Conhecer o novo paradigma que vem surgindo na área de banco de dados, noSQL, pode ser considerado muito importante para aqueles que trabalham com banco de dados ou tomadores de decisão da área de tecnologia das organizações. É sempre importante estar atento a novas tecnologias e como elas resolvem problemas provenientes das limitações das tecnologias existentes.
Relacionado: Curso de NoSQL
Guia do artigo:
Através deste artigo temos a pretensão de apresentar de forma concisa os fundamentos, características e diferenciais dos bancos de dados NoSQL. Além disso, a autora deste artigo acredita ser de suma importância apresentar os fundamentos relacionados ao Banco de Dados Relacional, assim como realizar diversas comparações entre os dois modelos, para que haja uma melhor compreensão e abstração deste novo paradigma chamado Banco de Dados NoSQL.
A forma como nos comunicamos, trocamos informações e criamos conteúdo mudou muito ao longo dos anos. Estamos vivenciando uma época onde as aplicações Web têm revolucionado o mundo em diversos sentidos e a tendência é que este crescimento habilite a criação de uma série de novas aplicações. O grande volume de dados gerados por estas aplicações Web, aliado com a nova forma de interação com o usuário (dinâmica, eficiente e intuitiva), a escalabilidade sob demanda e a necessidade de um alto grau de disponibilidade, tem fomentado o aparecimento de novos paradigmas e tecnologias.
Todos nós sabemos que o banco de dados relacional tem sido usado há muito tempo em larga escala pelo mundo afora, e desde sua criação, por volta do início dos anos 1970, esse tem sido o tipo de banco de dados mais utilizado em empresas que possuem um intenso volume de dados para serem armazenados [1]. Pensando justamente neste imenso volume de dados que tende a crescer a cada momento, começa a se observar que os bancos de dados relacionais possuem certos fatores limitantes, principalmente quando nos referimos a escalabilidade de um sistema [3]. Este ambiente envolto de limitações que os bancos de dados relacionais têm propiciado instigou o surgimento de outros tipos de modelos alternativos de banco de dados que possam suprir essa necessidade.
Diante de tantas dificuldades que são encontradas à medida que as necessidades surgem, está crescendo uma nova geração de banco de dados que vem ganhando bastante força e espaço, estes são conhecidos como NoSQL (“Not Only SQL”) [4], este é o termo genérico que define um banco de dados não-relacional. Este modelo veio com a proposta de atender e gerenciar os grandes volumes de dados, buscando um alto desempenho e disponibilidade. Neste contexto, neste artigo serão apresentadas características desses bancos de dados e se discute ainda como essas novas soluções podem abordar questões que estão sendo atualmente enfrentadas.
O banco de dados relacional surgiu como um sucessor dos modelos hierárquicos de rede. Estas estruturas, por sua vez, foram muito utilizadas nos primeiros sistemas de mainframe. No entanto, devido ao grande número de restrições de relacionar estruturas no mundo real, este modelo foi perdendo força para dar lugar aos bancos de dados relacionais [5]. Este, por último, se tornou o grande padrão para a maioria dos Sistemas Gerenciadores de Banco de Dados (SGBDs). Outro ponto importante a salientar sobre o modelo relacional é a utilização de restrições de integridade que garantem a consistência dos dados em um banco de dados. Estas restrições, em sua grande maioria, são conhecidas como chaves primárias PRIMARY KEY e chaves estrangeiras FOREIGN KEY.
Outra característica que devemos ressaltar no Modelo Relacional é o que chamamos de processo de Normalização. Seu objetivo é a aplicação de uma série de passos com determinadas regras sobre a tabela do banco de dados de forma a garantir o projeto adequado dessas tabelas. Um conceito básico da normalização consiste na separação de dados referentes a elementos distintos em tabelas distintas, associadas através da utilização das chaves. Essas regras permitem um armazenamento consistente e, além disso, um eficiente acesso aos dados, reduzindo redundâncias e diminuindo as chances dos dados se tornarem inconsistentes [7].
