Atençăo: esse artigo tem uma palestra complementar. Clique e assista!
Atençăo: esse artigo tem um vídeo complementar. Clique e assista!
Artigo no estilo: CursoInstalaçăo de um Banco de Dados em Cluster simulado, baseado na arquitetura Oracle RAC.
Este artigo é o segundo de uma série sobre RAC.
Para que serve?
Para disponibilizar o acesso a um único Banco de Dados a partir de várias Instâncias, acomodadas em computadores diferentes.
Em que situaçăo o tema é útil?
Em casos onde a disponibilidade e o poder de processamento săo características fundamentais do ambiente.
Nesta segunda parte, iremos finalizar a instalaçăo de um banco de dados em Cluster utilizando o Oracle RAC. Na ediçăo anterior, terminamos de instalar e configurar o Linux CentOS 4.7, e a máquina virtual foi desligada para iniciar a criaçăo dos Shared Disks (Discos Compartilhados).
Os Shared Disks săo necessários porque, como o Cluster trata de vários computadores acessando o mesmo banco de dados, este precisa estar em um local que permita o acesso contínuo a todos os nós.
Além do banco de dados – que compreende os data files, temporary files, redo logs, control files, entre outros – dois componentes muito importantes do Oracle RAC necessitam de armazenamento em Shared Disks. Estes dois componentes săo o OCR, ou Oracle Cluster Registry e o Voting Disk, que serăo melhor explicados mais adiante.
O Oracle RAC suporta vários tipos de configuraçăo para os Shared Disks. Podem ser utilizados Raw Devices, NFS (Nota DevMan 1), LVM, OCFS (Nota DevMan 2), OCFS2, ASM, ou mesmo filesystems proprietários de Cluster, desde que seja homologado pela Oracle para uso com Oracle RAC.
Nota DevMan 1. NFS
NFS (acrônimo para Network File System) é um sistema de arquivos distribuídos desenvolvido inicialmente pela Sun Microsystems, Inc., a fim de compartilhar arquivos e diretórios entre computadores conectados em rede, formando assim um diretório virtual. O protocolo Network File System é especificado nas seguintes RFCs: RFC 1094, RFC 1813 e RFC 3530 (que tornou obsoleta a RFC 3010).
Nota DevMan 2. OCFS
OCFS significa Oracle Cluster File System. É um sistema de arquivos compartilhado desenvolvido pela Oracle Corporation e lançado sob a licença GNU General Public License.
A primeira versăo do OCFS foi desenvolvida com o principal foco de acomodar arquivos de bancos de dados Oracle para bancos em Cluster. Por este motivo năo era um sistema de arquivos compatível com POSIX. Com a versăo 2, as funcionalidades POSIX foram incluídas.
OCFS2 (versăo 2) foi integrada na versăo 2.6.16 do kernel do Linux. Inicialmente, foi marcada como código experimental. Esta restriçăo foi removida na versăo 2.6.19. Com a versăo 2.6.29 mais funcionalidades foram incluídas no ocfs2, especialmente controle de acesso e cotas.
OCFS2 usa um gerenciador distribuído de arquivos que lembra o OpenVMS DLM, mas é muito mais simples.
Nesta série de artigos, iremos utilizar principalmente o ASM, ou Automatic Storage Management, que é um sistema de arquivos de uso específico para bancos de dados desenvolvido pela própria Oracle.
O ASM será preferido por sua ampla adoçăo atual no mercado, sendo que a Oracle está visivelmente favorecendo seu desenvolvimento desde o início em detrimento do OCFS e OCFS2.
No nosso ambiente de testes, para evitar que o leitor precise adquirir um Storage para utilizar os Shared Disks, iremos emulá-los utilizando os arquivos de discos do próprio VMware.
Criaçăo dos Shared Disks
Iremos a seguir criar cinco discos virtuais: um para o OCR (Nota DevMan 3), um para o Voting Disk (Nota DevMan 4), e tręs para o ASM.
Nota DevMan 3. OCR
O OCR é utilizado no Oracle RAC para armazenar configuraçőes do Cluster e as informaçőes de status de cada recurso que é administrado por ele. Por exemplo: os nomes dos nós, os endereços IPs e VIPs, qual a localizaçăo dos voting disks, nomes dos bancos de dados e instâncias, nomes dos listeners e etc.
O OCR é um arquivo de formato binário, mantido pelo daemon CRS, que deve ser armazenado em uma partiçăo – um Raw Device – ou um arquivo em um Cluster File System.
