Atençăo: esse artigo tem uma palestra complementar. Clique e assista!
O artigo descreve como é feita a alteraçăo de comportamento de classes da VCL em tempo de execuçăo. A alteraçăo será feita através de substituiçăo de código diretamente nas páginas de memória, durante a inicializaçăo do aplicativo. Alterar o código de partes compiladas da VCL obriga a posterior recompilaçăo de componentes de terceiros e partes da própria VCL.
Para que serve
Esta técnica é utilizada para substituir funçőes que săo executados com muita frequęncia e que se substituídas por versőes otimizadas, podem trazer uma grande melhoria no desempenho ou tempo de execuçăo de aplicativos. Considera-se que năo se pode alterar o código por vias normais, por exemplo, estendendo a funcionalidade de uma classe através de herança.
Em que situaçăo o tema é útil
Estas substituiçőes de código săo frequentemente utilizadas pelos projetos DelphiSpeedUp e FastCode. Como eles substituem partes da RTL por códigos otimizados, a fim de melhorar o tempo de execuçăo da IDE, săo obrigados a fazer as alteraçőes em memória, já que năo podem modificar o código fonte da IDE e VCL. As técnicas podem ser aplicadas no dia a dia para otimizar partes da VCL e estruturas de dados utilizadas nos aplicativos.
Resumo do DevMan
Este artigo mostra como se pode alterar o comportamento de um aplicativo em tempo de execuçăo, substituindo partes de código na memória por outras, otimizadas. Esta técnica é usada pelos desenvolvedores do projeto FastCode, um projeto que tem a intençăo de reescrever várias funçőes da VCL do Delphi com o objetivo de torná-las mais rápidas. O projeto tem uma visibilidade tal que a própria CodeGear/Embarcadero tem atualizado algumas de suas funçőes com base no que foi disponibilizado no projeto. Além disso, esta técnica também é utilizada por Andreas Hausladen em seus utilitários para Delphi. Um exemplo de uso da técnica é o utilitário DephiSpeedUp que substitui funçőes do Delphi e torna a IDE muito mais rápida. Mais informaçőes sobre o plug-in podem ser obtidas aqui: http://andy.jgknet.de/blog/?page_id=8
Desenvolver um framework como a VCL năo é uma tarefa fácil. Ter em mente todos os possíveis usos que um desenvolvedor poderá fazer de uma quantidade imensa de classes năo é tăo simples. Devido a estas dificuldades, muitas partes do código năo recebem a devida atençăo ou năo săo codificadas pensando em requisitos agressivos de desempenho. Muitas vezes vocę nem sabe que usa, mas estes códigos estăo lá no seu executável final, rodando no cliente e levando um tempo precioso para ser processado.
Além do mais, há a questăo do uso de conjuntos de instruçőes dos processadores mais novos. Do que adianta comprar um processador com um conjunto de instruçőes SSE3 se o compilador năo gera executáveis que fazem uso delas?
As extensőes SSE3(Streaming SIMD Extensions 3) permitem um alargamento das capacidades SIMD disponibilizadas pelas extensőes SSE e SSE2. Permitem um aumento do desempenho no processamento de dados em diversas áreas como, por exemplo, a aritmética de números complexos e na descodificaçăo de vídeo. Mais informaçőes em http://pt.wikipedia.org/wiki/SSE3
Mas existe um bom motivo para evitar o uso destes conjuntos de instruçőes: O executável tem que ser compatível com todos os processadores. Mas năo teria uma forma de aproveitar tais instruçőes quando disponíveis?
Pensando nestes detalhes, o projeto FastCode cria rotinas substitutas para funçőes que săo muito chamadas durante a execuçăo do programa. Tais rotinas identificam as capacidades do processador da máquina e substituem funçőes da RTL e VCL por versőes otimizadas, adequadas ao processador em uso.
O interessante da abordagem que o projeto FastCode usa é que basta apenas incluir a unit com as otimizaçőes no seu projeto. Nada de alteraçőes no código de seu aplicativo para usufruir das otimizaçőes. Mas como isso é feito? Como substituir funçőes da VCL sem alterar os pas/dcus da mesma? Ora, o compilador lę estes arquivos ao gerar o executável, năo é mesmo?
