Replicação é uma feature importantíssima nos SGBD’s atuais - consiste em copiar, distribuir e manter a sincronia entre dados, estes normalmente situados em servidores distintos.
O modelo desenvolvido pela Microsoft para o SQL Server, que desde a versão 6.0 agregou replicação de dados em seu engine, será o enfoque nesta edição.
No mundo corporativo, a replicação de dados está nitidamente ligada a ambientes distribuídos, onde o acesso a dados básicos (descrição de um produto numa loja, por exemplo) é feito no próprio local da consulta. Acessando dados localmente, reduzimos a possibilidade de conflitos e otimizamos tráfego de dados nos links de comunicação entre as instalações distribuídas, que muitas vezes constituem gargalos nos sistemas.
A escolha do modelo de replicação adequado depende das características do negócio. Considere-se uma empresa com gestão de preços centralizada chamada “Corp”, com matriz de mesmo nome em São Paulo-SP e filiais no Paraná-PR, Rio de Janeiro-RJ e Rio Grande do Sul-RS. Abaixo, seguem algumas perguntas que direcionam na escolha do modelo apropriado:
a) A distribuição de dados deve ser efetuada de maneira unilateral (da base central para as filiais) ou a própria loja poderá alterar o preço dos produtos? Se a própria loja alterar o preço de um produto, será preciso distribuí-lo para as demais?
b) Qual a latência desejável para sincronia dos dados?
c) As filiais devem receber somente os preços praticados naquele local ou uma loja deve possuir acesso aos preços praticados em toda a rede?
d) A sincronização deve ser feita sempre para toda a lista de produtos ou somente para os produtos cujo preço foi alterado?
A Microsoft, em face desses questionamentos, sugere três modelos para réplica de dados - Transacional, Merge e Snapshot - que serão analisados tomando por base a empresa fictícia “Corp”, onde toda a rede pratica a mesma política de preços, ditada pela matriz em atualizações semanais de listas.
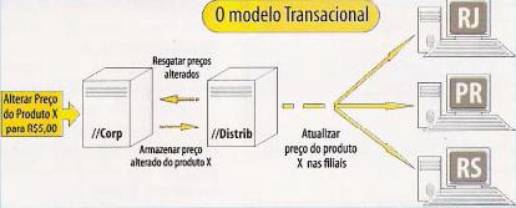
Como o próprio nome sugere, esse modelo baseia-se na atualização das filiais a partir do log de transações copiado do servidor principal. Ao atualizar o preço de um produto em “Corp” (Figura 1), o log do comando que gerou essa alteração será copiado para uma base específica (“Distrib”), para posterior distribuição nas filiais de RJ, PR e RS. Resumidamente, a replicação transacional armazena e distribui comandos de manipulação de dados (Insert/Update/Delete) nas tabelas assinaladas para réplica de dados. Note que a atualização é unidirecional (Central => Filiais).
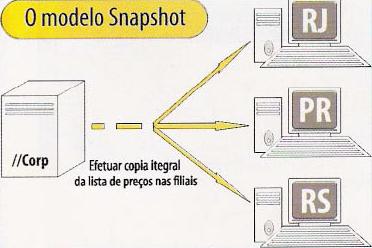
Na replicação Snapshot, os objetos são exportados integralmente a cada execução de um job específico no distribuidor, também conhecido como “agente de sincronização”. Isto significa que as listas de preços nas filiais seriam substituídas semanalmente por cópias atualizadas, independentemente de alteração de preços.
Essa modalidade de replicação não controla atualizações, inserções e/ou deleções; simplesmente substitui uma cópia por outra, como mostra a Figura 2.
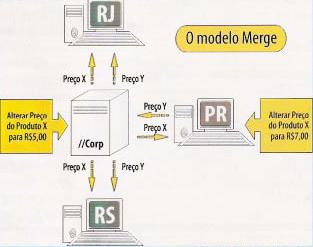
Baseia-se em triggers criadas nas tabelas replicadas. Essas triggers fazem a movimentação de dados para tabelas de sistema responsáveis pela sincronização entre as bases replicadas. Os Jobs ou “Agentes de Sincronização” que, no modelo snapshot eram específicos do distribuidor, agora funcionam em todas as instalações distribuídas. Eles identificam as alterações e desencadeiam o processo de atualização nas bases replicadas. Observe-se que, na Figura 3, o preço Y, alterado diretamente no ponto de venda PR, deve ser atualizado primeiramente em “Corp” para que depois seja sincronizado com os outros pontos.