Além disso, o modelo relacional começou a adotar uma linguagem para a manipulação e consulta destes dados. Estamos nos referindo ao SQL (Structured Query Language). Criada originalmente pela IBM e inspirada na álgebra relacional, ganhou grande destaque pela facilidade do seu uso, diferenciando-a assim de todas as outras linguagens procedurais da época. Devido a sua grande utilização em 1982, o American National Standard Institute (ANSI) tornou o SQL o padrão oficial de linguagem em ambiente relacional, consolidando assim a sua posição de dominância no modelo relacional [1].
Não é possível falar de SQL sem falar também do SGBD, que se caracteriza como um conjunto de programas que permitem armazenar, modificar e extrair em um banco de dado. Falando mais atentamente sobre o assunto, podemos afirmar que o SGBD oferece aos seus usuários processos de validação, recuperação de falhas, segurança, otimização de consultas, garantia de integridade dos dados, entre outros [8].
Além disso, os SGBDs Relacionais oferecem a possibilidade de vários usuários acessarem e manipularem um mesmo banco de dados simultaneamente e principalmente de forma eficiente, algo que é fundamental em sistemas de grande porte.
Os SGBDs relacionais ainda possuem a possibilidade do sistema se recuperar adequadamente de possíveis falhas, ou seja, ele tem a capacidade de voltar ao ponto anterior em que ocorreu a falha, permitindo assim um banco de dados mais consistente.
Vale ressaltar ainda que os bancos de dados relacionais seguem o modelo ACID para preservar a integridade de uma transação. Este conjunto de procedimentos é dividido em quatro propriedades, e são elas:
Todos esses diferentes recursos auxiliaram a manter os SGBDs Relacionais sempre em uma posição de predominância entre os mais diversos tipos de ambientes computacionais, mas ao mesmo tempo, não impediu o aparecimento de determinados problemas, isso devido ao grande crescimento do volume de dados presente nos bancos de dados de algumas organizações.
Nos dias de hoje, o volume de dados de certas organizações, como podemos citar o caso do Facebook, que atingiu o nível de petabytes (em 2011 este volume de dados ultrapassou 30 petabytes (30 mil terabytes), sendo que menos de um ano antes o volume era de 20 petabytes). Este é um exemplo real de como esse crescimento de dados tem expandido rapidamente [11]. No caso destes tipos de organizações, a utilização dos SGBDs relacionais tem se mostrado muito problemática e não tão eficiente.
Os principais problemas encontrados com a utilização do Modelo Relacional estão principalmente na dificuldade de conciliar o tipo de modelo com a demanda da escalabilidade que está cada vez mais frequente.
Podemos tomar como exemplo o próprio Facebook. Digamos que se o sistema está rodando sobre um SGBD relacional e houver um crescimento do número de usuários, consequentemente haverá uma queda de performance. E para superar este problema seria necessário fazer um upgrade no servidor ou aumentar o número de servidores.
Se o número de usuários continuasse a crescer intensamente, tais soluções apresentadas não se mostrariam suficientes, pois o problema passa a se concentrar no acesso à base de dados. Neste caso, o que poderia ser feito para resolver este problema de escalabilidade seria aumentar o poder do servidor, aumentando sua memória, processador e armazenamento. Este tipo de solução é chamado de Escalabilidade Vertical. Por outro lado, poderíamos aumentar o número de máquinas no servidor web, chamamos esta alternativa de Escalabilidade Horizontal [13].
Vamos citar novamente o Facebook, onde suas aplicações continuam sempre a crescer, chega um momento em que o banco de dados não consegue atender todas as requisições em um tempo hábil. Neste momento poderíamos apelar para a Escalabilidade Vertical e fazer o upgrade na máquina em que está rodando o banco de dados. No entanto, chega um momento em que a capacidade da máquina chega ao limite do orçamento para conseguir uma máquina realmente eficiente. Dessa forma, o próximo passo seria utilizar a Escalabilidade Horizontal, ou seja, colocar mais máquinas rodando o banco de dados. Tal tarefa pode parecer simples, porém, no momento em que escalonamos o banco em diversas máquinas é necessário realizar na grande maioria das vezes uma série de configurações e alterações nas aplicações para que tudo funcione como esperado na nova arquitetura distribuída.