Esta substituiçăo năo é algo simples. De fato seria muito mais fácil alterar o código da unit da VCL diretamente. Mas isso implica em recompilar todas as dependęncias da unit alterada, inclusive componentes de terceiros e até mesmo partes da própria VCL. O impacto da alteraçăo é grande e se espalha bastante, dependendo da unit alterada. Já recebeu a mensagem de erro na compilaçăo: “Unit x was compiled with a different version of y”?
Para entender o que é feito, voltemos ŕ arquitetura de computadores que usamos: a arquitetura de Von Neuman. Nela, todo programa sai do dispositivo de armazenamento secundário (disco rígido) e vai para a memória principal para ser processado. E é aqui que mora o segredo: páginas de memória podem ser alteradas.
John von Neumann: é considerado um dos mais importantes matemáticos do século XX. Foi membro do Instituto de Estudos Avançados em Princeton, New Jersey, do qual também faziam parte Albert Einstein. A maioria dos computadores de hoje em dia segue ainda o modelo proposto por von Neumann. Esse modelo define um computador sequencial digital em que o processamento das informaçőes é feito passo a passo, caracterizando um comportamento determinístico (ou seja, os mesmos dados de entrada produzem sempre a mesma resposta).
Existem métodos no sistema operacional que permitem a alteraçăo de partes da memória enquanto o programa está sendo executado. Isto é feito a todo o tempo, na área de dados do aplicativo, quando o valor de variáveis é alterado, quando dados săo carregados do banco de dados etc.
O código compilado do aplicativo também vai para a memória. É possível alterar a área de memória onde ele está. Sim, é isso mesmo. Alterar os bits de código diretamente na memória RAM, ou seja, alterar o comportamento do aplicativo enquanto ele é executado. Modificar o código que foi lido do disco rígido. Obviamente existem restriçőes. Já pensou se qualquer aplicativo pudesse alterar o código de outro em execuçăo? Seria um prato cheio para desenvolvedores de vírus.
Em nosso caso o próprio aplicativo se alterará, quando iniciar sua execuçăo. Do contrário, receberíamos um Access Violation. Faz mais sentido agora o que é um Access Violation? É uma simples tentativa de acessar ou alterar memória que năo te pertence!
Resumindo, o que é feito é uma alteraçăo nas páginas de memória que o executável ocupa, logo após ele ser carregado na memória. Desta forma, o executável que está no disco rígido será diferente do executável sendo executado na memória RAM.
Neste artigo será exemplificado como se pode fazer tais substituiçőes, otimizando o método FindField da classe TFields. Este método é lento porque faz um laço varrendo todos os campos do TDataSet ŕ procura de determinado campo. É o método chamado quando se executa TDataSet.FieldByName('NOME') por exemplo.
Năo se engane pensando que, porque vocę năo usa este método nos seus fontes, ele năo é usado no seu aplicativo. Na verdade a própria VCL faz uso extensivo deste método, pois precisa ligar os seus próprios componentes aos TFields do DataSet. Isso inclui TDBEdits, TDBGrids, geradores de relatórios e qualquer outro componente que faz uso de qualquer classe descendente de TDataSet.
Analisando a complexidade do método FindField
Como dito na introduçăo, o algoritmo FindField é lento porque ele simplesmente varre todos os campos do DataSet, em ordem de índice, até encontrar o campo procurado. Isso é feito porque o campo é procurado através de seu nome.
Observando o código da Listagem 1, podemos fazer a seguinte análise de complexidade, a respeito do algoritmo FindField. Observe que a entrada do algoritmo é a lista de campos do DataSet, com n entradas/campos:
• No melhor caso é Ω(1). O campo procurado é o primeiro da lista. O laço for da linha 5 será executado apenas uma vez e o exit da linha 8 será entăo chamado.
•
No caso médio é Θ 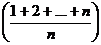 se todos os campos
forem consultados a cada iteraçăo.
se todos os campos
forem consultados a cada iteraçăo.
• No pior caso é O(n). O campo procurado é o último ou năo existe. O nome do campo foi comparado com todos os outros.
