


Toda ou pelo menos quase todo tipo de aplicação necessita de log's, para possibilitar possíveis análises e correções de bugs em ambientes onde a depuração não é possível.
Uma aplicação em produção, por exemplo, não poderá ser depurada afim de descobrir a possível causa da falha, para isso usamos o log, que serve também como uma ótima ferramenta de auditoria.
Neste artigo estudaremos o funcionamento o Log4j 2, uma poderosa ferramenta que nos auxiliará a criar um sistema de log poderoso e funcional. Mas antes vamos conhecer um pouco da sua história e de onde ele vem.
O Log4j tem sua criação em 2001, como um poderoso “pacote” de log para a linguagem Java, este era e ainda é distribuído sobre a licença Apache Software License. Atualmente o Log4j está na versão 2.0, que é exatamente a que estudaremos aqui, no final deste artigo você poderá ver o link da documentação oficial do Log4j 2 e do Apache Software License caso queira saber quais termos ela rege.
O processo de depuração pode ser um gargalo, visto que para descobrir determinada causa de um problema é necessário adentrar em estruturas de controle complexas que fazem o desenvolvedor se perder em diversas vezes. Para eles, é muito mais produtivo perder tempo colocando mensagens de log nos locais corretos do que precisar depurar um código para descobrir um problema, mesmo que você saiba exatamente onde o problema ocorre. E por fim, a depuração é algo transiente enquanto que o log irá permanecer (em um arquivo, geralmente) por tempo indeterminado para ser analisado novamente caso necessário.
Mas o uso de logs não traz apenas benefícios, como você pode ter imaginado até o momento, pois o seu uso pode tornar a aplicação mais lenta (as vezes insignificante) e criar arquivos de log grandes (que podem checar a GB) dificultando a leitura e consequentemente a causa de determinado problema que espera-se encontrar. É pensando nesses problemas tão comuns, que o Log4j foi criado com diversas opções de configurações afim de ser tornar rápido, extensível e confiável, além de que o Log4j foi feito de forma mais simples possível para evitar que o desenvolvedor perca muito tempo com sua configuração, visto que na maioria dos casos um Sistema de Log não é o foco da aplicação.
Essa é uma pergunta que você pode se fazer, caso já trabalhe com o Log4j 1.x. Sabemos que a versão 1.x foi usada em larga escala em diversas aplicações e ainda é utilizada, porém a própria equipe de desenvolvimento do Log4j diz em seu site oficial que o esforço para desenvolvimento nesta versão foi diminuído, se não parado. De acordo com eles (Equipe Apache) há um aumento de dificuldade para manter sua atualização pois é necessário que ele seja compilado em versões mais antigas do Java, afinal como citamos anteriormente seus primórdios começam na década de 90, mais precisamente em 1996, imagine a versão do Java que era utilizada nessa época e quantas evoluções tecnológicas já houveram até hoje.
Enfim, as razões dadas acima podem não fazer com que você mude de versão, final foram explicações que ajudem a equipe Apache e não você, vamos então a alguns pontos importantes que você deve ler antes de pensar se deve ou não migrar de versão:
Bom, são muitas vantagens, algumas mais simples ou mais complexas, fique a vontade para aprofundar-se em cada uma delas.
Estudamos um pouco sobre a introdução e novidades apresentadas no projeto Log4j como um todo, agora iremos para uma seção mais técnica onde trataremos da estrutura de funcionamento de tal framework.
Vejamos a Figura 1 que foi retirada da própria documentação oficial que demonstra um diagrama de classes da framework em questão.
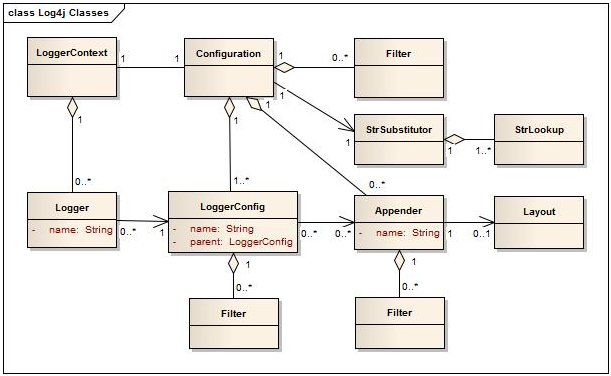
Figura 1. Diagrama de Classe Log4j 2
A grande vantagem de se utilizar qualquer API de log em contrapartida ao famoso System.out.println é a possibilidade de poder habilitar ou desabilitar determinada quantidade de mensagens sem precisar mudar a aplicação, ou seja, categorizar as mensagens de log conforme critério do desenvolvedor.