Nota DevMan 4. Voting Disk
Um Voting Disk (Disco de Voto) é um disco compartilhado, uma partiçăo ou um arquivo usado para determinar a disponibilidade de um nó do Cluster. Todas as instâncias do RAC gravam no Voting Disk regularmente para indicar que estăo ativas. Isso é exigido, pois no caso de uma das instâncias năo poder se comunicar com a outra, as informaçőes de quais instâncias estăo ativas ainda estăo disponíveis para o Cluster em um local compartilhado.
O Voting Disk pode ser armazenado, por exemplo, em um Raw Device ou um Cluster File System. Eles podem e devem ser espalhados para evitar-se um ponto único de falhas no Cluster.
Para criar o primeiro disco, o do OCR, siga os passos:
1. Desligue a máquina virtual;
2. No VMware, clique em “Edit Virtual Machine Settings”, e depois, em “Add”;
3. Em “Add Hardware Wizard”, clique em “Next”;
4. Em “Hardware Type”, selecione “Hard Disk”;
5. Em “Select a Disk”, selecione “Create a Virtual Disk”;
6. Em “Select a Disk Type”, selecione “SCSI”;
7. Em “Specify Disk Capacity”, selecione “10 GB” em “Disk Size”. Deselecione “Allocate all disk space now”, e selecione “Split into 2 GB files”;
8. Em Specify Disk File, coloque “C:\Virtual Machines\Shared\ocr.vmdk”. Năo clique em Finish ainda, e clique em Advanced;
9. Em “Advanced”, em “Virtual device node”, selecione “SCSI 1:1”. Selecione também “Independent”, e depois “Persistent”;
10. Agora sim, clique em “Finish”.
Para criar o segundo disco, o do Voting Disk, siga os passos 1 a 7 anteriores e logo após:
8. Em Specify Disk File, coloque “C:\Virtual Machines\Shared\votingdisk.vmdk”. Năo clique em Finish ainda, e clique em Advanced;
9. Em “Advanced”, em “Virtual device node”, selecione “SCSI 1:2”. Selecione também “Independent”, e depois “Persistent”;
10. Agora sim, clique em “Finish”.
Para criar o terceiro disco, o primeiro do ASM, siga os passos 1 a 7 anteriores e logo após:
8. Em Specify Disk File, coloque “C:\Virtual Machines\Shared\asm1.vmdk”. Năo clique em Finish ainda, e clique em Advanced;
9. Em “Advanced”, em “Virtual device node”, selecione “SCSI 1:3”. Selecione também “Independent”, e depois “Persistent”;
10. Agora sim, clique em “Finish”.
Para criar o quarto disco, que será o segundo do ASM, siga os passos 1 a 7 anteriores e logo após:
8. Em Specify Disk File, coloque “C:\Virtual Machines\Shared\asm2.vmdk”. Năo clique em Finish ainda, e clique em Advanced;
9. Em “Advanced”, em “Virtual device node”, selecione “SCSI 1:4”. Selecione também “Independent”, e depois “Persistent”;
10. Agora sim, clique em “Finish”.
Da mesma forma, para criar o quinto disco, que será o terceiro do ASM, siga os passos 1 a 7 anteriores e logo após:
8. Em Specify Disk File, coloque “C:\Virtual Machines\Shared\asm3.vmdk”. Năo clique em Finish ainda, e clique em Advanced;
9. Em “Advanced”, em “Virtual device node”, selecione “SCSI 1:5”. Selecione também “Independent”, e depois “Persistent”;
10. Agora sim, clique em “Finish”.
Configuraçăo dos Shared Disks
Depois de criar os discos na máquina virtual, iremos editar o seu arquivo de configuraçăo para a simulaçăo dos Shared Disks.
Verifique se as linhas da Listagem 1 estăo no arquivo C:\Virtual Machines\RAC1\Red Hat Enterprise Linux 4.vmx. Olhe linha a linha. Se a linha já existir, deixe-a intacta. Se năo existir, adicione-a.
Listagem 1. Configuraçăo do arquivo C:\Virtual Machines\RAC1\Red Hat Enterprise Linux 4.vmx.
disk.locking = "FALSE"
diskLib.dataCacheMaxSize = "0"
diskLib.dataCacheMaxReadAheadSize = "0"
diskLib.dataCacheMinReadAheadSize = "0"
diskLib.dataCachePageSize = "4096"
diskLib.maxUnsyncedWrites = "0"
scsi1.sharedBus = "VIRTUAL"
tools.syncTime.period = "1"
timeTracker.periodicStats="TRUE"
timeTracker.statsIntercal="10"
reslck.timeout = "300"
scsi1:1.deviceType = "plainDisk"
scsi1:1.redo = ""
scsi1:2.deviceType = "plainDisk"
scsi1:2.redo = ""
scsi1:3.deviceType = "plainDisk"
scsi1:3.redo = ""
scsi1:4.deviceType = "plainDisk"
scsi1:4.redo = ""
scsi1:5.deviceType = "plainDisk"
scsi1:5.redo = ""
Particionamento dos Shared Disks
Agora precisamos configurar estes discos novos dentro do Linux. Para isto, inicie o RAC1. Durante a inicializaçăo do CentOS, quando o Kudzu (um serviço do CentOS que verifica se ocorreram mudanças no hardware) avisar que um novo hardware foi encontrado, selecione a opçăo “Configure”.