Um fato interessante diz respeito ao que aconteceria se, na empresa “Corp”, após uma reestruturação, fosse permitido que as filiais tivessem autonomia para alterar e divulgar preços para as outras filiais e, conseqüentemente, em duas filiais, o preço de um mesmo produto fosse alterado para valores diferentes. Na sincronização semanal, surgiria um impasse: que preço aplicar para a rede? O mais baixo? Aquele que foi primeiramente registrado? A replicação merge possui um tratamento especial para conflitos, que permite rastrear e resolver esse tipo de problema. O algorítmo é bastante simples: na criação do modelo, são definidas prioridades para cada participante, vencendo quem possuir a maior. Se o preço do produto X for alterado na filial RJ (prioridade 0.3) para R$ 4,00, e na filial RS (prioridade 0.8) para R$5,00, na ocasião do conflito o preço da filial RS seria vencedor, sendo então repassado para a rede.
Segue agora um exemplo prático para criação do processo de replicação. Serão definidas, passo a passo, as etapas existentes na criação de um modelo que atenda a empresa “Corp” na distribuição de listas de preços para suas filiais.
O primeiro passo é registrar no Enterprise Manager todos os servidores envolvidos (\\Corp, \\Distrib, \\PR, \\RJ e \\RS) com uma conta que possua privilégios de “system administrator”, aqui chamada de “replicador”, especialmente criada para esse fim.
A replicação é um processo complexo que envolve agentes específicos para o controle das diversas operações. O passo inicial é, portanto, definir um servidor, aqui chamado de Distribuidor, para gerenciar esses agentes. As atribuições de um distribuidor envolvem armazenamento, distribuição e controle das cópias de dados. É aconselhável que o Distribuidor esteja num servidor separado do banco de dados por questões de segurança (uma vez que ele precisa ter acesso as instalações distribuídas e, se o banco de dados estivesse fisicamente na mesma máquina, teríamos o risco do acesso indevido a dados da base corporativa) e também da otimização do processamento tanto do distribuidor, que executa os jobs referentes a replicação, quanto do banco de dados que, se acessado por outros clientes, não teria sua performance prejudicada. No servidor \\Distrib, selecione Replication\ ConfigurePublishing . Na próxima tela confirme Make “Distrib” its own Distributor e prossiga (Vide Figura 4).
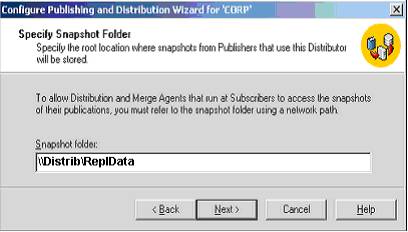
“Snapshot Folder” é uma pasta que deve ser criada no distribuidor para armazenamento temporário do schema e dados para inicialização das subscrições (como podemos chamar as filiais receptoras das atualizações). Deve ser uma pasta pública e visível pelas subscrições. (Vide Figura 5).
Pra prosseguir selecione No, user the following default settings em Customize Configuration.
É necessário definir que o servidor \\Corp (onde é efetuado o cadastro e alteração das listas de preços), utilizará os serviços de \\Distrib para divulgação das listas nas filiais. Nesse contexto, \\Corp passa a ser chamado de “Publicador”, por ser responsável pela publicação da lista de preços.