Ainda no campo dos exemplos, vamos imaginar um sistema fictício, e que não se sabe ao certo os campos de determinada entidade, agora imagine este mesmo sistema do dia para a noite sendo acessado por milhares e milhares de pessoas. No outro dia, ao observar sua caixa de email você percebe que diversos usuários possuem ideias realmente inovadoras, porém, para implementar essas ideias no seu sistema é necessário que o banco de dados praticamente por inteiro seja refatorado, afinal, será necessário realizar diversas mudanças estruturais na base de dados . Com este problema em mãos podemos perceber que o Modelo Relacional está focado nos relacionamentos entre as entidades e que isso, por muitas vezes, torna mais “burocrática” a implementação de novas funcionalidades, além dos problemas voltados para a escalabilidade que já havíamos falado, quando há um acesso muito grande de usuários ao sistema.
Como esse intenso volume de dados vem aumentando e pela sua natureza estrutural, os desenvolvedores perceberam a dificuldade ao se organizar dados no Modelo Relacional. É neste ponto que o foco das soluções não-relacionadas está direcionado.
Pensando em solucionar diversos problemas relacionados à escalabilidade, performance e disponibilidade, projetistas do NoSQL promoveram uma alternativa de alto armazenamento com velocidade e grande disponibilidade, procurando se livrar de certas regras e estruturas que norteiam o Modelo Relacional. Se por um lado havia um rompimento das regras do Modelo Relacional, por outro lado havia ganho de performance, flexibilizando os sistemas de banco de dados para as diversas características que são peculiares de cada empresa. Esta flexibilidade passou a se tornar fundamental para suprir os requisitos de alta escalabilidade necessários para gerenciar grandes quantidades de dados, assim como para garantir uma alta disponibilidade destes, característica fundamental para as aplicações Web 2.0. Algumas grandes organizações passaram a investir em seus próprios SGBDs baseando-se na ideia do NoSQL.
O termo NoSQL foi inicialmente utilizado em 1998 a partir de uma solução que não oferecia uma interface SQL, mas este sistema tinha como base o Modelo Relacional. Futuramente, o modelo passou a representar determinadas soluções que se tornavam melhores que a utilização do Modelo Relacional, desde então passou a utilizar a abreviação Not Only SQL (Não apenas SQL) [13]. A proposta dos bancos NoSQL na realidade não é extinguir o Modelo Relacional, mas utilizá-lo em casos onde é necessária uma maior flexibilidade na estruturação do banco.
Este movimento está bastante enraizado no open source. E apesar de existirem muitos bancos de dados nesta categoria, o movimento passou a ganhar mais força quando determinadas empresas consideradas gigantes da tecnologia passaram a utilizar suas próprias implementações proprietárias [14]. Neste caso, podemos citar o Google, que desde 2004 investe no BigTable que foi desenvolvido para suprir as necessidades de armazenamento da empresa, baseado na filosofia do alto desempenho, escalabilidade e disponibilidade [15]. Além disso, temos também o famoso Cassandra, desenvolvido pelo Facebook para lidar com o grande fluxo de informações [16]. Em 2010 o Cassandra mostrou ser um banco de dados consolidado e passou a ser utilizado pelo Twitter, que utilizava o MySQL anteriormente [17].
Temos ainda o Apache CouchDB, que é um banco de dados open source orientado a documentos que projetado especialmente para suportar computação distribuída em larga escala [18].
Apesar da nomenclatura de todos esses bancos de dados serem NoSQL, eles não são completamente iguais, possuem na verdade muitas características semelhantes e muitas particularidades que os diferenciam.