Após a inicializaçăo, execute logon com o usuário root, e execute os comandos da Listagem 2. Estes comandos, com o utilitário fdisk, irăo criar uma partiçăo (Nota DevMan 5) em cada disco.
Nota DevMan 5. Partiçőes
Uma partiçăo é uma divisăo de um disco rígido (SCSI ou ATA). Cada partiçăo pode conter um sistema de arquivos diferente. Conseqüentemente, vários sistemas operacionais podem ser instalados na mesma unidade de disco.
Listagem 2. Comandos a serem executados como root.
fdisk /dev/sdb
1. - Aperte a tecla “n”, para criar uma nova partiçăo;
2. - Em seguida, aperte a tecla “p”, para que a nova partiçăo seja primária;
3. - Em seguida, aperte a tecla “1”, pois será a primeira partiçăo do disco;
4. - Em seguida, aperte “Enter”, para aceitar as opçőes padrăo de tamanho, usando todo o disco;
5. - Em seguida, aperte “w”, para gravar as alteraçőes.
fdisk /dev/sdc -- siga os passos 1 a 5
fdisk /dev/sdd -- siga os passos 1 a 5
fdisk /dev/sde -- siga os passos 1 a 5
fdisk /dev/sdf -- siga os passos 1 a 5
Em seguida, para que cada partiçăo seja relacionada a um raw device, edite o arquivo /etc/sysconfig/rawdevices e adicione as linhas da Listagem 3.
Listagem 3. Configuraçăo do arquivo /etc/sysconfig/rawdevices.
/dev/raw/raw1 /dev/sdb1
/dev/raw/raw2 /dev/sdc1
/dev/raw/raw3 /dev/sdd1
/dev/raw/raw4 /dev/sde1
/dev/raw/raw5 /dev/sdf1
Depois, execute os comando da Listagem 4 como root.
Listagem 4. Comandos a serem executados como root.
service rawdevices restart
ln -s /dev/raw/raw1 /u01/oradata/ocr
ln -s /dev/raw/raw2 /u01/oradata/votingdisk
ln -s /dev/raw/raw3 /u01/oradata/asm1
ln -s /dev/raw/raw4 /u01/oradata/asm2
ln -s /dev/raw/raw5 /u01/oradata/asm3
chown oracle:oinstall /dev/raw/raw1
chown oracle:oinstall /dev/raw/raw2
chown oracle:oinstall /dev/raw/raw3
chown oracle:oinstall /dev/raw/raw4
chown oracle:oinstall /dev/raw/raw5
chmod 600 /dev/raw/raw1
chmod 600 /dev/raw/raw2
chmod 600 /dev/raw/raw3
chmod 600 /dev/raw/raw4
chmod 600 /dev/raw/raw5
Pronto, o primeiro nó do Cluster está pronto para receber o Clusterware.
Clonando a Máquina Virtual
Para năo termos que instalar o outro nó desde o início, iremos simplesmente clonar o primeiro nó, que já está configurado da forma correta.
Para fazer a clonagem:
- Desligue o primeiro nó. A partir de agora, iremos nos referir a ele pelo nome da máquina, ou seja, RAC1;
- Copie a pasta “C:\Virtual Machines\RAC1” para “C:\Virtual Machines\RAC2”;
- No arquivo “C:\Virtual Machines\ RAC2\Red Hat Enterprise Linux 4.vmx”, procure pela linha que contém “displayName = "RAC1"” e mude para ”DisplayName = "RAC2"”.
- No Vmware, importe o RAC2 (File ? Open - Browse)?
- Inicie o RAC2 (ainda năo inicie o RAC1)?
