retrieval Information System). Esse tipo de soluçăo objetiva garantir que pesquisas em grandes volumes de informaçăo possam ser executadas satisfatoriamente. Um ponto fundamental a ser compreendido é que esse tipo de soluçăo normalmente tem como objetivo primário indexar grandes volumes de informaçőes a serem pesquisadas, caso a integridade das informaçőes seja de extrema importância é imprescindível que as mesmas também sejam armazenadas em outros meios como bancos de dados tradicionais, por exemplo. Isso ficará mais claro ao decorrer desse artigo.
No caso de Google e Bing, estes possuem soluçőes próprias e customizadas para atender todas as necessidades dos enormes ecossistemas ao qual eles pertencem, porém existem várias outras soluçőes de sistemas de recuperaçăo de informaçőes que resolvem a maioria dos problemas relacionados a pesquisas em grandes volumes de informaçăo que podem ser utilizados no desenvolvimento de várias soluçőes de software.
Este artigo trata especificamente do Apache Lucene, uma biblioteca de busca textual que permite executar pesquisas de alto desempenho em volumes năo triviais de informaçőes. Lucene é open source e está licenciada sob a licença Apache, o que permite sua utilizaçăo tanto em softwares de código aberto como em aplicaçőes comerciais sem nenhum problema legal. Lucene também é utilizada em vários sistemas de grande porte mundialmente conhecidos, como é o caso da Amazom e do Twitter que recebem até vários milhares de consultas por segundo, dependendo da hora e do dia. Um outro nome que está se tornando mundialmente conhecido, pelo menos entre desenvolvedores de software, é Elasticseach, uma plataforma online especialista em indexaçăo e consultas de grandes volumes de dados, utilizada pelo portal globo.com, e que também utiliza Apache Lucene como seu motor de pesquisas.
Índices
Uma das peças fundamentais de motores de pesquisa textual săo os índices. Esses motores coletam as informaçőes a serem indexadas, as processam e criam estruturas específicas que permitem a execuçăo de consultas com performance superior a outros tipos de consultas que năo fazem uso dessas técnicas. Essas estruturas săo chamadas de índices. Sem indexar as informaçőes, executar qualquer tarefa seria muito custoso, visto que seria necessário verificar todo o conteúdo da base de informaçőes através da força bruta, o que causaria lentidăo em casos onde a quantidade de dados é muito extensa. Por exemplo, executar uma pesquisa na web seria impraticável.
