O objetivo deste artigo é apresentar o conceito de indexed views do SQL Server e mostrar como implementar e utilizar esse tipo de view para otimizar consultas.
As views são conhecidas também como “tabelas virtuais”, já que apresentam uma alternativa para o uso de tabelas no acesso a dados. Uma view nada mais é que um comando SELECT encapsulado em um objeto. A sintaxe para a criação de uma view é a apresentada na Listagem 1.
CREATE VIEW nome_da_visão [(nome_da_coluna) [ , nome_da_coluna] ...) ] AS subconsulta;Veja um exemplo de criação e uso de view na Listagem 1.
Use NorthWind go
create view vi_vendas_mes
As
Select ano = datepart(yyyy,OrderDate),
mes = datepart(mm,OrderDate),
qtde_total = sum(Quantity)
from Orders o
inner join
[Order Details] od on o.OrderId = od.OrderId
group by
datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate)
go
select * from vi_vendas_mês
go
ano mes qtde_total contador
----------- ----------- ----------- --------------------
1996 7 1462 59
1996 8 1322 69
1996 9 1124 57
1996 10 1738 73
1996 11 1735 66Dentre as vantagens da utilização de views, podemos citar :
As views encapsulam comandos SELECT, o que significa que, sempre que elas são acionadas, os comandos SELECT associados a elas são executados. As views não criam repositórios para os para dados que retornam (como faz a tabela). Ora, que bom seria se pudéssemos “materializar” em uma tabela o resultado do comando SELECT encontrado na view, criando índices que facilitassem seu acesso. Pois bem, as indexed views fazem justamente isso. Executar um SELECT em uma indexed view tem o mesmo efeito que executar um select numa tabela convencional.
O principal objetivo das indexed views é aumentar a performance, e a vantagem do SQL Server é permitir que os planos de execução considerem a indexed view como um meio de acesso aos dados, mesmo que o nome da view não tenha sido explicitado na query. Isso é possível na versão Enterprise Edition do SQL Server 2000, onde o otimizador de comandos pode selecionar os dados diretamente na indexed view (em vez de selecionar os dados brutos existentes na tabela), como veremos a seguir.
Por exemplo, a Listagem 2 mostra a diferença no resultado de um comando quando a propriedade concat_null_yields_null é alterada.
set concat_null_yields_null ON print null + ‘abc’
--------------------------------------
Set concat_null_yields_null OFF
print null + ‘abc’
--------------------------------------
abcImagine o que aconteceria se a indexed view fosse criada com a propriedade concat_null_yields_null ativada, mas a sessão atual estivesse com essa propriedade desativada - o mesmo SELECT iria conduzir a resultados diferentes!
Esse problema foi resolvido de forma simples – para criar e utilizar indexed views, é obrigatório configurar o ambiente de acordo com uma lista de valores padrão. Desse modo, é impossível obter resultados diferentes, pois a view simplesmente não funcionará se alguma das configurações estiver definida com um valor fora do padrão.
A Tabela 1 exibe essas configurações e seus respectivos valores padrão.
| Configuração | Id (*) | Estado exigido p/ indexed views | Padrão do SQL Server 2000 | Padrão em conexões OLE DB (=ADO) ou ODBC | Padrão em conexões que utilizam DB Library |
|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF |
| ANSI_PADDING | 16 | ON | ON | ON | OFF |
| ANSI_WARNING | 8 | ON | OFF | ON | OFF |
| ARITHABORT | 64 | ON | OFF | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF |
| QUOTED_IDENTIFIER | 256 | ON | OFF | ON | OFF |
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF |
(*) O id é utilizado no comando sp_configure. Para conferir o que cada configuração faz, leia a seção “Configurações Necessárias para indexed views”. Existem duas maneiras para mudar o valor de uma configuração:
Para confirmar o estado de cada um dos parâmetros da Tabela 1, utilize a função SessionProperty(‘nome do parâmetro’) ou o comando DBCC UserOptions.
Dessa forma, configure todos os parâmetros de acordo com a coluna ‘estado exigido para indexed views’ da Tabela 1 – se isso não for feito, o SQL Server não permitirá criar/executar a indexed view.
Criaremos uma view para totalizar a quantidade diária vendida na tabela Order Details, localizada no database NorthWind. Veja a Listagem 3.
use NorthWind go
create view vi_vendas_mes
with SchemaBinding
as
select ano = datepart(yyyy,OrderDate),
mes = datepart(mm,OrderDate),
qtde_total = sum(Quantity),
contador = count_big(*)
from dbo.Orders o
inner join
dbo.[Order Details] od
on o.OrderId = od.OrderId
group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate)
goÉ necessário observar algumas particularidades ao criar indexed views:
É necessário criar as indexed views com SchemaBinding. Para manter consistente o conteúdo da view, não é possível alterar a estrutura das tabelas que a deram origem. Para evitar esse tipo de problema, é obrigatório utilizar SchemaBinding na criação de indexed views, pois essa opção não permite alterar a estrutura da tabela sem que se elimine antes a view.