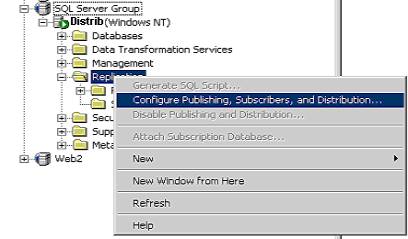
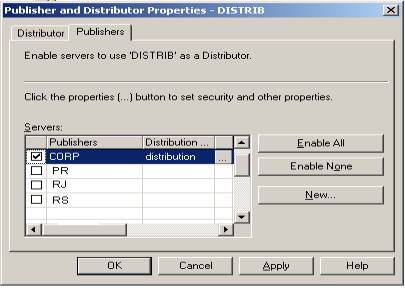
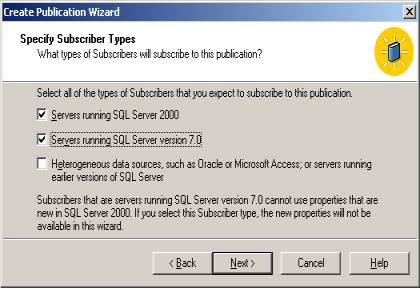
Inicialmente, é preciso liberar o acesso de \\Corp aos serviços do distribuidor. Para isso, na máquina \\Distrib, entre no Enterprise Manager e clique com o botão direito do mouse em Replication. No menu, selecione “Configure Publishing, Subscribers and Distributor” e escolha a guia Publishers conforme a Figura 6.
Na guia Publishers, deve-se liberar o acesso de \\Corp para utilização dos serviços de \\Distrib (preste atenção pois esse procedimento é executado no distribuidor \\Distrib) identificando o servidor Corp como Publisher. Para isso, marque a Check Box e clique nas reticências ao lado de “...distribution...”. Informe a conta e senha que devem ser utilizadas quando o agente de leitura – também conhecido como “Log Reader”- se conectar no publicador para leitura do log de transações a fim de efetuar a replicação. Essa conta, como informado no início, é conta definida no servidor de domínio da rede e deve possuir privilégios de “system administrator” em todos os servidores envolvidos na replicação (\\Corp, \\Distrib, \\RJ, \\PR, \\RS).
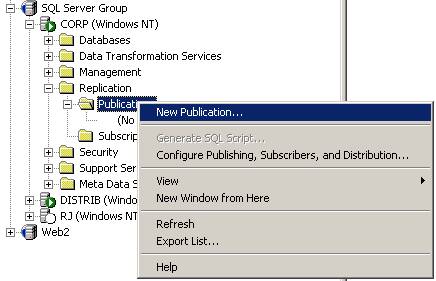
Uma vez definido que \\Corp poderá efetuar publicações controladas por \\Distrib o próximo passo será a criação da publicação. Para isso, no servidor \\Corp, clique com o botão direito do mouse em Publication e selecione “New Publication” (Figura 7).
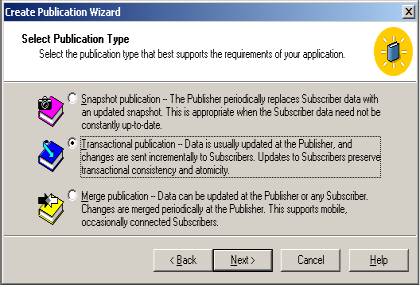
O modelo selecionado para a replicação será o modelo transacional, pois, de acordo com as regras de negócio do exemplo que envolve a replicação de uma tabela de preços, a entrada de dados ocorre num único ponto, com distribuição centralizada, as bases replicadas não inserem ou alteram dados e, neste caso, é exigido uma alta fidelidade da réplica com as bases publicadas.
Dando continuidade, na tela “…Select a Distributor ...”, é indicado o servidor \\Distrib, na opção “...Use the following server (the selected server must already be configured as distributor) “. Em seguida seleciona-se o database “db_Corp” como publicador e posteriormente o modelo de replicação, como mostra a Figura 8.
Note que as listas são atualizadas somente no Publicador (\\Corp); as alterações de preços devem ser enviadas de maneira incremental para as filiais, o que justifica a escolha do tipo Transacional. Clique em next para a definição dos tipos de subscrições.
As filiais receptoras das alterações de preços passam a ser conhecidas por Subscrições. Serão criadas, portanto, três subscrições, uma para cada filial (RJ, PR e RS). Nesse momento, será definido também que cada filial deverá receber uma carga inicial, que inclui criação do schema da tabela “Preco_Item” e respectiva carga de dados.