Os termos melhor caso, caso médio e pior caso, representados pelos símbolos Ω, Θ e O respectivamente, vem da disciplina Complexidade de Algoritmos. Dizem respeito ao tempo que um algoritmo leva para concluir seu processamento, em relaçăo ao tamanho da entrada que lhe é dada. Neste exemplo a entrada é a lista de todos os campos. O(n) quer dizer que todos os campos da lista (n campos) serăo consultados para se chegar ŕ resposta do processamento. Complexidades comuns na literatura săo O(n lg n) e O(n˛) para algoritmos de ordenaçăo de listas, O(nł) para busca de caminhos mínimos em grafos, dentre outros. Esta disciplina é estudada geralmente em cursos na área de computaçăo.
Listagem 1. Código do método FindField da VCL
1. function TFields.FindField(const FieldName: string): TField;
2. var
3. I: Integer;
4. begin
5. for I := 0 to FList.Count - 1 do
6. begin
7. Result := FList.Items[I];
8. if WideCompareText(Result.FFieldName, FieldName) = 0 then Exit;
9. end;
10. Result := nil;
11. end; Existem pelos menos duas formas de se otimizar este código: Através de uma lista ordenada ou uma lista Hash. Com uma lista ordenada conseguiríamos um tempo O(lg n) sempre, indiferente se o campo está no começo ou final da lista. Esta abordagem introduz um overhead devido ŕ necessidade de ordenaçăo desta lista. Poderíamos realizar esta ordenaçăo em tempo Θ(n lg n), utilizando o algoritmo quicksort por exemplo. A ordenaçăo deveria ser executada uma vez a cada abertura do DataSet. Escrevi um artigo sobre este método no meu blog pessoal, no artigo “FieldByName é O(n), que tal melhorá-lo para O(Lg n)?” que está disponível em www.thborges.com/?p=36.
Irei um pouco além agora. Explicarei como otimizar o método FindField utilizando uma tabela Hash. Esta abordagem garante um tempo constante de praticamente O(1), indiferente da posiçăo que o campo ocupa no DataSet. É como se a funçăo sempre soubesse onde está o campo na lista, olhando apenas para seu nome.
O que é uma tabela Hash?
Uma tabela Hash é uma estrutura de dados que armazena um conjunto de itens em um array, utilizando uma funçăo de espalhamento para determinar o índice onde cada item será armazenado. A funçăo de espalhamento, ou funçăo hash, opera sobre o conjunto de itens, convertendo cada um deles em um número inteiro. Este número inteiro é utilizado como índice no array onde o item será armazenado.
Diz-se que esta funçăo é perfeita se a mesma consegue atribuir a cada item da lista um número único, sem repetiçőes. E pode ainda ser mínima se faz este mapeamento utilizando a menor quantidade de índices possíveis, sem repetir. Observe na Figura 1 que cada nome foi mapeado em um índice do vetor, mas sobraram posiçőes no vetor. Esta funçăo é dita perfeita, mas năo mínima. Ao contrário, na Figura 2, observe que năo há posiçőes năo utilizadas no vetor, portanto a funçăo é mínima.
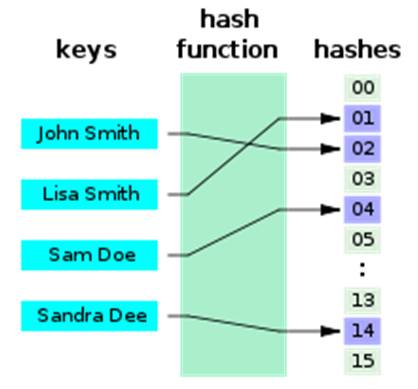
Figura 1. Funçăo hash perfeita (fonte: Wikipedia)
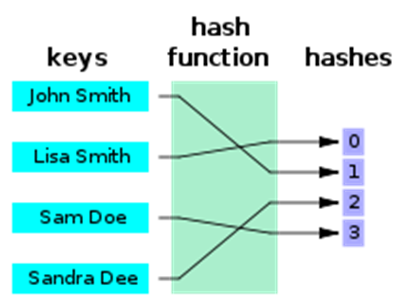
Figura 2. Funçăo hash mínima (fonte: Wikipedia)
Na prática, funçőes hash mínimas e perfeitas săo difíceis de obter. Em geral a funçăo retorna índices repetidos para itens distintos. Por esse motivo, em cada posiçăo do array é armazenado năo somente um, mas vários itens. De forma que, quanto mais índices repetidos a funçăo retornar, pior será a estrutura de dados em relaçăo ao tempo de busca de um determinado item. Mas como uma tabela hash pode melhorar o tempo de busca de itens em uma lista? No nosso caso temos campos nomeados, cujos nomes năo podem se repetir para uma determinada tabela. Durante o processo de inserçăo dos campos no DataSet iremos executar uma funçăo hash que opera sobre strings, passando como parâmetro o nome do campo. A funçăo irá retornar um número inteiro. Digamos que para o campo de nome CODCLIENTE a funçăo retorne 10. Incluiremos entăo o campo na posiçăo 10 de um array. Faremos isso para todos os campos. Quando o método FindField for executado, pegaremos seu parâmetro (o nome do campo procurado) e chamaremos a funçăo hash. Esta devolverá exatamente o índice do array (10) no qual o campo foi armazenado.
