
Persistindo Objetos com Java, Hibernate e PostgreSQL
Como programador Java, muito provavelmente, em algum momento haverá a necessidade de guardar e recuperar as informações dos objetos em algum local...
Como programador Java, muito provavelmente, em algum momento haverá a necessidade de guardar e recuperar as informações dos objetos em algum local. Na maioria dos casos essas informações, tanto de objetos quanto de componentes, serão armazenados em um banco de dados relacional.
Para usar um banco de dados relacional com o intuito de manter os objetos armazenados, um programador poderia perder muito tempo no ajuste do modelo OO (Orientado a Objeto), para o modelo Relacional em tabelas. Esse processo pode ser demorado, pois depende de alguns fatores incluindo os seguintes:
- Quanto o esquema relacional está próximo do modelo OO;
- O esquema representa a aplicação;
- O esquema é padrão, ou seja, possui chaves primárias;
- Qual o grau de normalização se encontra o esquema;
- Quanto o esquema influência o modelo OO e a interface com o usuário( e vice versa);
Alguns puristas do paradigma orientado a objetos poderiam argumentar que a modelagem do domínio do negócio não deveria ser influenciado por detalhes de implementação tais como, onde o objeto deveria está armazenado se não estiver na memória. Por outro lado, um modelador de banco de dados poderia afirmar que o modelo de dados deveria perdurar a vida da aplicação por muito tempo e que o design do sistema deveria ser concentrado na eficiência de armazenamento e acesso aos dados.
Ambas as visões tem suas particularidades, mais quando pensamos no desenvolvimento de um sistema, devemos primar pela agilidade e produtividade. Dessa forma, uma excelente saída para esse conflito de idéias, é colocar em ação as melhores práticas dos modeladores de objetos e dos modeladores de banco de dados. Assim asseguramos um modelo bem definido do domínio do problema além de manter a integridade, reusabilidade, e um eficiente uso dos dados.
Object-relational mapping(ORM) é o nome dado para tecnologias, ferramentas e técnicas usadas para ligar os objetos aos banco de dados relacional. Isso significa que estaremos construindo uma camada extra para persistir os objetos no repositório, ou seja, criaremos uma camada de persistência. Este modelo nos possibilita criar mapeamentos dos objetos entidade para seus respectivos dados e relacionamentos nos banco de dados. Esta geração de ferramentas gera todo o SQL necessário para recuperar, armazenar, atualizar, deletar as informações para cada objeto mapeado.
O Hibernate é uma excelente ferramenta open source que possibilita essa forma de trabalho, ou seja, ele é uma ferramenta que possibilita a persistência transparente de objetos Java. Persistência transparente, dita anteriormente, quer dizer que os objetos não tem nenhum código que expõe a habilidade de ser persistido no repositório, ao contrário de como acontece com os Entity Beans.
No Hibernate, o mapeamento entre os objetos e as tabelas pode ser implementado através de arquivos XML, código Java ou via JSR-220 Persistence Annotation. O sucesso do Hibernate está centralizado na simplicidade, onde o coração de toda a interação entre o código e o banco de dados utiliza o Hibernate Session.
Abaixo segue um esquema de como o Hibernate trabalha:
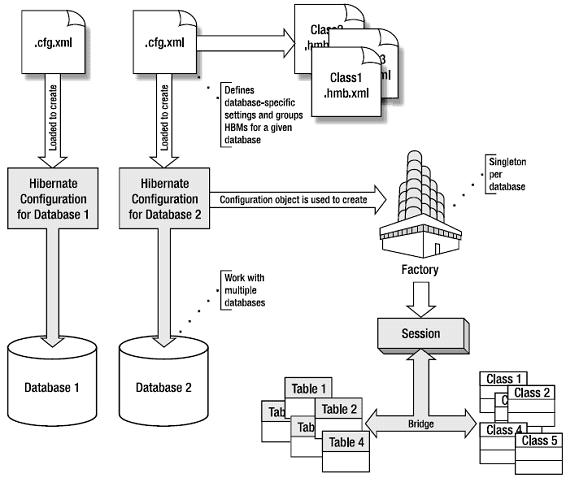
O Hibernate Session incorpora o conceito de serviço(ou gerenciador de persistência – Persistence Manager) que pode ser usado para consultas e executar operações de inserção, atualização e remoção na instancia de uma classe mapeada pelo Hibernate. Em ferramentas do tipo ORM, executa-se todas essas interações na semântica orientada a objetos, ou seja, não se reportando as tabelas e colunas, mas sim a classes e propriedades dos objetos Java.