- Ao iniciar a VM, escolha a opçăo “Create”
- No Kudzu, escolha “Keep Configuration” e depois “Ignore”
Agora, com o RAC2 ligado, precisamos ajustar suas configuraçőes de rede, que neste momento estăo iguais ao do RAC1, de onde foi clonado. Para isso:
- Execute logonj no RAC2, como root, no ambiente gráfico;
- Clique em “Applications”, depois em “System Settings”, e escolha o menu “Network”;
- Clique em “DNS”. Em “Hostname”, coloque “rac2.localdomain”;
- Clique na aba “Devices” e selecione “eth0”. Em “Edit”, clique em “Hardware Device”, depois em “Probe”, e “OK”. Este passo foi necessário para alterar-se o MAC Address da placa de rede virtual, que deve ser trocado quando a máquina virtual é clonada;
- Na aba “Devices”, selecione “eth0”, clique em “Edit”, e “General”. Em “Address”, mude o final do endereço IP de 101 para 102;
- Clique na aba “Devices” e selecione “eth1”. Em “Edit”, clique em “Hardware Device”, depois em “Probe”, e “OK”. Este passo foi necessário para alterar-se o MAC Address da placa de rede virtual, que deve ser trocado quando a máquina virtual é clonada.
- Na aba “Devices”, selecione “eth1”, clique em “Edit”, e “General”. Em “Address”, mude o final do endereço IP de 101 para 102;
- Clique em “File”, e em “Save”. Clique em “OK”;
- Em “Devices”, selecione “eth0”, e clique em “Activate”;
- Em “Devices”, selecione “eth1”, e clique em “Activate”;
- Como usuário oracle, edite o arquivo /home/oracle/.bash_profile, e troque ORCL1 por ORCL2. Este será o SID do Oracle no RAC2.
Pronto, o RAC 2 está com o nome da máquina e endereços IPs corretos. Neste momento, vocę pode ligar o RAC1 novamente, pois năo haverá conflitos de IP.
Instalaçăo do Oracle Clusterware
Agora iremos instalar o software que irá cuidar da administraçăo do Cluster e todos os programas que funcionarăo neste ambiente, incluindo o próprio Oracle (ler Nota DevMan 6).
Oracle Clusterware é um software de Cluster portável que agrupa servidores individuais para que cooperem como um único sistema. Componente fundamental do Oracle RAC, o Oracle Clusterware pode operar de forma independente e ajuda a assegurar a proteçăo de um aplicativo, seja da Oracle ou de terceiros.
O Oracle Clusterware possibilita a alta disponibilidade, um componente essencial da continuidade dos negócios, para aplicativos e bancos de dados gerenciados no ambiente de Cluster – incluindo bancos de dados Oracle de uma única instância, Oracle Application Server, componentes do Oracle Enterprise Manager, bancos de dados de outros fornecedores e outros aplicativos.
A instalaçăo do Oracle Clusterware só precisa ser feita em um dos nós, e automaticamente será replicada para todos os outros nós existentes no Cluster. Em um certo momento da instalaçăo, serăo solicitados que sejam executados scripts como o usuário root em todos os nós, mas a maior parte da instalaçăo é replicada automaticamente por todo o Cluster.
Para instalar o Oracle Clusterware, teremos que copiar os Softwares baixados anteriormente da máquina Host (Windows) para a máquina Virtual (Linux).
Este tipo de cópia pode ser feita com um utilitário como o WinSCP. O WinSCP pode ser baixado em http://winscp.net.
· Copie o arquivo 10201_clusterware_linux32.zip para o RAC1;
· Copie o arquivo 10201_database_linux32.zip para o RAC1;
· Execute logon no RAC1 com o usuário oracle, e descompacte os arquivos (Listagem 5).
Listagem 5. Comandos a serem executados como o usuário oracle.
cd /home/oracle
unzip 10201_clusterware_linux32.zip
unzip 10201_database_linux32.zip
Verifique se há uma linha no arquivo /etc/hosts que começa com 127.0.0.1. Esta linha deve estar como na Listagem 6. Se năo estiver, edite-a para que fique correta:
Listagem 6. Configuraçăo do arquivo /etc/hosts.
127.0.0.1 localhost· Execute logon no RAC2, com o usuário root.
· Verifique se há uma linha no arquivo /etc/hosts que começa com 127.0.0.1. Esta linha deve estar como na Listagem 6. Se năo estiver, edite-a para que fique correta:
Agora iremos iniciar o assistente para instalaçăo do Oracle Clusterware. No RAC1, abra um terminal e execute os comandos da Listagem 7.