Há uma particularidade neste método. As formas mais simples de tabelas hash exigem que a quantidade de posiçőes no array seja previamente conhecida. Os limites da funçăo hash văo, por exemplo, de 0 a 64. Isso quer dizer que a funçăo nunca irá retornar um número maior que 64, independente da string passada como parâmetro. Para os campos de um DataSet isso pode ser um exagero, visto que geralmente năo se tem uma tabela com tantos campos. O ideal é que se identifique um valor que cause a menor quantidade de repetiçőes de índices possível. Se a funçăo hash fosse perfeita e mínima, este valor seria a quantidade de campos no DataSet.
Para nosso propósito utilizaremos a funçăo hash codificada pelo projeto DelphiSpeedUp. A funçăo hash, apesar de simples, foi codificada utilizando a linguagem assembly. O código assembly da funçăo está na Listagem 2. Nas linhas 5 a 7 calcula-se o tamanho da string. A seguir nas linhas 10 a 26 existe um loop percorrendo os caracteres da string. Observe que o @@ indica um label e a instruçăo jnz é como um goto que volta para este label, enquanto năo chegar ao fim da string. Na primeira etapa, linhas de 11 a 17, é feita uma operaçăo que desconsidera letras maiúsculas e minúsculas. Observando a ordem dos caracteres na tabela ASCII, subtrair 'a' - 'A' de um caractere minúsculo, corresponde a transformá-lo em uma letra maiúscula. Nas linhas 20 a 23 é feito o cálculo do hash, somando o ordinal de cada caractere ao resultado. Por fim na linha 28 faz-se a operaçăo de módulo 64, que é o resto da divisăo do número encontrado por 64. Note que o resto desta divisăo nunca é maior que 63 e isto garante que todos os campos serăo armazenados em 64 posiçőes de um array.
Cada caractere na tabela ASCII é representado por um número. Inicialmente foram definidos 128 caracteres, de 0 a 127, e incluem caracteres de controle (quebra de linha, retorno de carro, além de outros) e caracteres que possuem representaçăo gráfica (as letras, números e símbolos). Quando se subtrai uma letra por outra, obtém-se um número. No caso da funçăo HashUpString, subtrair 'A' – 'a' é o mesmo que subtrair 97 – 65 = 32. Desta forma, subtrair 32 de uma letra minúscula qualquer a transforma em uma letra maiúscula. Por exemplo, a letra 't' (116) – 32 = 'T' (84).
Listagem 2. Funçăo HashupString do projeto DelphiSpeedUp
1. function HashUpString(const AItem: string): Integer;
2. asm
3. or eax, eax
4. jz @@Leave
5.
6. xchg eax, edx
7. mov eax, [edx-$04] // Length(AItem)
8. xor ecx, ecx
9.
10. @@HashStringNextChar:
11. mov cl, [edx]
12.
13. cmp cl, 'a'
14. jb @@UpCaseEnd
15. cmp cl, 'z'
16. ja @@UpCaseEnd
17. sub cl, 'a' - 'A'
18. @@UpCaseEnd:
19.
20. ror cl, 4
21. shl cx, 1
22. add eax, ecx
23. xor ch, ch
24. inc edx
25. or ecx, ecx
26. jnz @@HashStringNextChar
27.