Explicando de forma resumida o diagrama acima temos que: A aplicação, usando a API do Log4j 2, requisita um determinado Logger, com um nome específico, através do LogManager. O LogManager irá localizar o LoggerContext apropriado que contém o Logger desejado (perceba que no mapeamento, 1 LoggerContext possui nenhum ou vários Logger's). Se o Logger precisar ser criado, ou seja, ainda não existir, então ele será associado a um LoggerConfig seguindo uma das condições abaixo:
a) Tenha o mesmo nome do Logger;
b) Tenha o nome do pacote pai;
c) Em último caso, usa o LoggerConfig root;
O item a) é o primeiro a ser visto a fim de capturar um LoggerConfig apropriado ao Logger, o item b) é o segundo e caso nenhum deles sejam satisfeitos o item c) com certeza será.
Os objetos LoggerConfig são criados a partir das declarações de Logger na configuração do Log4j 2. Por fim, o LoggerConfig está associado aos Appender's que são responsáveis por entregar os eventos de log ao seu destino.
Este serve como um ponto central para o sistema de log, perceba que ele esta ligado a 1 Configuration, ou seja, um LoggerContext possui uma configuração e uma configuração possui um LoggerContext. Caso necessário, podem ser criados diversos LoggerContext para uma mesma aplicação.
Como dissemos na seção anterior, cada LoggerContext tem um Configuration associado e vice-versa. O Configuration irá conter todos os Appenders, Filters, LoggerConfigs e contém também uma referência para o objeto StrSubstitutor. Lembra que falamos que uma das vantagens de utilizar o Log4j 2 é que ele não perde eventos de log enquanto uma reconfiguração está sendo carregada ? É aqui que este ponto entra, pois no momento deste reload são criados 2 Configurations (um novo e um antigo), sendo que o antigo continua monitorando os logs até que todos os Loggers sejam redirecionados do Configuration antigo para o novo, assim garantimos que nada será perdido neste tempo.
Como dito anteriormente, Loggers são criados e capturados através do LogManager.getLogger(). Este não executa ações diretas, apenas guarda as mensagens para que sejam enviados ao seu destino pelos Appenders, este possui um nome e está associado a um LoggerConfig, além de estender o AbstractLogger e implementar seus métodos requeridos. Quando a configuração dos Loggers são alteradas pode ser associado com um LoggerConfig diferente afim de comportar sua nova configuração.
Para ficar mais simples de entender o funcionamento deste tipo de objeto, vejamos um exemplo na Listagem 1 de como capturar o mesmo.
Listagem 1. Capturando Logger do Sistema
Logger x = LogManager.getLogger("wombat");
Logger y = LogManager.getLogger("wombat");Tanto o objeto x como o objeto y fazem referência ao mesmo Logger chamado “wombat”. O nome do Logger é case-sensitive, ou seja, “wombat” é diferente de “Wombat”. Um padrão interessante adotado para nomeação de Loggers é usar o nome qualificado na classe, como no exemplo da Listagem 2.
Listagem 2. Nomeando Logger
Logger x = LogManager.getLogger(MinhaClasse.class.getName());O LoggerConfig é criado quando os Loggers são declarados na configuração do sistema de log. Este contém vários Filters que permitem que os eventos passem por um filtro antes de serem entregues aos Appenders. Vamos ver um pouco mais sobre esse tão importante artefato da arquitetura do Log4j 2.
Nível de Log (Log Levels)
Todo LoggerConfig é associado a um nível de log, são eles: TRACE, DEBUG, INFO, WARN, ERROR e FATAL. Para entender melhor como funciona o relacionamento do Logger e do LoggerConfig e os seus níveis veremos abaixo sete tabelas que irão descrever o funcionamento de forma clara e objetiva.
|
Nome do Logger |
LoggerConfig associado |
Nível do LoggerConfig |
Nível do Logger |
|
root |
root |
DEBUG |
DEBUG |
|
X |
root |
DEBUG |
DEBUG |
|
X.Y |
root |
DEBUG |
DEBUG |
|
X.Y.Z |
root |
DEBUG |
DEBUG |
Tabela 1. Configuração do LoggerConfig
Na Tabela 1, na primeira linha, o LoggerConfig root é configurado com o nível DEBUG e o Logger root usa este mesmo nível, ou seja, herda este nível. Os outros Logger's (X, X.Y e X.Y.Z) usam o LoggerConfig root previamente configurado na linha 1.
