



eterminado lugar pode ser considerado para muitos uma arte, isso porque sempre existem vários caminhos que levam ao mesmo destino. Executar uma tarefa da forma mais eficiente possível requer que o caminho percorrido seja o melhor dentre as centenas de variáveis que podem influenciar na escolha do melhor percurso.
No SQL Server o responsável por calcular a maneira mais eficiente de acesso aos dados é chamado de Query Processor, ele é dividido em duas partes, o Query Optimizer e o Query Execution Engine. Veremos neste artigo como o Query Optimizer funciona e quais os passos necessários para execução de um comando T-SQL.
Entender como funciona e como interpretar o trabalho do Query Optimizer é uma das melhores maneiras de aprimorar seus conhecimentos em SQL Server. Esse conhecimento será de grande valor quando você precisar fazer algum trabalho de tunning em banco de dados.
Para melhor entendimento dos exemplos deste artigo criaremos uma tabela, com alguns dados e uma visão, que servirão como base para os testes que serão apresentados. A Listagem 1 contém o script para criação destes objetos.
O Script cria a tabela Funcionarios com algumas informações (ID, Nome, Salário, Telefone e Cidade) e, em seguida, são inseridos alguns registros. Logo após, uma view (vw_Funcionarios) é criada. A grosso modo, podemos dizer que Views são tabelas virtuais definidas por uma consulta T-SQL. A nossa view, criada na Listagem 1, retorna o nome e o salário de todos os funcionários que ganham mais de R$ 900,00.
Listagem 1. Script para criação dos objetos de teste
CREATE TABLE Funcionarios(ID Int IDENTITY(1,1) PRIMARY KEY,
Nome VarChar(30),
Salario Numeric(18,2),
Telefone VarChar(15),
Cidade VarChar(80));
INSERT INTO Funcionarios(Nome, Salario, Telefone, Cidade)
VALUES('José', 850.30, '11-55960015', 'São Paulo');
INSERT INTO Funcionarios(Nome, Salario, Telefone, Cidade)
VALUES('Antonio', 950, '11-81115544', 'São Paulo');
INSERT INTO Funcionarios(Nome, Salario, Telefone, Cidade)
VALUES('João', 1200, '11-44123321', 'São Paulo');
CREATE VIEW vw_Funcionarios
AS
SELECT Nome, Salario FROM Funcionarios
WHERE Salario > 900Quando um comando T-SQL é executado no SQL Server, o Query Processor entra em ação para gerar um plano de execução. Este plano dirá qual é a melhor maneira de acessar os dados gastando menos recursos e com o desempenho mais eficiente possível.
Podemos observar na Figura 1 a ação do Query Optimizer (em vermelho) e uma série de passos para compilar e executar um comando T-SQL. Vamos analisar melhor este comportamento.
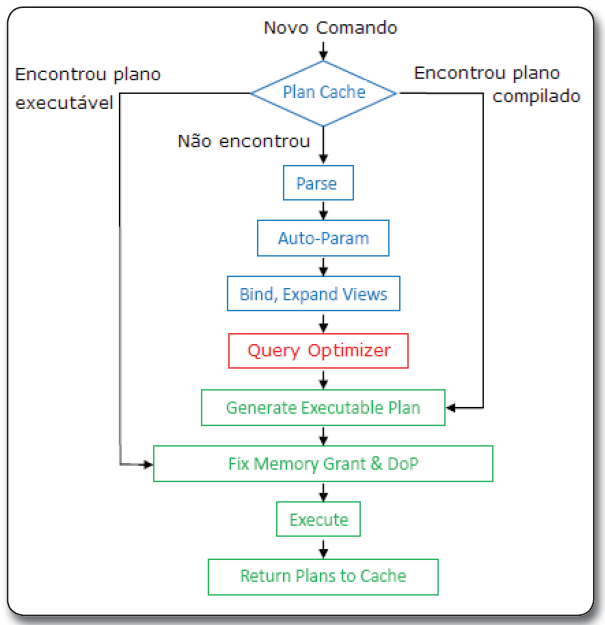
Figura 1. Fluxograma de passos necessários para gerar um plano de execução
Supondo que um SELECT simples, por exemplo, SELECT * FROM Funcionarios, seja enviado ao servidor, a primeira tarefa que o Query Processor fará com o comando é verificar se o mesmo está no Cache Plan (mais informações sobre o Cache Plan no final do artigo). Caso ele não esteja em cache, o Query Processor enviará o comando para os processos de Parse e Bind.
O Parse/Bind executa um processo conhecido como Algebrizer. Durante este processo o SQL tenta encontrar possíveis erros de escrita na sintaxe e lógica do comando. Por exemplo, o comando “select id from tab1 group by nome” gera uma exceção, pois a coluna id não pertence ao group by e não está utilizando uma função de agregação (SUM, COUNT, ...). O Algebrizer também expande as definições do comando, isso significa que ele troca “select *” por “select col1, col2, col3...”, ou “select col1 from View” pelo nome das tabelas envolvidas na view.
Sempre que uma view é referenciada em uma consulta, o SQL Server acessa as tabelas que contém os dados. Na Figura 2, por exemplo, podemos visualizar que o SQL acessa a tabela Funcionarios para ler os valores das colunas Nome e Salario.

Figura 2. Ilustração de uma View acessando uma tabela.
Outro passo será resolver os nomes e tipos de objetos envolvidos na consulta. Pode acontecer de haver um sinônimo para uma determinada tabela que está em outro servidor. Quando isso acontece, o SQL precisa identificar que este sinônimo faz referência a um objeto que está em outro banco de dados, e este banco pode estar até mesmo ligado a outro servidor utilizando um Linked Server.
Após estas análises o Parse/Bind retorna um binário chamado Query Processor Tree, que é uma representação lógica dos passos necessários para a execução do comando SQL. O Query Processor Tree é enviado para o próximo passo da execução da consulta, que é a análise do Query Optimizer.
É importante destacar que nem sempre um comando é enviado para a análise do Query Optimizer. Por exemplo, alguns comandos DDL, tais como o CREATE Table, que são de definição das estruturas dos dados, não têm necessidade de uma análise do Query Optimizer, pois só há uma forma de o SQL executar esta operação.
...
Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