28. and eax, 64-1
29. @@Leave:
30. end; Passo a passo da alteraçăo na classe TFields
A otimizaçăo do método FindField será feita em quatro passos, como descrito a seguir:
1. Cria-se uma nova unit, onde serăo declaradas as classes auxiliares e executados os métodos de substituiçăo na seçăo initialization. Chamaremos de FieldOptimize.pas;
2. Cria-se a classe TNameHashListque será a lista hash, descendente de TList. Será usada para substituir a lista de campos da classe TFields (veja detalhes a seguir);
3. Cria-se uma cópia parcial da classe TFields, para poder acessar seus campos privados através de um typecast forçado. Chamaremos de TPrivateFields;
4. Cria-se a classe TFastFieldsque conterá apenas o método FindField otimizado.
A classe TNameHashList
A classe TNameHashList é uma variaçăo da classe de mesmo nome do projeto FastCode, mais precisamente da unit RtlVCLOptimize.pas. É necessária apenas uma adaptaçăo para que ela opere com TFields.O ponto mais importante da construçăo é a reescrita do método Notify. Este método é invocado pela TList sempre que um item é adicionado ou removido da lista. Assim, sempre que isso acontecer estaremos alimentando um vetor adicional, que é o hash em si.
Tręs métodos săo necessários: NameAdd, NameRemove e NameFind. Estes métodos serăo chamados para adicionar, remover e procurar um item na lista hash, respectivamente.
Observe na Listagem 3 o método NameAdd. Na linha 8 é chamado o método HashupString (descrito na Listagem 2) armazenando seu retorno em AHash. AHash representa o índice onde o TField deve ser inserido. Pode ter ocorrido uma colisăo de índices e a posiçăo AHash já está sendo usada por outra entrada. Salva-se entăo, Linha 9, o conteúdo corrente da posiçăo AHash no campo Next de uma nova estrutura N do tipo NameCompItem, formando uma lista ligada (veja Nota do DevMan). A seguir, linhas 10 a 13, a posiçăo AHash do array é substituída pela nova entrada e o par Key/Value da estrutura N é preenchido com o nome do campo e sua instância, respectivamente.
Observe que a lista ligada é necessária devido a possibilidade de colisőes, conforme pode ser observado na Figura 3. Veja que Sandra Dee e John Smith estăo posicionados no índice 152 do array. É neste detalhe que está a velocidade ou lentidăo de uma lista hash. Se esta lista ligada ficar muito longa, ou seja, ocorrerem muitas colisőes, o processo de busca ficará lento.
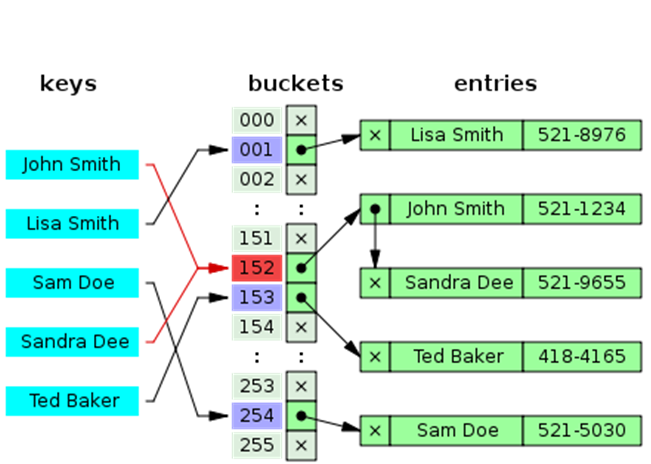
Figura 3. Tabela Hash com colisăo na posiçăo 152. Observe que John Smith está na mesma posiçăo que Sandra Dee (fonte: Wikipedia)
Listagem 3. Funçăo NameAdd da classe TNameHashList
1. function TNameHashList.NameAdd(const AItem: string;
2. AData: TField): TField;
3. var
4. N: PNameCompItem;
5. AHash: Integer;
6. begin
7. New(N);
8. AHash := HashUpString(AItem);
9. N.Next := FItems[AHash];
10. FItems[AHash] := N;
11. Inc(FNameCount);
12. N.Key := AItem;
13. N.Value := AData;
14. Result := AData;
15. end; O que a funçăo NameRemove faz é remover um item da lista hash. Inicialmente chama-se HashupString com o nome do campo que será removido. Como na inserçăo também foi utilizada esta funçăo para escolher em que índice o campo seria inserido, o mesmo só pode estar na lista ligada da posiçăo retornada, digamos que seja a posiçăo P. Procura-se entăo na lista ligada do índice P pelo respectivo campo. O campo pode estar no início, meio ou fim da lista, portanto ao remover é necessário manter os links entre os itens corretamente, cada um apontando sempre para o seguinte. O código foi omitido para evitar poluiçăo do texto, mas está disponível no download do artigo.