Como nosso ambiente é baseado na plataforma SQL Server 7.0 & 2000 é aconselhável a seleção das duas opções marcadas na Figura 9.
No próximo passo especificaremos os Artigos.
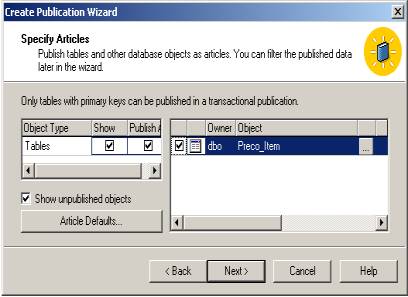
Artigo é a unidade básica de replicação. Um artigo pode representar uma tabela ou uma stored procedure. Consideraremos o artigo “Preco_Item”, envolvendo, a tabela de mesmo nome, localizada no database “db_Corp” no servidor \\Corp. (Vide Figura 10)
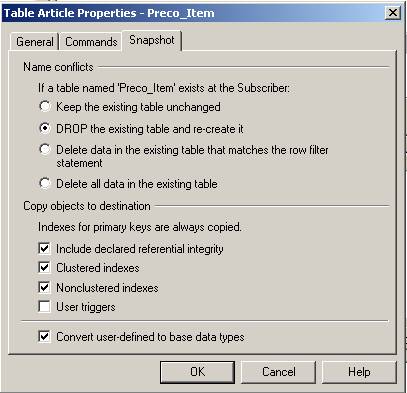
Nas reticências (...) ao lado da tabela “Preço_Item”, são confirmadas as opções em evidência na guia “Snapshot” , conforme é mostrado na Figura 11.
O snapshot (carga inicial da tabela “Preço_Item” nas subscrições) deverá criar a estrutura da tabela, carregando também índices e foreign keys. Se por algum motivo a tabela já existir no destino, sua estrutura deverá ser atualizada.
Após a indicação do nome da publicação como “Lista_Preços” a etapa é confirmada e não é aconselhável mais nenhuma customização, pois todas as filiais recebem o preço de todos os produtos, bastando apenas a finalização da criação da publicação.
Ao término da criação da publicação definiremos as subscrições em \\PR, \\RJ e \\RS.
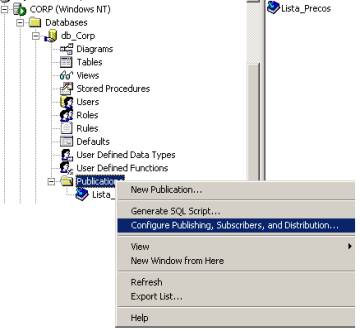
Antes, porém, é necessário conceder permissão a essas subscrições para que assinem a publicação “Lista_Preços” definida no servidor \\Corp. Para isso, deve-se expandir o servidor \\Corp, o database “db_Corp” e clicar com o botão direto do mouse em “Publication” acessando o menu “ Configure Publishing, Subscribers and Distribution ...” conforme demonstrado na Figura 12.
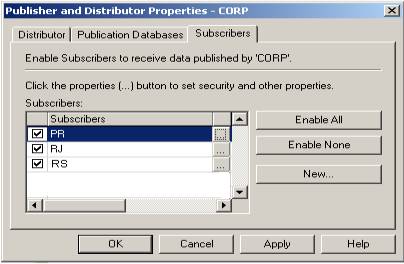
Na guia Subscribers as subscrições \\PR, \\RJ e \\RS devem estar habilitadas para que possam assinar a publicação a ser definida em \\Corp . Clicando nas reticências, é obrigatório que o usuário “replicador” - utilizado pelos jobs de sincronização – esteja assinalado em “Use SQL Server”, como vemos na Figura 13
Basicamente, a replicação Transacional fornece dois tipos de subscrição: Push e Pull.
Na modalidade “Push”, o distribuidor “empurra” as alterações para as subscrições; todo o processo de distribuição é controlado por jobs localizados no Distribuidor.