Como o Hibernate dá a possibilidade de conectar-se a vários banco de dados, é necessário fornecer as informações requeridas para conectar ao banco de dados, assim como cada classe deverá ser mapeada para cada banco de dados. Cada uma dessas configurações e mapeamento de classes serão compiladas e armazenadas pelo SessionFactory. O SessionFactory deverá ser instanciado apenas uma vez.
Cada SessionFactory é configurado para uma determinada plataforma de banco de dados através dos Hibernate dialects. O Hibernate possui uma imensa variedade de dialects, desde TimesTenDialect (Alguém por acaso conhece esse banco de dados?) até os mais tradicionais como PostgreSQLDialect e OracleDialect. Abaixo segue a arquitetura de dialects disponibilizados pela Hibernate. Cada dialect está disponível no pacote org.hibernate.dialect.
O Hibernate especifica como cada objeto será retornado ou armazenado no banco de dados através de um arquivo de configuração XML. Os mapeamentos são lidos ao iniciar a aplicação e armazenados em cache numa SessionFactory. Cada mapeamento especifica uma variedade de parâmetros referentes ao ciclo de vida das instâncias dos mapeamentos, tais como:
- Chave Primária
- Mapeamento dos campos dos objetos com seus respectivas colunas nas tabelas.
- Associações / Coleções
- Configurações sobre cache
- Chamadas a Store Procedores, filtros, consultas parametrizadas, entre outras.
Tendo o Hibernate iniciado sem problemas e com os objetos mapeados, devemos estar cientes dos estados de cada objeto instanciado. Há três estados possíveis para um objeto. O entendimento destes estados e as ações que os modificam, serão de muita importância quando se depararem com algum problema. Não entrarei mais a fundo sobre esse aspecto mas deixarei uma visão superior sobre os estados e as ações que os precedem com a figura seguinte:
- Transient : Objeto em memória porém não foi salvo ainda;
- Persistent : Objeto já salvo porém em cache no SessionFactory mas pode ser que ainda não esteja no banco de dados;
- Detached : Objeto já persistido no banco de dados;
Até agora vimos muitos conceitos sobre persistência, particularidades do Hibernate, entre outros detalhes, mas creio que com um bom embasamento sobre o estamos fazendo fica mais claro e com certeza evitamos alguns problemas que evitarão algumas horas de suporte e manutenção. Creio que com esses detalhes poderemos entrar no código agora. Mas antes precisaremos configurar o ambiente onde iremos trabalhar.
Primeiro será necessário obter o Hibernate em www.hibernate.org. A última vez na qual tive a oportunidade de acessar o sítio do projeto, a versão mais atual estava em 3.X.
Precisaremos também de um banco de dados, que ficará a critério da familiaridade. Nesse artigo estarei utilizando o PostgreSQL que já é nativo do Linux Fedora 5, ambiente no qual estou desenvolvendo o presente artigo.
Estando de posse do banco e do Hibernate, deve-se configurar o ambiente no qual se irá trabalhar, os exemplos apresentados mais adiante foram escritos no Eclipse no qual tive que adicionar algumas bibliotecas, a maioria disponibilizados pelo próprio Hibernate, seguem abaixo as respectivas arquivos e suas origens:
- jta-spec1_0_1.jar - Hibernate
- asm.jar - Hibernate
- cglib-2.1.3.jar - Hibernate
- commons-logging-1.0.4.jar – PostgreSQL
- dom4j-1.6.1.jar - Hibernate
- ehcache-1.2.jar – Hibernate
- hibernate3.jar - Hibernate
- commons-collections.jar – PostgreSQL
- postgresql-8.0-315.jdbc3.jar – PostgreSQL
Após adicionar as bibliotecas a IDE, ou ao ClassPath, verifique se o sistema de gerenciamento do banco de dados(SGBD) está instalado e configurado corretamente( Não irei entrar em detalhes sobre esse processo, por não ser o foco desse artigo).