Listagem 7. Comandos a serem executados como o usuário oracle.
export $ORACLE_HOME=$CRS_HOME
/home/oracle/clusterware/runInstaller.sh
O último comando da Listagem 7 irá lançar o instalador do Clusterware. Depois de iniciado o instalador do Clusterware, siga este passos:
- Clique em “Next”;
- Na tela “Specify Cluster Configuration”, vocę deve verificar se os nomes dos nós do Cluster estăo corretos. Nesta tela, săo informados os 3 nomes (sendo que cada um corresponde a um endereço IP, configurados anteriormente) de cada nó: um público (Public Node Name), um privado (Private Node Name), e um virtual (Virtual Node Name), conforme mostrado na Figura 1. Em seguida, clique em Next;
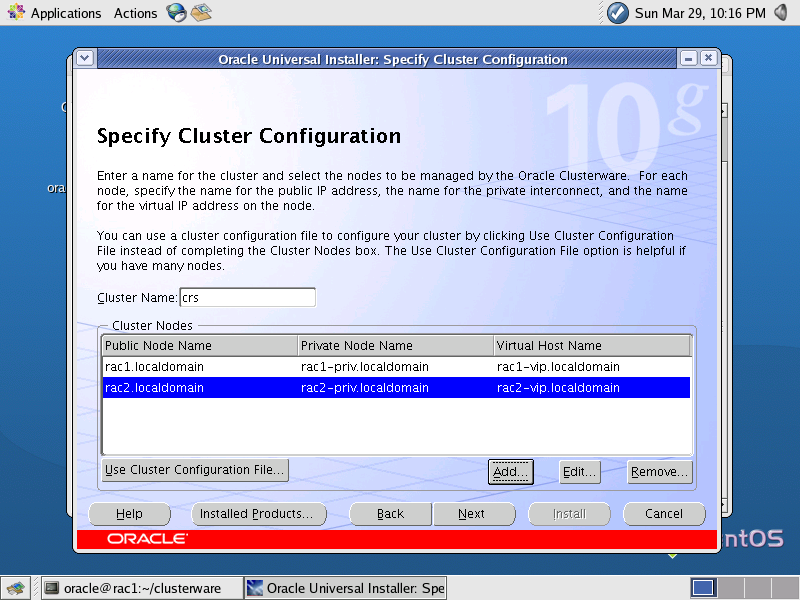
Figura 1. Tela “Specify Cluster Configuration”.
- Na tela “Specify Network Interface Usage”, devem ser especificadas as redes públicas e privadas dos nós. Na linha que mostra a “Interface Name” como “eth0”, vocę deve colocar no campo “Subnet” o endereço “192.168.202.0”. Da mesma forma, na linha que mostra a “Interface Name” a “eth1”, vocę deve colocar no campo “Subnet” o enredeço “192.168.203.0” (Figura 2).
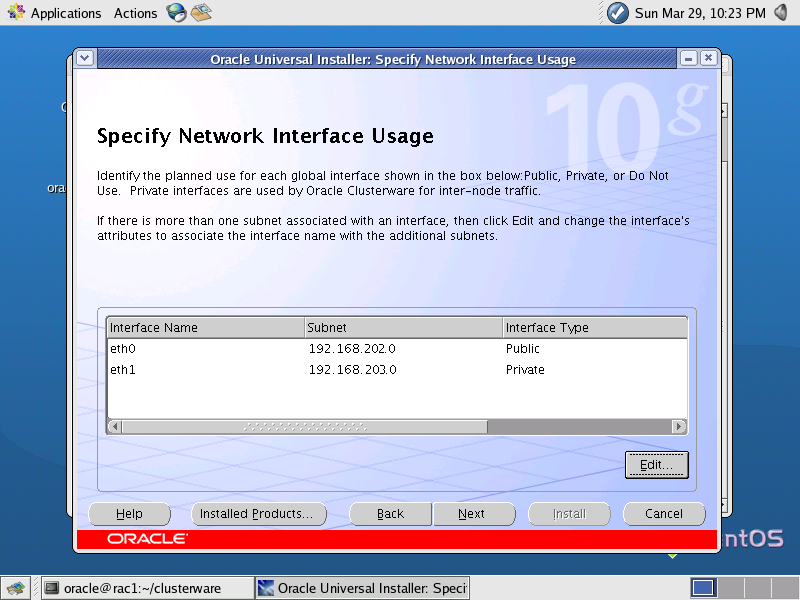
Figura 2. Tela “Specify Network Usage Configuration”.