|
Nome do Logger |
LoggerConfig associado |
Nível do LoggerConfig |
Nível do Logger |
|
Root |
Root |
DEBUG |
DEBUG |
|
X |
X |
ERROR |
ERROR |
|
X.Y |
X.Y |
INFO |
INFO |
|
X.Y.Z |
X.Y.Z |
WARN |
WARN |
Tabela 2. Níveis do Logger
Na Tabela 2 cada Logger tem um LoggerConfig associado para ele, ou seja, o Logger X usa o LoggerConfig X, o Logger X.Y usa o LoggerConfig X.Y e assim por diante, assim como o nível do LoggerConfig também é usado pelo nível do Logger, ou seja, o nível ERROR no LoggerConfig X é herdado para o Logger X que também fica como ERROR.
|
Nome do Logger |
LoggerConfig associado |
Nível do LoggerConfig |
Nível do Logger |
|
Root |
Root |
DEBUG |
DEBUG |
|
X |
X |
ERROR |
ERROR |
|
X.Y |
X |
ERROR |
ERROR |
|
X.Y.Z |
X.Y.Z |
WARN |
WARN |
Tabela 3. Modificações dos Níveis do Logger
Na Tabela 3 as coisas ficam um pouco mais interessantes. Os Logger's Root, X e X.Y.Z tem seus próprios LoggerConfig's com o mesmo nome, por outro lado o Logger X.Y não tem um LoggerConfig de nome X.Y, sendo assim ele usa o LoggerConfig com nome de “pacote” superior ao seu, ou seja, antes do pacote “X.Y” temos o pacote “X”, sendo assim o LoggerConfig usado pelo Logger X.Y será o X.
|
Nome do Logger |
LoggerConfig associado |
Nível do LoggerConfig |
Nível do Logger |
|
Root |
Root |
DEBUG |
DEBUG |
|
X |
X |
ERROR |
ERROR |
|
X.Y |
X |
ERROR |
ERROR |
|
X.Y.Z |
X |
ERROR |
ERROR |
Tabela 4. Mudanças na Tabela 3
A ideia da Tabela 4 é quase a mesma mostrada na Tabela 3. Os Logger's de nome Root e X possuem seus LoggerConfig's próprios, por outro lado o Logger X.Y e X.Y.Z usam o LoggerConfig de pacote superior já que não possuem um LoggerConfig próprio, sendo assim eles usam as configurações do LoggerConfig X, perceba que o nível de Log para eles fica como ERROR, igual ao Logger Root e X.
|
Nome do Logger |
LoggerConfig associado |
Nível do LoggerConfig |
Nível do Logger |
|
Root |
Root |
DEBUG |
DEBUG |
|
X |
X |
ERROR |
ERROR |
|
X.Y |
X.Y |
INFO |
INFO |
|
X.YZ |
X |
ERROR |
ERROR |
Tabela 5. Novos Loggers
Na Tabela 5 os Logger's Root, X e X.Y possuem seus próprios LoggerConfig's como você já deve ter notado. Mas temos um caso especial, o Logger X.YZ. Você pode se perguntar porque o Logger X.YZ usou o LoggerConfig X e não o X.Y ? Acontece que, pensando na organização em pacotes, você não pode tirar apenas o “Z” para achar um LoggerConfig de nome similar, você deve tirar o “YZ”, restando apenas o “X”. Ficou complicado? Vamos exemplificar como se fosse em Java.