Os bancos de dados NoSQL apresentam determinadas características que considero importantes de serem consideradas neste artigo, além disso, são essas características que os tornam tão diferentes dos bancos de dados relacionais. Algumas dessas características são:
Agora que falamos brevemente sobre as principais características nos bancos de dados NoSQL, é importante ressaltar algumas técnicas utilizadas para a implementação de suas funcionalidades. Entre elas estão:
Neste caso, temos quatro categorias do NoSQL que as diferenciam entre si:
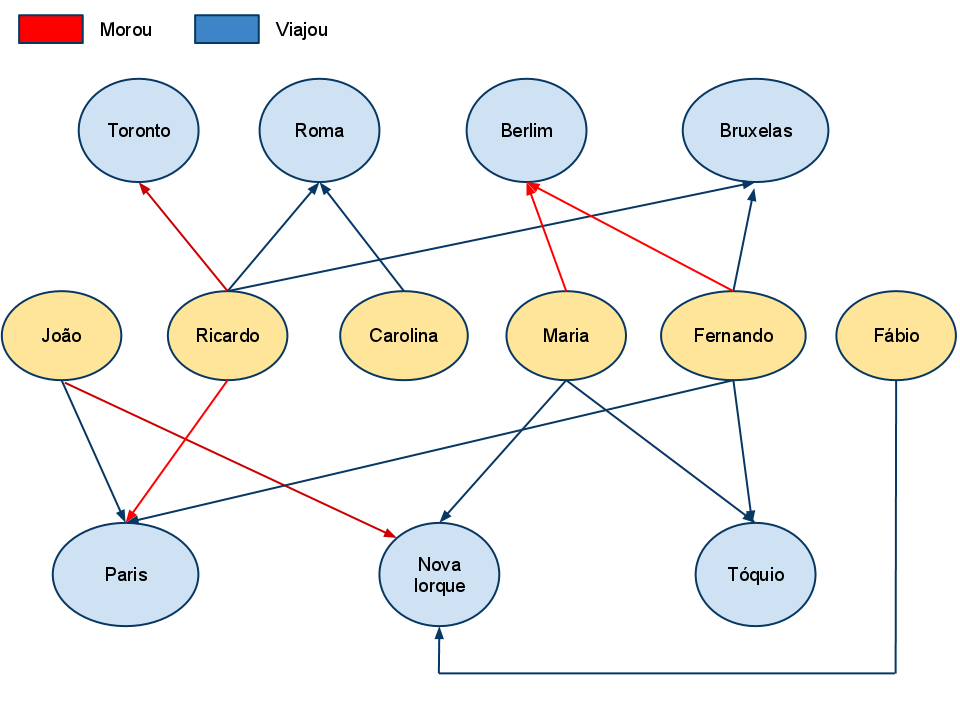
Como exemplo, podemos citar o Neo4j que é um banco de dados open source. O Neo4J trata-se de um banco de dados baseado em grafos desenvolvido em Java. Além de possuir suporte completo para transactions, ele também trabalha com nós e relacionamentos. Ainda no exemplo da Figura 4, temos diversas pessoas: João, Ricardo, Carolina, Maria, Fernando e Fábio que representam nós do grafo e estão conectadas a cidades que visitaram ou residiram. Por exemplo: Ricardo viajou para Roma e Bruxelas e já residiu em Toronto e Paris. A partir de cada cidade, precisamos dos relacionamentos de entrada que também sejam do tipo “viajou” e com isso encontramos pessoas que viajaram para o mesmo lugar que Ricardo, neste caso, Carolina e Fernando.
Levando em consideração tudo o que foi dito, é fundamental ressaltar que nenhum modelo é superior a outro. Na realidade, o que ocorre é que um modelo pode ser mais adequado para ser utilizado em certas situações. Por exemplo, para a utilização de um banco de dados de manipulação de dados que frequentemente serão escritos, mas não lidos (um contador de hits na Web, por exemplo), pode ser usado um banco de dados orientado a documento como o MongoDB. Já aplicativos que demandam alta disponibilidade, onde a minimização da atividade é essencial, podemos utilizar um modelo orientado a colunas como o Cassandra. Aplicações que exigem um alto desempenho em consultas com muitos agrupamentos podem utilizar um modelo orientado a grafos.
O importante é que no momento da criação do aplicativo os desenvolvedores utilizem a melhor solução que se encaixa no perfil desejado. Utilizar a solução adequada ao criar o banco de dados significa uma diminuição dos custos para a sua criação, assim como um banco eficiente no processamento de dados do ponto de vista das suas necessidades.