- Na tela “Specify Oracle Cluster Registry (OCR) Location”, deve ser especificado o link simbólico para o raw device que configuramos anteriormente para o OCR, o “/u01/oradata/ocr”, como está na Figura 3. Em seguida, clique em Next;
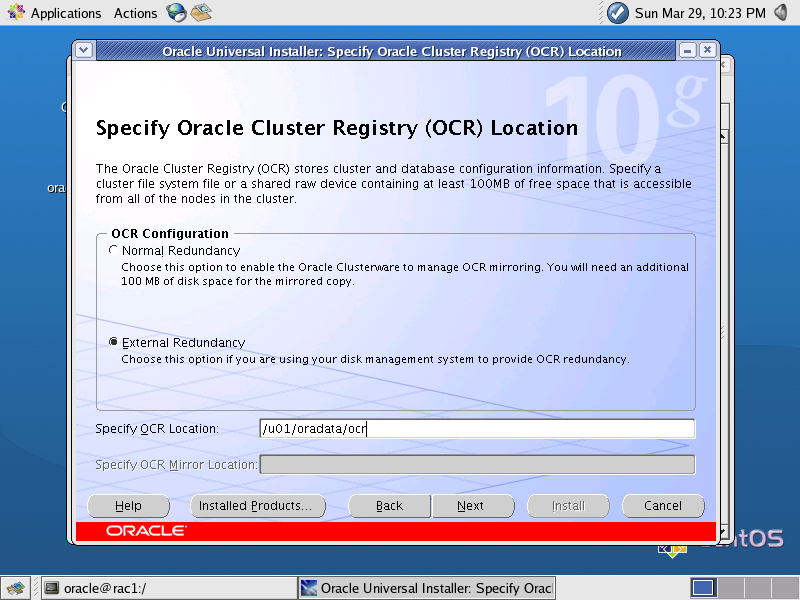
Figura 3. Tela “Specify Oracle Cluster Registry (OCR) Location”.
- Na tela “Specify Voting Disk Location”, deve ser especificado o link simbólico para o raw device que configuramos anteriormente para o Voting Disk, o “/u01/oradata/votingdisk”, como está na Figura 4. Em seguida, clique em Next;
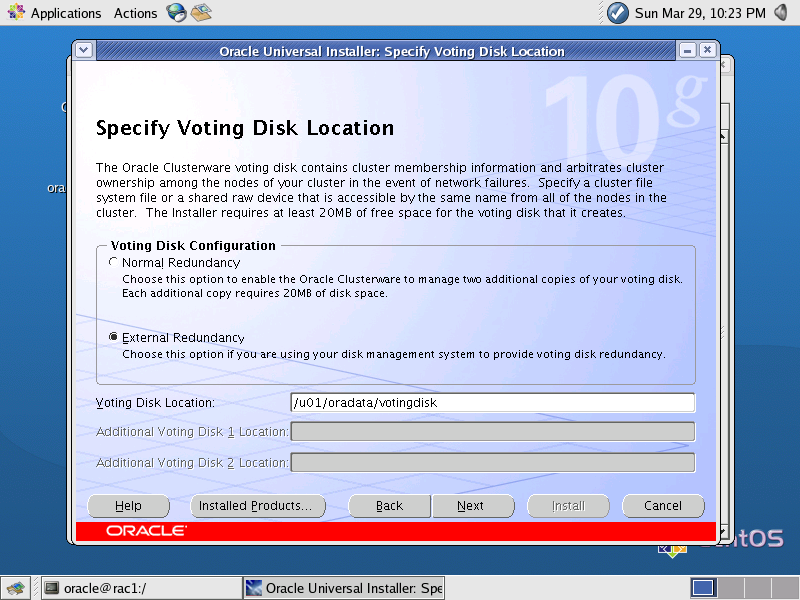
Figura 4. Tela “Specify Voting Disk Location”.
- Após executados estes passos, a instalaçăo do Clusterware irá prosseguir nos dois nós, e o instalador irá executar uma verificaçăo ao término da instalaçăo. Em alguns ambientes, o VIPCA năo é configurado automaticamente, e isto será acusado nesta última verificaçăo, como na Figura 5. Mas isto năo é um problema: quando o último check acusar problemas, como root, execute o VIPCA (Virtual IP Configuration Assistant).
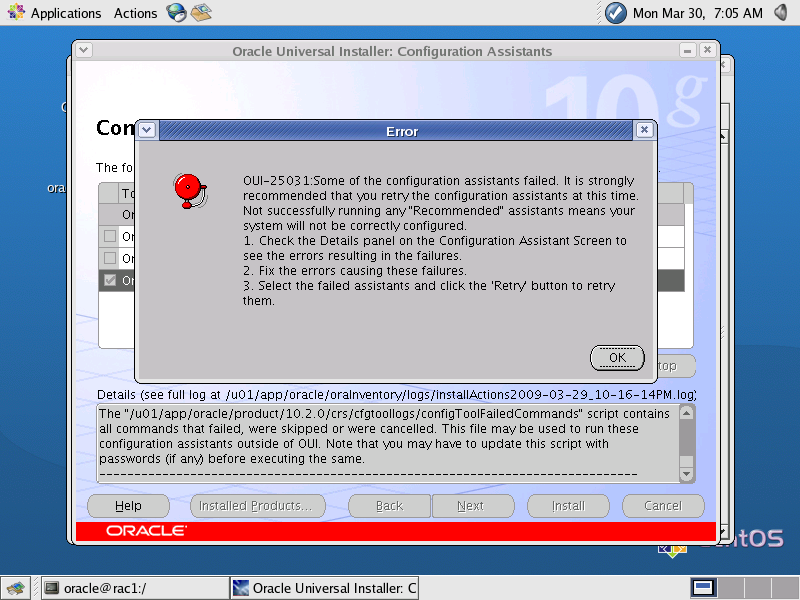
Figura 5. Erro na verificaçăo final do Clusterware.