Imagine que o Logger X.YZ seja o Logger com.minhaclasseZ, e o LoggerConfig X.Y seja o LogerConfig com.minhaclasse. Sabemos que minhaclasseZ é diferente de minhaclasse, sendo assim o LoggerConfig com nomenclatura superior ao com.minhaclasseZ seria o “com” = “X”. A dica é sempre pensar em termos de pacote e ficará mais fácil a compreensão.
|
Nome do Logger |
LoggerConfig associado |
Nível do LoggerConfig |
Nível do Logger |
|
Root |
Root |
DEBUG |
DEBUG |
|
X |
X |
ERROR |
ERROR |
|
X.Y |
X.Y |
|
ERROR |
|
X.Y.Z |
X.Y |
|
ERROR |
Tabela 6. Mudanças no Logger X.Y
Na Tabela 6 temos um caso novo, perceba que o LoggerConfig X.Y não tem nenhum nível associado a ele. Neste caso o LoggerConfig X.Y usa o mesmo nível do LoggerConfig superior, que neste caso é o LoggerConfig X, que por sua vez possuí o nível ERROR. Partindo desse princípio, o Logger X.Y obtém para si o nível ERROR herdado do LoggerConfig X, e o mesmo ocorre com o Logger X.Y.Z, que também usa o LoggerConfig X.Y sem nível.
No começo pode parecer um pouco complexo a nova hierarquia usada pelo Log4j 2, mas lendo e relendo o artigo várias vezes você com certeza assimilará esta nova arquitetura. Além disso, estes conceitos são primordiais antes de iniciar o uso prático do Log4j 2.
Vamos ver nossa última tabela relacionada ao LoggerConfig, onde esta tabela demonstrará todos os possíveis níveis que podem ser usados.
|
Nível do Evento |
Nível do LoggerConfig |
||||||
|
|
TRACE |
DEBUG |
INFO |
WARN |
ERROR |
FATAL |
OFF |
|
ALL |
SIM |
SIM |
SIM |
SIM |
SIM |
SIM |
SIM |
|
TRACE |
SIM |
NÃO |
NÃO |
NÃO |
NÃO |
NÃO |
NÃO |
|
DEBUG |
SIM |
SIM |
NÃO |
NÃO |
NÃO |
NÃO |
NÃO |
|
INFO |
SIM |
SIM |
SIM |
NÃO |
NÃO |
NÃO |
NÃO |
|
WARN |
SIM |
SIM |
SIM |
SIM |
NÃO |
NÃO |
NÃO |
|
ERROR |
SIM |
SIM |
SIM |
SIM |
SIM |
NÃO |
NÃO |
|
FATAL |
SIM |
SIM |
SIM |
SIM |
SIM |
SIM |
NÃO |
|
OFF |
NÃO |
NÃO |
NÃO |
NÃO |
NÃO |
NÃO |
NÃO |
Tabela 7. Níveis do evento Logger
A Tabela 7 é muito simples de ser compreendida, vejamos a primeira linha onde temos o nível de evento ALL, para este nível todos os níveis do LoggerConfig são habilitados, ou seja, um LoggerConfig com ALL irá possuir: TRACE, DEBUG, INFO, WARN, ERROR, FATAL e OFF.
Filtros podem ser aplicados em alguns locais, vejamos:
Assim como nos Firewalls, os filtros podem retornar 3 resultados possíveis: Accept, Deny ou Neutral.
Mesmo que um filtro aceite um evento (Accept), não significa que ele será logado, isso porque pode ocorrer de o Filtro antes do LoggerConfig aceitar, mas o filtro depois do LoggerConfig negar (Deny), nesse caso ele não chega a ser logado.
O Appender é o responsável por de fato “logar” o evento, ou seja, a sua mensagem “Funcionou neste ponto” irá ser registrada em algum local pelo Appender, este local pode ser: Console, Arquivo, Socket Servers, JMS e etc.
Um Appender é associado ao um LoggerConfig, usando o método “addLoggerAppender” você consegue adicionar um Appender a um LoggerConfig de mesmo nome do Logger, caso este LoggerConfig não exista então será criado um automaticamente.
Por fim e não menos importante, o Layout nos ajuda a formatar a saída que o Appender é responsável por gerar, sendo assim você deve ter percebido que o Layout está diretamente associado a um Appender.
Este artigo teve como principal foco introduzir as teorias a respeito da arquitetura e inovações propostas pelo Log4j 2. Feito isso é possível entender as diferenças entre ambas as versões, que são muitas, e possivelmente começar a aventurar-se de fato nas configurações e uso propriamente dito desta framework. Não entramos em detalhes minuciosos de cada uma das classes propostas nesta arquitetura, pois não foi o foco deste artigo em nenhum momento.
De fato alguns podem achar um assunto chato e tedioso, mas é essencial para o entendimento de futuras aplicações. Bons profissionais não são construídos apenas de prática e experiência mas sim de um forte embasamento teórico onde este pode firmar-se.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.