Por fim, a funçăo NameFind, Listagem 4, é responsável por encontrar um campo na lista hash. Encontra-se a posiçăo AHash no array, onde o campo pode ter sido armazenado, utilizando o nome do campo procurado, Linha 8. A lista ligada desta posiçăo é entăo percorrida, Linhas 10 a 19, até que se encontre um campo com o nome procurado. Caso o campo năo exista, a lista será percorrida item a item.
Observe que existe uma situaçăo de pior caso, onde todos os campos estăo armazenados na mesma posiçăo do array, tornando a lista muito grande. A procura neste caso seria tăo ruim quanto a do método original. Porém, no caso de TFields, esta lista tende a năo ser muito grande devido os nomes dos campos serem sempre diferentes uns dos outros. Fica evidente aqui também a importância de escolher um tamanho adequado para o array da lista hash.
Listagem 4. Declaraçăo parcial da classe TFields na unit DB.pas
1. function TNameHashList.NameFind(const AItem: string;
2. out Value: TField): Boolean;
3. var
4. N: PNameCompItem;
5. AHash: Integer;
6. begin
7. Value := nil;
8. AHash := HashUpString(AItem);
9. N := FItems[AHash];
10. while N <> nil do
11. begin
12. if CompareText(N.Key, AItem) = 0 then
13. begin
14. Value := N.Value;
15. Result := True;
16. Exit;
17. end;
18. N := N.Next;
19. end;
20. Result := False;
21. end; As classes TPrivateFields e TFastFields
Fazendo uma analogia, será necessário fazer uma “cirurgia” na classe TFields, em tempo de execuçăo. Fazer um transplante de sua lista de campos FList, digamos o seu coraçăo, e conectar algumas artérias (método FindField) a outros locais. Porém, o campo FList da classe TFields é privado. Precisaremos utilizar um typecast um pouco forçado para conseguir acessá-lo, destruí-lo, e substituir por uma instância de TNameHashList.
A cięncia está por trás do typecast. Ensinaram-te que o typecast "transforma" uma classe em outra, certo? Mas além do básico, o que está acontecendo é apenas uma manipulaçăo de endereços de memória. É vocę dizendo ao compilador: "Acesse os campos deste objeto como se ele fosse este outro". E entăo o compilador começa a gerar o executável escrevendo: O primeiro campo do objeto está na posiçăo onde o objeto está instanciado + 4 bytes, o segundo na posiçăo inicial + 8 bytes e por aí vai. Tudo se resume a endereços de memória e intervalos.
Declara-se entăo uma nova classe TPrivateFields, idęntica ao início de TFields. Descendendo da mesma classe (TObject) que a TFields, declarando os campos da seçăo private até chegar no desejado. Todos os campos declarados tęm que estar na mesma ordem e posiçăo.
Desta forma, como todos os campos estăo na mesma ordem, e portanto com os mesmos intervalos de endereços de memória do objeto original, podemos acessar qualquer campo privado do objeto como se fosse o nosso próprio. Mas atençăo, os desenvolvedores da VCL podem mudar esta ordem de uma versăo para outra, fique atento.
Na Listagem 5 está a declaraçăo da classe TPrivateFields. Note que o FList é o primeiro campo da seçăo private, e por isso ela ficou bem simples. O segredo maior está na classe TFastFields. Ela existe apenas para conter a funçăo FindField. Sequer será instanciada durante toda a execuçăo do projeto. Nela declaramos FindField com a mesma assinatura da TFields.FindField, Linhas 8 a 11. A implementaçăo deste método consiste em testar se a FList já é uma instância de TNameHashList e, caso contrário, substituí-la. Para isso, faz-se o typecast para acessar o campo privado FList, Linha 20. Caso năo seja (Linhas 22 a 28), instancia-se uma nova TNameHashList (Linha 22) copia-se os campos porventura já existentes na lista original (Linhas 24 a 26), substitui-se a lista antiga pela nova TNameHashList, Linha 27) e por fim destrói-se a lista antiga, Linha 28. Mas atençăo, essa substituiçăo só funciona porque a TNameHashList também é descendente de TList. Note que todo o código da classe TFields continua acessando o campo privado FList como se nada tivesse acontecido.