Existem várias abordagens para a criaçăo de índices dependendo do tipo de informaçăo a ser indexado, porém, no caso de informaçăo textual, a abordagem mais utilizada é conhecida como Índice Invertido (Inverted Index). Um índice invertido, demonstrado na Figura 1, é basicamente uma lista de termos associada aos documentos onde esses termos foram encontrados e que deveriam ser retornados caso o termo se enquadre nos critérios da pesquisa.
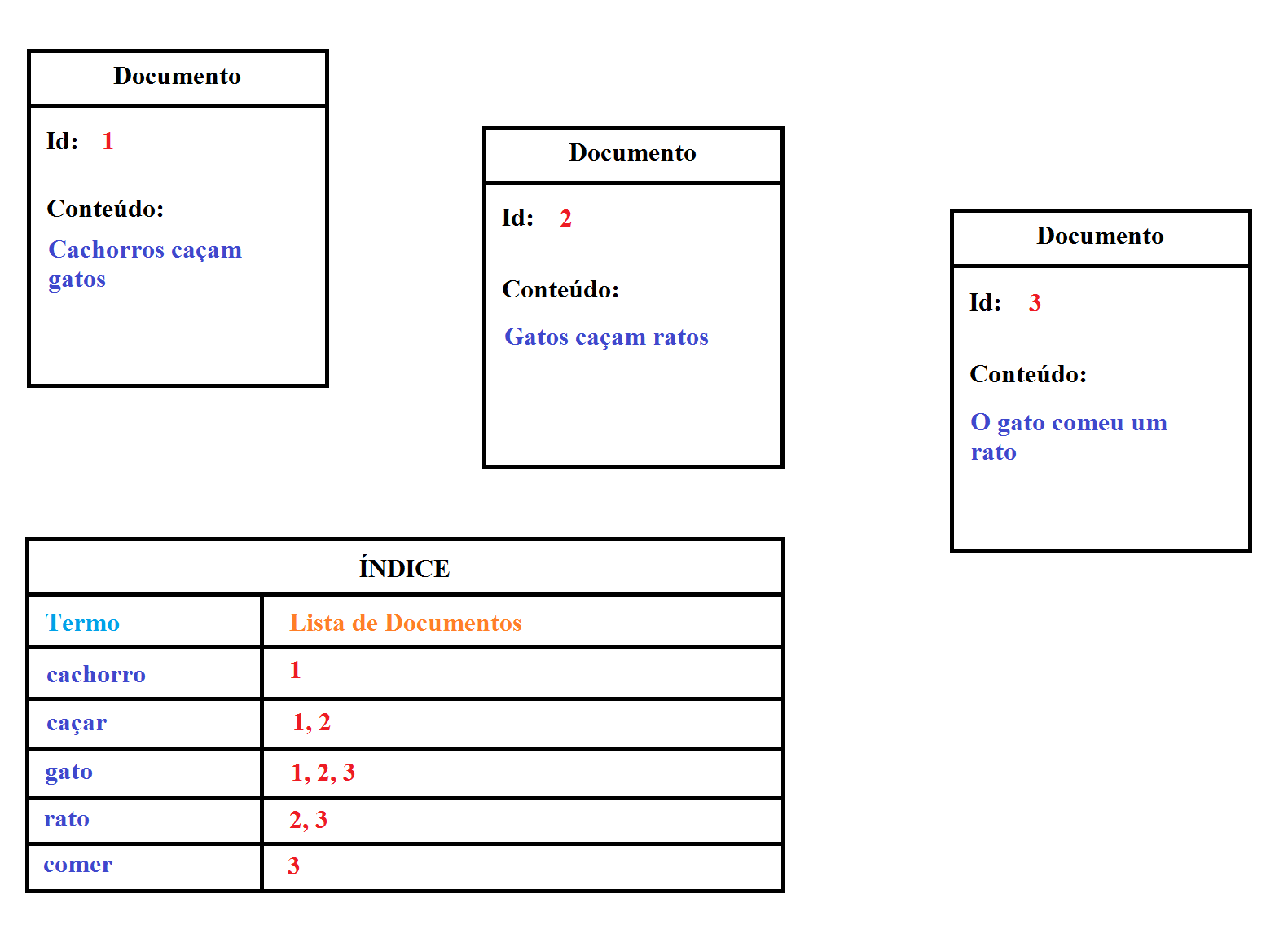
Figura 1. Exemplo ilustrativo de um Índice Invertido
Como demonstra essa figura, todos os documentos săo processados, analisados e tęm seus termos extraídos e adicionados a uma lista onde cada elemento armazena os Ids dos documentos que contęm aquele termo. Caso o termo já exista na lista, o Id do documento é adicionado ŕ sua lista de documentos. Isso permite que pesquisas sejam executadas com muito mais rapidez, já que é necessário apenas pesquisar uma lista estruturada com os possíveis resultados das pesquisas já pré-resolvidos, caso contrário seria necessário abrir todos os documentos, verificar seus conteúdos e caso encontrado o que se deseja, adicioná-los a uma lista temporária que se tornaria o resultado da pesquisa.
Note que a Figura 1 é apenas uma ilustraçăo simples de como um índice realmente se parece, e abstrai muitas complexidades existentes em uma implementaçăo realista. Por exemplo, a lista de documentos năo armazena apenas o Id dos documentos, mas também o tamanho do documento e informaçőes sobre cada ocorręncia do termo encontrado, tais como suas posiçőes iniciais, finais e tamanho, para que consultas mais detalhadas possam ser executadas posteriormente, como é o caso de consultas que buscam por documentos iniciando ou terminando com determinados termos.
Análise
Note que a lista de termos é diferente das palavras contidas nos documentos, isso acontece devido a um processo de análise que é responsável por verificar cada documento e indexá-lo para consulta. Nesse caso o Analisador (“Analyzer”) utilizou uma abordagem muito comum entre os motores de pesquisa que transforma palavras no plural em palavras no singular, como no caso dos termos “cachorro”, “gato” e “rato”, que podem ser encontrados no plural nos documentos 1 e 2 porém foram indexados como termos no singular. Além disso, o Analisador năo diferenciou palavras com letras maiúsculas ...

Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.