A partir do momento em que se pensa na possibilidade de utilizar um banco de dados NoSQL ao invés de um modelo relacional, é preciso levar algumas questões em consideração, como critérios de escalonamento, consistência e disponibilidade de dados. Vamos apresentar algumas discussões comparativas mais marcantes no que se diz respeito a estes três conceitos.
Falar sobre escalabilidade é essencial porque é neste aspecto que os bancos de dados NoSQL possuem uma grande vantagem em relação aos SGBDs tradicionais, basicamente por terem sido criados para essa finalidade. Os bancos de dados relacionais possuem uma estruturação que não a permite tanta flexibilidade, além disso, é menos adaptada para situações em que o escalonamento se faz necessário.
Para alcançar uma melhor escalabilidade, os bancos de dados relacionais utilizam o recurso da escalabilidade vertical (scale up) que tem como característica a simplicidade de sua implementação e esta tem sido a forma mais indicada para se realizar o escalonamento do banco de dados. A partir do momento em que uma aplicação está sendo demasiadamente acessada por um número muito grande de usuários, este tipo de escalonamento passa a não ser mais suficiente. O próximo passo consiste em escalonar o próprio banco de dados, que consiste basicamente em distribuir o banco em várias máquinas, particionando os dados. Conhecido também como sharding ou escalonamento horizontal. Esse tipo de escalonamento se mostra muito complexo ao ser implementado em um SGBD relacional devido à dificuldade em se adaptar a toda estrutura lógica do Modelo Relacional, primeiro porque os SGBDs relacionais obedecem aos critérios de normalização e o processo de sharding vai contra a tudo isso, pois se caracteriza pela desnomarlização dos dados. Segundo ponto, há uma mudança de paradigma em relação ao processo de escalonamento. Enquando SGBDs tradicionais trabalham para reforçar o servidor, o sharding tem como objetivo trabalhar com o escalonamento horizontal, distribuindo seus dados em diversos setores. Terceiro ponto, o volume de dados por máquina é minimizado devido a esta distribuição, afinal, conjunto de dados menores são mais simples de serem gerenciados, acessados e atualizados. Por último, a disponibilidade do sistema é otimizada em relação ao modelo relacional, pelo fato de que se houver a queda do sistema em uma máquina não irá causar a interrupção do mesmo.
Esta questão da disponibilidade demonstra muita preocupação em determinadas organizações. Podemos citar um evento que ocorreu em 2008, em que a rede social Twitter ficou fora do ar durante 84 horas, neste evento o Twitter ainda utilizava o PostgreSQL, sendo considerada a rede social mais instável daquele ano [30]. A partir de 2009, quando começou a utilizar o Cassandra, outro evento similar ocorreu, porém o site ficou fora dor ar durante 23 horas e 45 minutos [17].
Neste quesito, o banco de dados NoSQL se destaca pela maior disponibilidade, maior rapidez nas consultas, paralelismo de atualização de dados e maior grau de concorrência.
Os bancos de dados NoSQL foram projetados para este fim, e da forma mais simples e natural possível. Como exemplo podemos citar o MongoDB que inclui um módulo de sharding automático que permite a construção de um cluster de banco de dados escalado horizontalmente para, dessa forma, incorporar novas máquinas de forma dinâmica [19].
Outra coisa que devemos notar ao fazer a comparação de uma banco de dados relacional e NoSQL é no que se refere ao controle de concorrência. Se por um lado, no Modelo Relacional utilizamos locks para garantir que dois usuários não acessem o mesmo item simultaneamente, no banco de dados NoSQL utilizam-se outras estratégias que acabam por permitir um maior grau de concorrência. Para citar uma dessas estratégias podemos citar como exemplo o banco de dados CouchDB que utiliza o MMVC. A ideia principal é criar diversas versões dos documentos e permitir a atualização sobre uma dessas versões mantendo ainda a versão desatualizada. Agindo dessa forma não há a necessidade de bloquear os itens dos dados.
Ao se pensar em substituir um banco de dados relacional por um NoSQL, a arquitetura fica vulnerável à perda de consistência, porém, pode-se ganhar em flexibilidade, disponibilidade e performance. Outra coisa interessante para ser destacada são as diferenças de paradigmas utilizadas no Modelo Relacional e nos bancos NoSQL. No que diz respeito a este primeiro, temos o ACID que força a consistência ao final de cada operação, já o paradigma BASE, que é utilizado comumente pelo segundo, permite que o banco de dados eventualmente seja consistente, ou seja, o sistema só torna-se consistente no seu devido momento.