Năo ocorre vazamento de memória porque a própria classe TFields se encarregará de destruir a tabela hash. Na verdade ela irá destruir o conteúdo da variável FList, achando que lá existe uma TList comum, mas sabemos que isso năo é verdade porque a substituímos. Porém como o método Free é herdado de TObject, năo haverá nenhum problema.
Listagem 5. Código das classes TPrivateFields e TFastFields
1. type
2.
3. TPrivateFields = class(TObject)
4. private
5. FList: TList;
6. end;
7.
8. TFasTFields = class(TFields)
9. public
10. function FindField(const FieldName: WideString): TField;
11. end;
12.
13. { TFastFields }
14.
15. function TFastFields.FindField(const FieldName: WideString): TField;
16. var
17. List, HashList: TList;
18. I: Integer;
19. begin
20. if not (TPrivateFields(Self).FList is TNameHashList) then
21. begin
22. HashList := TNameHashList.Create;
23. List := TPrivateFields(Self).FList;
24. HashList.Capacity := List.Capacity;
25. for I := 0 to List.Count - 1 do
26. HashList.Add(List.List[I]); // copy and hash
27. TPrivateFields(Self).FList := HashList;
28. List.Free;
29. end;
30.
31. TNameHashList(TPrivateFields(Self).FList).NameFind(FieldName, Result);
32. end; A mágica da substituiçăo de código com JMP ($E9)
Na memória RAM do computador há uma quantidade enorme de números que possuem os mais diversos significados. Existem números que representam dados, como letras e números, e números que representam operaçőes que o computador deve fazer. É o chamado conjunto de instruçőes do computador, como por exemplo SSE2 ou SSE3.
Há um conjunto padrăo destas instruçőes, válidos para a maioria dos processadores. Estas operaçőes incluem soma, subtraçăo, redirecionamentos e muitos outros. O que nos importa aqui é o redirecionamento, ou se preferir, o goto. Ele é representado pelo número hexadecimal $E9, instruçăo assembly JMP, que significa fazer um salto, jump, para um endereço de memória e continuar o processamento deste endereço em diante. Note que existem vários tipos de jumps. Há jumps que só saltam se determinada condiçăo for atendida, se o número for maior, igual, menor que outro, por exemplo. Este que usaremos é o incondicional.
A substituiçăo de uma funçăo por outra é feita escrevendo no início da funçăo FindField original um goto para o endereço da nova funçăo. A funçăo original é referenciada em muitos locais na memória, mas sempre que o processador chegar no endereço dela será forçado a ir para outro endereço: o endereço da nova funçăo.
Observe na Listagem 6 a funçăo CodeRedirect, extraída do projeto DelphiSpeedUp. A funçăo recebe o endereço de dois métodos como parâmetros, Proc e NewProc. Primeiro captura-se o endereço na memória onde o procedimento original está. Para isso utiliza-se a funçăo GetActualAddr, Linha 7. A seguir, linhas 8 e 9, é solicitado ao sistema operacional que permita a escrita na página onde a funçăo está localizada (Funçăo VirtualProtectEx, com parâmetro PAGE_EXECUTE_READWRITE). Na linha 11 e 12 é entăo feito o redirecionamento, utilizando o record TInjectRec. Este record serve para injetar o código assembly de salto. No primeiro byte grava-se a operaçăo (jump) e nos quatro bytes seguintes a quantidade de bytes a saltar, a partir do endereço atual. Por fim volta-se a página de memória para o estado anterior, provavelmente read-only, e executa-se um flush para descarregar a página dos registradores, evitando problemas com máquinas de vários núcleos, linhas 14 a 16.