- Para executar o VIPCA, abra um terminal, e como root, execute o comando da Listagem 8.
Listagem 8. Comandos a serem executados como o usuário root.
/u01/app/oracle/product/10.2.0/crs/bin/vipca- No VIPCA, devem ser configurados os nomes e IPs dos VIPs (192.168.202.111 e 192.168.202.112), como demonstrado na Figura 6.
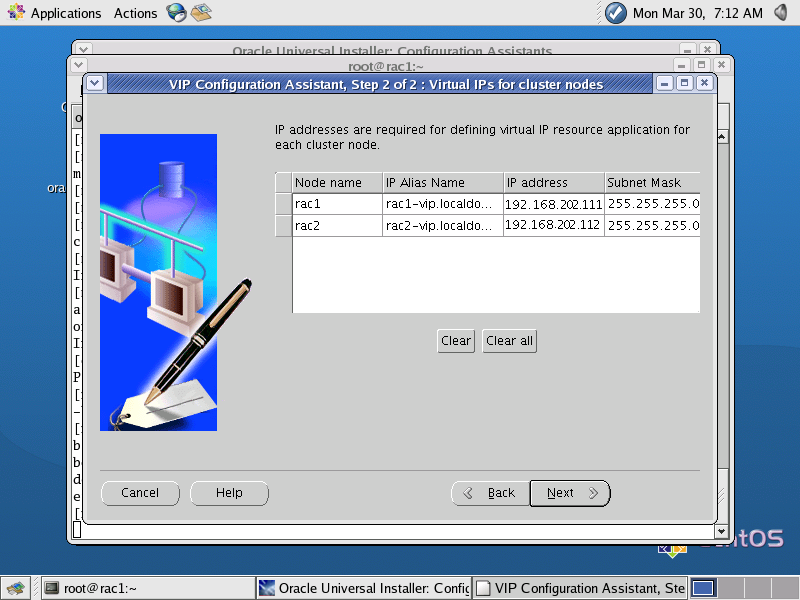
Figura 6. Configuraçăo do VIPCA.
Após executar o VIPCA, volte para a tela de instalaçăo do Clusterware, clique em “Retry” na verificaçăo, em seguida, em “Finish”. Pronto, o Clusterware foi instalado com sucesso e está pronto para receber o Oracle.
Instalaçăo do Oracle
Agora o Cluster está pronto para receber o software que irá gerenciar o banco de dados. A instalaçăo do Oracle em ambiente RAC só precisa ser feita em um dos nós, e automaticamente será replicada para todos os outros nós existentes no Cluster.
Para instalar o Software Oracle, execute logon no RAC1, e execute o comando da Listagem 9.
Listagem 9. Comandos a serem executados como o usuário oracle.
/home/oracle/database/runInstaller.shSerá iniciado entăo o Oracle Universal Installer. Na tela inicial do OWI, clique em Next. Selecione a opçăo "Enterprise Edition", e depois clique em "Next";
- Aceite as opçőes para o ORACLE_HOME, clicando em “Next”;
- Selecione a opçăo "Cluster Installation", e verifique se os dois nós do Cluster estăo selecionados. Depois, clique em “Next”;
- Aguarde a verificaçăo dos pré-requisitos. Tudo deve ocorrer bem nesta verificaçăo se todos os passos anteriores forem cumpridos. Depois, clique em “Next”. Se houver algum “warning”, provavelmente será pelos pré-requisitos de memória, mas isso năo será problema neste ambiente. Pode clicar em “Yes”, se este tipo de alerta aparecer;
- Em “Select Configuration Option”, escolha “Configure Automatic Storage Management (ASM)”, escolha uma senha para administrar o ASM (Nota DevMan 7), e clique em Next. Esta opçăo fará com que, além de instalar o Software, o ASM já seja configurado.
As instâncias ASM irăo rodar nos dois nós, sobre os discos virtuais criados e gerenciar os arquivos do banco de dados. Também será necessário criarmos um Disk Group, que é a unidade básica de gerenciamento de discos no ASM, onde poderemos colocar os dados.