Para utilizar a cláusula GROUP BY, é obrigatório incluir a função COUNT_BIG(*). A função count_big(*) faz o mesmo que count(*), porém retorna um valor do tipo bigint (8 bytes).
Informe sempre o owner dos objetos referenciados na indexed view. Utilize select * from dbo.Orders em vez de select * from Orders, já que é possível haver tabelas com o mesmo nome mas com proprietários diferentes. Como a opção de schemabinding é obrigatória, o SQL Server precisa da especificação exata do objeto para coibir a alteração do schema.
A view criada no item 2 ainda não se porta como uma indexed view, pois o resultado do comando select não foi materializado em uma tabela. É possível confirmar essa afirmação executando o comando sp_spaceused no Query Analyzer, que retorna o número de linhas e espaço utilizados pelas tabelas (Listagem 4).
sp_SpaceUsed vi_vendas_mes
--------------------------------------------------------------------------------------
Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91
Views do not have space allocated.Observe na Listagem 5 que o processamento da view é puramente lógico, tanto que o valor de Physical Reads é zero. Anote os valores registrados em Logical Reads e Physical Reads (1672+0+4+0=1676) – utilizaremos esses valores em nossas comparações futuras.
Set statistics io ON
Select * from vi_vendas_mes
go
---------------------------------------------------------
ano mes qtde_total contador
----------- ----------- ------------- --------------------
1996 7 1462 59
1996 8 1322 69
1996 9 1124 57
.....
(23 row(s) affected)
Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Para verificar se a view pode ser indexada (materializada), ou seja, se ela foi criada dentro dos padrões e configurações necessárias a indexed views, o resultado do SELECT a seguir deverá ser igual a 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Confirmados os pré-requisitos, podemos agora criar o índice. A sintaxe possui o mesmo formato utilizado na criação de índices em tabelas convencionais:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Note que o índice cluster é obrigatório porque ele gera páginas de dados. Você só poderá criar índices não-cluster em indexed views depois de criar o índice cluster.
Agora o SELECT encontrado na view foi materializado, o que pode ser comprovado com o comando sp_spaceused no Query Analyzer (Listagem 6).
sp_SpaceUsed vi_vendas_mês
go
-----------------------------------------------------
Name Rows Reserved data index_size Unused
vi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBUma das maneiras de acessar uma indexed view (assim como uma view convencional) é fazendo referência a seu nome no comando SELECT:
select * from vi_vendas_mesCompare o volume de páginas movimentadas na Listagem 5 (1672+4=1676) com o da Listagem 7 (2+0=2). A diferença é bastante expressiva – a criação da indexed view reduziu o total de I/O necessário em 1674 páginas.
Set statistics io ON select * from vi_vendas_mes
go
---------------------------------------------------------
ano mes qtde_total contador
----------- ----------- ------------- --------------------
1996 7 1462 59
1996 9 1124 57
.....
(23 row(s) affected)
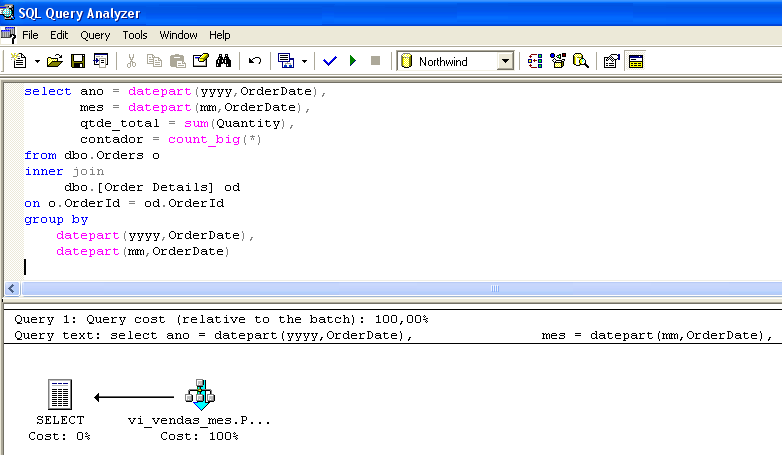
Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Vejamos outro exemplo. A Figura 1 mostra o plano de execução de uma query. Confirme que a view foi selecionada mesmo sem estar presente na linha do SELECT.
Durante a construção do plano de execução da query, o otimizador constatou que já existiam dados pré-sumariados para a query em vi_vendas_mes e optou por selecionar os dados diretamente na indexed view.
Repare que a query executada na Figura 1 é idêntica à encontrada na view vi_vendas_mes. No entanto, o acesso à view pelo otimizador independe da semelhança entre a consulta executada e a consulta da view. A seleção da indexed view pelo processador de queries leva em conta apenas o custo-benefício. Desse modo, as queries executadas não precisam ser idênticas à view (observe a Figura 3).