Listagem 6. Funçăo CodeRedirect do projeto DelphiSpeedUp
1. procedure CodeRedirect(Proc: Pointer; NewProc: Pointer);
2. var
3. OldProtect: Cardinal;
4. begin
5. if Proc = nil then
6. Exit;
7. Proc := GetActualAddr(Proc);
8. if VirtualProtectEx(GetCurrentProcess, Proc, SizeOf(TInjectRec),
9. PAGE_EXECUTE_READWRITE, OldProtect) then
10. begin
11. TInjectRec(Proc^).Jump := $E9;
12. TInjectRec(Proc^).Offset := Integer(NewProc) - (Integer(Proc) +
13. SizeOf(TInjectRec));
14. VirtualProtectEx(GetCurrentProcess, Proc, SizeOf(TInjectRec),
15. OldProtect, @OldProtect);
16. FlushInstructionCache(GetCurrentProcess, Proc, SizeOf(TInjectRec));
17. end;
18. end; Colocando a cereja no bolo
Por fim e o mais importante de tudo: o redirecionamento da funçăo FindField da classe TFields para a classe TFastFields. Observe a Listagem 7. Basta fazer uma chamada ŕ funçăo CodeRedirect, passando como parâmetro o endereço do método origem e destino.
Listagem 7. Redirecionamento de TFields.FindField para TFastFields.FindField
1. initialization
2. CodeRedirect(@TFields.FindField, @TFastFields.FindField); O que acontecerá quando o aplicativo iniciar?
1. O código da seçăo initialization será invocado. Ele alterará a página de memória onde foi colocado o método TFields.FindField, forçando o processador a saltar para o endereço onde o método TFastFields.FindField foi escrito na memória, sempre que a primeira funçăo for chamada;
2. A funçăo TFields.FindField é chamada em qualquer local do aplicativo e o processador salta para a TFastFields.FindFind;
3. A nova funçăo FindField testa se a FList ainda é uma instância de TList. Como é a primeira chamada ela trocará a TList por uma TNameHashList;
4. Os campos săo adicionados na lista hash ŕ medida que văo sendo inseridos, através do método Notify reescrito;
5. O campo é posteriormente procurado na TNameHashList e retornado como se o nosso transplante năo tivesse acontecido. Porém, agora a complexidade da busca é O(1), desconsiderando as colisőes no hash.
Conclusăo
Este tipo de intervençăo em tempo de execuçăo é uma forma avançada de corrigir ou melhorar códigos de bibliotecas, muito utilizado pelos projetos FastCode e na maioria das melhorias feitas por Andreas Hausladen (andy.jgknet.de/blog), dentre elas o projeto DelphiSpeedUp.
Uma das melhorias introduzidas por tal projeto é exatamente colocar uma lista hash para ser utilizada nas chamadas do método FindComponent. Boa parte da otimizaçăo é essa. O FindComponent da VCL é feito da mesma forma que o FindField. Existe uma lista de componentes que é preenchida sempre que objetos descendentes de TComponent săo criados. Ao procurar por um componente esta lista é varrida item a item, comparando os nomes dos componentes até encontrar o desejado.
A melhora com a otimizaçăo da funçăo FindField pode ser percebida principalmente no tempo de carregamento das telas, onde acontece a maioria das chamadas a esta funçăo, vinculando os TDBEdits e correlatos aos campos nos DataSets. Nos DataModules, quando se usa campos persistidos, ocorre uma vinculaçăo entre todos os TFields logo em sua abertura. O mesmo acontece quando se abre os TDataSets. Outra situaçăo onde ocorre melhora é quando se usa o método FieldByName em rotinas que processam grandes quantidades de registros.
O uso de listas hash pode ser expandido a qualquer situaçăo onde seja necessário localizar objetos através de seus nomes. O único detalhe a observar é o tamanho do array do hash, onde serăo colocados os itens. É necessário ter uma ideia da quantidade de itens que serăo utilizados. É importante considerar também o quăo bem a funçăo hash espalha os itens nas posiçőes deste array. Dependendo da rotina, uma boa ideia é deixar esta configuraçăo como parâmetro do sistema.
Para quem utiliza versőes mais atuais do Delphi, outro ponto possível é a utilizaçăo de generics para construçăo de uma lista hash que possa ser utilizada com qualquer objeto que possua um campo representando seu nome.
Outras otimizaçőes na VCL ou em componentes de terceiros podem ser feitas. Porém, encontrá-las e saber como otimizar é uma tarefa um pouco mais complicada. Depende da experięncia e conhecimento de cada pessoa. Mas a forma de corrigir sem alterar fontes é esta.
