
SQL Server: Boas práticas com chaves
Este artigo descreve boas práticas para a criação de Primary Keys e Unique Keys, tendo o SQL Server como foco.
Fique por dentro
Este
artigo descreve boas práticas para a criação de Primary Keys e Unique Keys, tendo
o SQL Server como foco. Através de exemplos simples, serão demonstradas algumas
recomendações na criação das mesmas com o objetivo de atender aos requisitos de
negócio dos sistemas, além de criar uma base de fácil manutenção.Uma boa modelagem de Primary Keys e Unique Keys no SQL Server é recomendada para qualquer projeto que envolva o uso deste SGBD por garantir um banco de dados de fácil manutenção, tanto por parte do desenvolvedor como pelo DBA.
A cada dia as empresas se tornam mais dependentes das informações que estão armazenadas em seus sistemas gerenciadores de banco de dados para atendimento das demandas operacionais, táticas e estratégicas. Estas informações são acessadas das mais diversas formas (planilhas eletrônicas ou sistemas de informação mais complexos). Por esse motivo os dados precisam ser entregues para os usuários de modo eficiente (desempenho) e eficaz (informações corretas).
O SQL Server possui algumas recomendações que podem ser utilizadas para que o banco de dados alcance um bom desempenho, além de fácil manutenibilidade. Algumas dessas recomendações recaem sobre a forma de criação de Primary Keys e Unique Keys.
Neste contexto, serão apresentadas neste artigo algumas dessas boas práticas, como a utilização ou não de Surrogate Keys ao invés de um ou mais campos de negócio da tabela para ser a Primary Key e o uso ou não de Unique Keys.
Estrutura de índices do SQL Server
A estrutura que o SQL Server utiliza para construir e manter índices é conhecida como B-tree, ou árvore balanceada, conforme mostra a Figura 1.
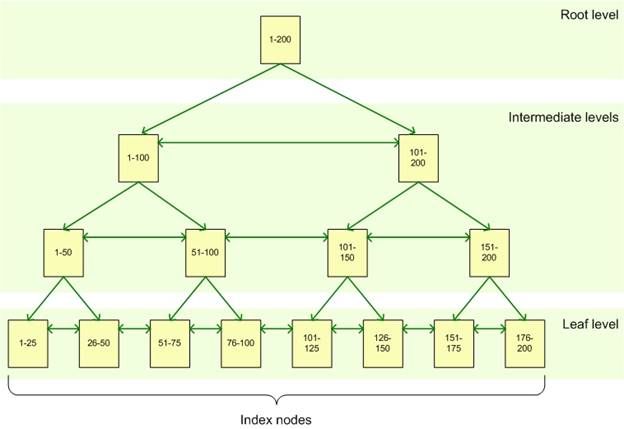
Figura 1. Estrutura utilizada pelo SQL Server
A B-tree é constituída de um nó raiz (root) que contém uma única página de dados, uma ou mais páginas opcionais de nível intermediário (Intermediate Level) e uma ou mais páginas opcionais de nível de folha (Leaf Level). O conceito da B-tree informa que a mesma é sempre simétrica, ou seja, sempre existirão números de páginas iguais à direita e à esquerda de cada nível. Essa estrutura permite ao SQL Server encontrar uma ou mais linhas de registro com valores chaves de maneira rápida e eficiente.
Após entender como é a estrutura de índices do SQL Server, veremos os dois tipos de índices que uma tabela pode conter: Clustered e Nonclustered.
Índices Clustered
Pode-se definir um índice utilizando uma ou mais colunas da tabela, sendo que essas colunas recebem o nome de chave do índice ou index key. Contudo, existem as seguintes restrições para a criação do índice:
· Um índice só pode ter no máximo 16 colunas;
· O tamanho máximo da chave do índice é 900 bytes.
Ao se criar um índice clustered, as colunas que fazem uso do mesmo recebem o nome de “Chave do Índice Clustered” ou “Clustering Key” – ver BOX 1.
Um índice clustered possui dentre suas características uma especial que é organizar os dados na tabela de acordo com o valor da Clustering Key. Isso significa que se possuirmos uma tabela que possua dois campos (Código, Nome) e criarmos um índice Clustered utilizando o campo Código, os dados nesta tabela serão ordenados por este campo.
Como ocorre essa ordenação dos dados de acordo com o índice Clustered, isso impossibilita de haver mais de um índice deste tipo para uma mesma tabela, já que não há como ordenar fisicamente uma tabela de mais de uma forma.
BOX 1. Tabela Heap e Tabela Clustered (“Clusterizada”)
Quando uma tabela possui um índice clustered, ela é chamada de Tabela Clustered (“Clusterizada”). Caso a tabela não possua este tipo de índice, os dados não são armazenados de forma ordenada e a tabela recebe o nome de Tabela Heap."
[...] continue lendo...
Artigos relacionados
-
Artigo
-
Artigo
-
Artigo
-
Artigo
-
Artigo