Entretanto, é necessário seguir algumas regras para que a indexed view seja considerada pelo otimizador de queries:
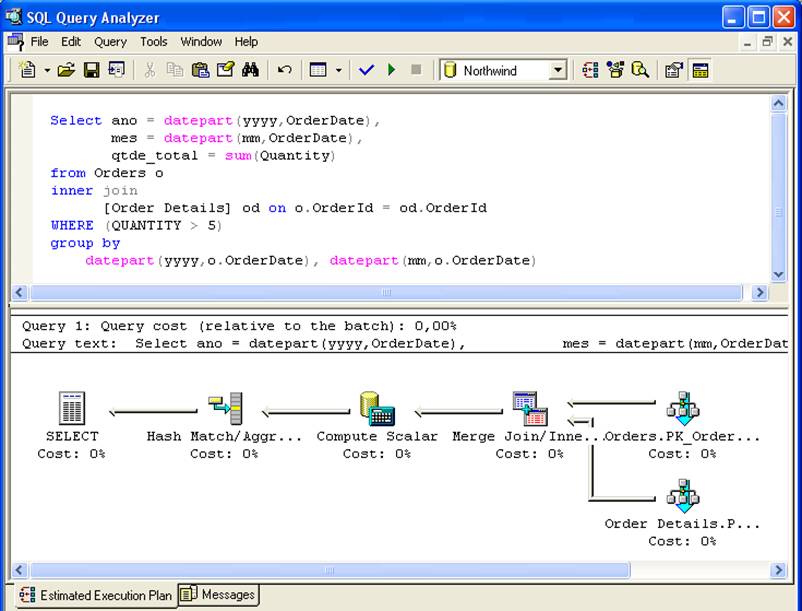
Por outro lado, se a query possuir a condição where sum(Quantity) > 5, a view vi_vendas_mes será considerada no plano de execução, pois a condição da pesquisa é um subconjunto do SELECT presente na view.
As colunas com funções de agregação na query precisam “estar contidas” na definição da view: se a view retorna a coluna qtde=sum(Quantity) e a query possui uma coluna vlr_unitario=sum(UnitPrice), a view não será considerada.
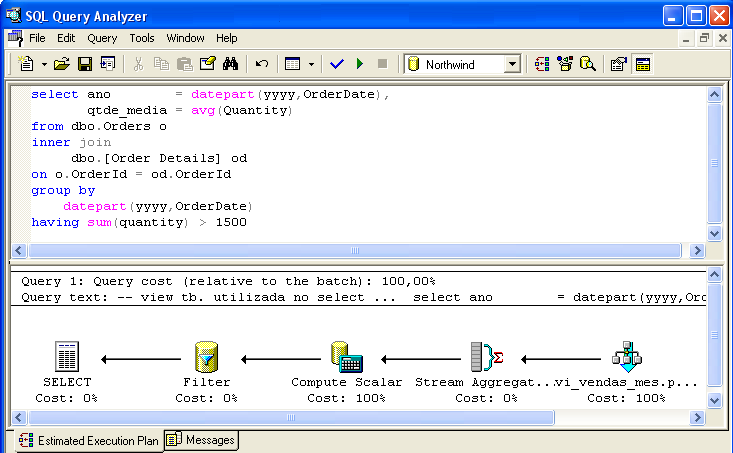
A Figura 3 mostra um comando SELECT que permite comprovar a inteligência do otimizador de comandos - o cálculo AVG(Quantity) foi substituído pela divisão entre SUM(Quantity) / Count_Big(*), representada pelo ícone Compute Scalar. O predicado where sum(Quantity) > 1500 (representado pelo ícone Filter) também é considerado.
Considerações gerais sobre a utilização de indexed views:
Define a forma como as comparações com valores nulos são efetuadas (Listagem 8).
set ANSI_NULLS ON
declare @var char(10)
set @var = null
if @var = null print 'VERDADEIRO'
else print 'FALSO'
-------------------------------------
FALSO
set ANSI_NULLS OFF
declare @var char(10)
set @var = null
if @var = null print 'VERDADEIRO'
else print 'FALSO'
--------------------------------------
VERDADEIRODetermina como devem ser armazenadas as colunas char, varchar, binary e varbinary quando seu conteúdo for menor que o tamanho definido na estrutura da tabela. O padrão do SQL Server 2000 é manter ansi_padding ativado (=ON); nessa condição valem as regras abaixo:
Quando ativado, finaliza a execução da query ao encontrar uma divisão por zero ou algum tipo de overflow.
Quando ativado, permite o uso de aspas duplas para especificar nomes de tabelas, colunas etc. – dessa forma, esses nomes poderão possuir espaços e\ou caracteres especiais.
Controla o resultado da concatenação de strings com valores nulos. Quando ativado, determina que essa junção deve retornar um valor nulo; caso contrário, retornará a própria string.
Quando ativado, determina a geração de mensagens de erro quando:
Controla como o SQL Server deve proceder ao encontrar perda de precisão numérica em operações aritméticas. Se o parâmetro estiver ativado e uma variável com precisão de duas casas decimais receber um valor com três casas decimais, a operação será abortada. Se o parâmetro estiver desativado, o valor será truncado para duas casas decimais.
Quando se trata de otimização de queries, asindexed viewssão uma boa escolha para alavancar a performance. Portanto, avalie minuciosamente as queries que lidam com sumarizações e que são executadas com certa freqüência e parta para a criação deindexed views. O resultado vale a pena!

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.