Nota DevMan 7. ASM
Automatic Storage Management (ASM) é uma funcionalidade provida pelo Oracle a partir da versăo 10g revisăo 1. ASM procura simplificar o gerenciamento de arquivos de bancos de dados. Para isso, ele oferece ferramentas para gerenciar sistemas de arquivos e volumes diretamente dentro do kernel do banco de dados, permitindo que administradores de bancos de dados (DBAs) controlem volumes e discos com familiares comandos SQL no Oracle. Desta forma o DBA năo precisa de conhecimentos extras em sistemas de arquivos específicos ou gerenciadores de volume, que geralmente operam no nível do sistema operacional.
Com ASM:
· IOs podem tomar vantagem de striping de dados e mirroring via software.
· DBAs podem automatizar redistribuiçőes sem paradas, com a adiçăo ou remoçăo de discos.
· O sistema mantém cópias redundantes e oferece funcionalidades de RAID de terceiros.
· Oracle suporta tecnologias de multipathing IO de terceiros (failover ou load balancing para acessos a SAN, etc.)
· A necessidade de hot spares diminui.
- Em “Configure Automatic Storage Management”, como em “Disk Group Name”, coloque “DATA”. Este será o nome do Disk Group que usaremos para o Banco de Dados. Selecione o nível de “Redundancy” como “External”, que é nenhuma redundância, o que é apropriado para nosso teste, mas năo para um ambiente produtivo. No quadro “Candidate Disks”, verifique se os tręs raw devices que criamos anteriormente estăo selecionados (/dev/raw/raw3, /dev/raw/raw4 e /dev/raw/raw5).
- Clique em Install, e aguarde a finalizaçăo da instalaçăo e configuraçăo do ASM.
- Ao término da instalaçăo, será solicitado que um script seja executa como root. Execute conforme esta tela lhe mostrar, e depois prossiga.
Criaçăo do banco de dados
Iremos agora criar o banco de dados. Esta operaçăo, na versăo 10g, é bem mais tranquila, pois pode ser feita com o assistente DBCA, ou Database Configuration Assistant.
Esta operaçăo só precisa ser feita em um dos nós do cluster, e as instâncias serăo criadas automaticamente em todos os nós. Neste artigo iremos executar esta configuraçăo a partir do RAC1.
Para criar o banco de dados:
· Verifique se o RAC1 e RAC2 estăo iniciados;
· Execute logon no RAC1 com o usuário oracle, e inicie o “Database Configuration Assistant”, digitando F2, e em seguida, “dbca”;
· Em "Welcome", selecione a opçăo "Oracle Real Application Clusters database", e depois clique em "Next";
· Selecione "Create a Database", e depois clique em "Next";
· Selecione os dois nós do RAC, e depois clique em “Next”;
· Selecione "Custom Database", e depois clique em "Next";
· Em “Global Database Names”, coloque “ORCL”. Em SID, também coloque “ORCL”. Este será o nome do Banco de Dados. Depois, clique em “Next”;
· Aceite as opçőes de gerenciamento, e clique em “Next”;
· Selecione senhas para as contas do Banco de Dados. Depois, clique em “Next”;
· Selecione a opçăo “Automatic Storage Management (ASM)", e depois clique em "Next";
· Selecione “DATA” como Disk Group, e depois clique em “Next”;
· Aceite a opçăo Use Oracle-Managed Files", e depois clique em “Next”;
· Selecione a opçăo "Specify Flash Recovery Area" e "Enable Archiving”. Coloque "+DATA" como a “Flash Recovery Area”, e depois clique em "Next";
· Aceite as configuraçőes padrăo de “Database Services”, clicando em “Next”;
· Em “Memory Management”, ”Selecione a opçăo "Custom", e depois clique em “Next”;
· Aceite as opçőes de “Storage Settings”, clicando em “Next”;
· Aceite as opçőes de “Database Creation”, clicando em “Next”;
· Aceite as informaçőes do “Summary Information”, clicando em “Next”;
Espere enquanto o DBCA finaliza a criaçăo do banco de dados. Quando a instalaçăo terminar, pode clicar em “Finish”. Pronto, seu banco de dados em Cluster está rodando !
Conclusőes
Neste artigo finalizamos a instalaçăo de um banco de dados em Cluster utilizando Oracle RAC, rodando sobre máquinas virtuais em VMware Server, e utilizando o Linux CentOS.
No próximo artigo, iremos abordar as tarefas de administraçăo do Oracle RAC, e ver como elas diferem de uma implementaçăo Single Instance do Oracle.
Veremos como funciona o Backup e Restore, os Archived Redo Logs, as manutençőes no ASM, Backup e Restore do OCR e Voting Disk, como adicionar e remover nós, e executar Rolling Upgrades, que săo as aplicaçőes de patch sem indisponiblidade.
Abraços e até a próxima!
Oracle On-Line Documentation:
http://tahiti.oracle.com