No modo “Pull”, as filiais “puxam” as alterações do distribuidor; o job que controla esse processo está localizado na própria subscrição.
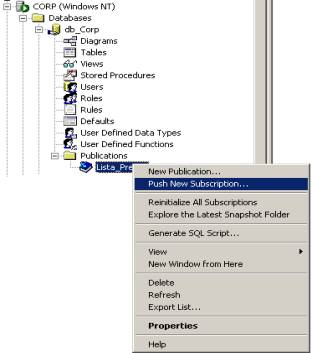
Por facilidade de administração (todas as filiais podem ser controladas de um ponto único no distribuidor) escolheremos o modelo “Push”. Para isso selecione a publicação Lista_Preços no database db_Corp em \\Corp e, com o botão direito do mouse, selecione o menu “Push New Subscription”. Vide Figura 14.
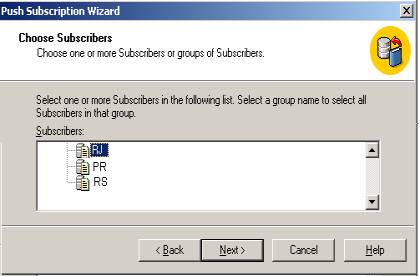
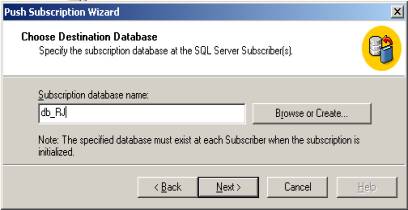
Prossiga selecionando as subscrições (Figura 15) e o nome dos databases na mesma Figura 16).
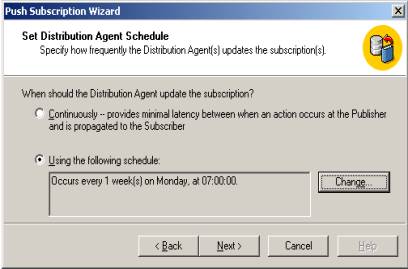
Os nomes dos databases nas subscrições \\PR, \\RJ e \\RS são, respectivamente, “db_PR”, “db_RJ” e “db_RS”. O Próximo passo é definir a periodicidade de sincronização. Neste exemplo utilizaremos um schedule para sincronizar as filiais aos domingos, às 07:00hs da manhã. Vide Figura 17.
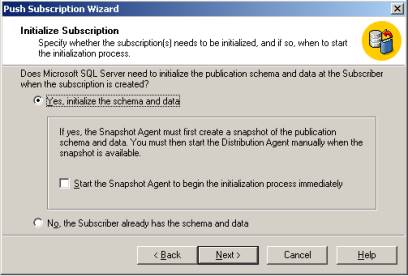
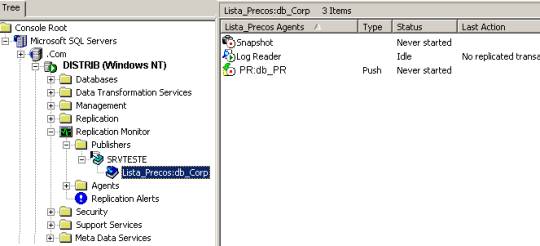
Confirme a inicialização da subscrição em “Yes, inicialize the schema and data” (Figura 18) e prossiga finalizando o processo. Confirme no Enterprise Manager em \\Distrib a criação da subscrição. Vide Figura 19.
O último passo é a execução do snapshot, que irá inicializar a réplica na loja. Selecione em Distrib “Lista_Precos” e no painel da direita clique com o botão direito do mouse em “Snapshot”. selecione “Start”. Será então efetuada a cópia do schema da tabela “Lista_Item” seguida da carga inicial dos dados. A partir daí um job schedulado no servidor \\Distrib se encarregará da atualização semanal. Para criação das outras subscrições, basta repetir os processos a partir do passo 4.
Escolha Replicação Transacional quando:
Escolha Replicação Snapshot quando:
Escolha Replicação Merge quando:

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.