Para compreendermos melhor todas essas diferenças, observe a Tabela 1 que exemplifica de forma concisa alguns dos conceitos descritos neste artigo.
| Banco de Dados Relacional | Banco de Dados NoSQL | |
|---|---|---|
| Escalonamento | É importante lembrar que é possível ser feito o escalonamento em um Modelo Relacional, no entanto, é muito complexo. Possui uma natureza estruturada, portanto, a inserção dinâmica e transparente de novos nós a tabela não é realizada naturalmente. | Não possui um esquema pré-definido fazendo com que este tipo de modelo seja flexível o que favorece a inserção transparente de outros elementos. |
| Consistência | Neste quesito, o Modelo Relacional se mostra forte. As suas regras de consistência são bastante rigorosas no que diz respeito à consistência das informações. | É realizada eventualmente no modelo: tem apenas a garantia que se não houver nenhuma atualização nos dados, todos os acessos aos itens devolverão o último valor que foi atualizado. |
| Disponibilidade | Por não conseguir trabalhar de forma eficiente com a distribuição de dados, o Modelo Relacional acaba não suportando uma demanda muito grande de informações. | Outro ponto forte neste modelo é o que diz respeito à disponibilidade, pois possui um alto nível de distribuição de dados, permitindo assim que seja possível fazer com que um enorme fluxo de solicitações aos dados seja atendido com a vantagem do sistema ficar indisponível o menor tempo possível. |
Com o grande crescimento do volume de dados em determinadas organizações, os bancos de dados NoSQL tem se tornado uma grande alternativa quando nos referimos a escalabilidade e disponibilidade, fatores estes que se tornam imprescindíveis em algumas aplicações Web.
Para realizar a migração de um SGBD Relacional para um banco de dados NoSQL é preciso levar diversos fatores em consideração. A empresa em questão deve mensurar as diversas vantagens e desvantagens propostas por ambos os modelos, e estes critérios de comparação são dos mais diversos tipos, indo desde a escalabilidade do sistema, passando por avaliação sobre consistência de dados e quão importante é a disponibilidade do banco de dados para o sistema.
Em relação a bancos de dados relacionais, sabemos da sua “experiência” no mercado, no qual é utilizado em larga escala. Além disso, sabemos da solidez de suas soluções que são mais maduras e experimentadas. Enquanto isso, os bancos de dados NoSQL ainda estão conquistando seu espaço no mercado e definindo os seus próprios padrões. Além disso, sabemos que para diversas organizações a consistência de dados se torna um fator determinante e as transações através dos SGBDs Relacionais são a melhor alternativa para lidar com esse problema.
Por outro lado, temos o problema do grande volume de dados enfrentado por diversas empresas, assim como a necessidade que estes sistemas estejam disponíveis para os seus usuários. Nestas situações, os bancos de dados NoSQL acrescentam diversos pontos positivos, primeiro pela sua possibilidade de escalonamento e pela simplicidade do seu modelo, onde não há esquemas pré-definidos, e segundo pela existência de uma grande distribuição de dados, oferecendo assim um maior suporte de solicitações a estes dados para serem atingidos. Adicionalmente, é importante ressaltar que uma escalabilidade em alto grau se faz necessária a empresas que utilizam um banco de dados de grande porte e onde a disponibilidade é um fator decisivo. Acredito que a utilização de um banco de dados NoSQL onde a escalabilidade e a disponibilidade não se demonstre determinante, ainda é algo que é necessário discutir.
Neste sentido, este artigo teve a finalidade de explicar as principais características dos bancos de dados NoSQL e de forma mais concisa o banco de dados Relacional, assim como realizar algumas análises comparativas entre estes dois modelos que atualmente disputam e complementam o mercado. Ressaltando que não existe um banco de dados superior ao outro, a decisão do uso de cada um se refere à necessidade que a empresa está enfrentando.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.