A seguir está o código da classe endereco, onde encontramos apenas seus atributos e seus respectivos gets e sets, sobre a qual executaremos as tarefas de Salvar, Recuperar, Excluir e Atualizar os objetos no banco:
public class endereco {
private Integer codigo;
private String rua;
private String estado;
private String cep;
private String cidade;
public String getCep() {
return cep;
}
public void setCep(String cep) {
this.cep = cep;
}
public String getCidade() {
return cidade;
}
public void setCidade(String cidade) {
this.cidade = cidade;
}
public Integer getCodigo() {
return codigo;
}
public void setCodigo(Integer codigo) {
this.codigo = codigo;
}
public String getEstado() {
return estado;
}
public void setEstado(String estado) {
this.estado = estado;
}
public String getRua() {
return rua;
}
public void setRua(String rua) {
this.rua = rua;
}
}
Como mapear esse objeto para o banco? É um processo relativamente fácil, basta criar um arquivo com a extensão nomeMapeamento.hbm.xml, neste caso colocarei o nome mapEndereco.hbm.xml com o seguinte conteúdo:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping
package="localizacao">
<class name="endereco">
<id name="codigo" column="id" type="integer"/>
<property name="rua" />
<property name="estado" />
<property name="cep" />
<property name="cidade" />
</class>
</hibernate-mapping>
Detalhando o arquivo hbm.xml temos algumas características que gostaria de frisar antes de prosseguir. Em primeiro lugar temos o parâmetro package onde pode se encontrar a classe alvo da persistência. O elemento class descreve o nome da classe que deverá ser mapeada e se caso não estiver colocado o atributo table o Hibernate considerará que o nome da tabela, em questão, terá o mesmo nome da classe. O elemento id denota o atributo que deverá funcionar como chave primária.
Segue abaixo um script para a criação da tabela no PostgreSQL. Saliento que, para o exemplo funcionar perfeitamente, os atributos da tabela deverão ser idênticos aos elementos mapeados da classe. Considere que para cada campo mapeado deveremos ter um correspondente na tabela do banco, porém isso não quer dizer que deverão ter os mesmo nomes, mas por uma questão de praticidade manteremos os mesmos nomes tanto no banco quanto na classe. Caso houver a necessidade de ter nomes diferentes, apenas será necessário explicitar o campo na tabela para cada propriedade.
CREATETABLE Endereco (
id INTEGER NOT NULL,
rua VARCHAR(50) NOT NULL,
estado VARCHAR(2) NULL,
cep VARCHAR(10) NULL,
cidade VARCHAR(50) NULL,
CONSTRAINT XPKTanques PRIMARY KEY(id)
);
Estamos agora, com toda a estrutura necessária para realizar algumas tarefas corriqueiras dentro de um ambiente cliente-servidor como salvar, recuperar, apagar e atualizar registros no banco de dados sem ao menos uma linha de código em SQL.
Como primeiro exemplo teremos uma classe com um único método, neste caso o main, que irá realizar todas as tarefas, desde configurar os parâmetros referentes à conexão com o banco de dados até salvar os objetos.
Para se configurar o Hibernate com a possibilidade de realizar as tarefas mencionadas, precisamos, através do método setProperty da classe org.hibernate.cfg.Configuration, informar qual será o Banco, o driver de conexão, o endereço para o banco, usuário e senha. Há outras configurações interessantes, onde podemos “dizer” ao Hibernate que após a transação, seja exibido SQL executado. Segue abaixo o trecho de código referente a tais configurações. Uma outra propriedade que deve ser informada é a classe do objeto que será mapeada, para que o Hibernate localize o arquivo de mapeamento da classe desejada através do arquivo Classe.hbm.xml:
...
Configuration config = new Configuration().
setProperty("hibernate.dialect", "org.hibernate.dialect.PostgreSQLDialect").
setProperty("hibernate.connection.driver_class", "org.postgresql.Driver").
setProperty("hibernate.connection.url", "jdbc:postgresql://www.sitio.com.br:5432/Endereco").
setProperty("hibernate.connection.username", "postgres").
setProperty("hibernate.connection.password", "123").
setProperty("hibernate.show_sql", "true");
config.addClass(Classe.class);
SessionFactory factory = Config.buildSessionFactory();
...
Para criar um objeto e salva-lo no banco, temos que passar pelos passos seguintes:
- Criar e informar os dados referentes aos atributos do objeto.
- Criar uma Session através do SessionFactory.
- Uma Hibernate Transaction deverá ser iniciada dentro da Session.
- O objeto deverá ser salvo através do método session.persist(Objeto).
- A transação deverá ser “comitada”.
- E por fim a Session encerrada.
Segue abaixo o trecho de código referente a estes passos:
...
Objecto obj = new Objecto();
...
Session session = null;
Transaction tx = null;
try {
session = factory.openSession();
tx = session.beginTransaction();
session.persist(obj);
tx.commit();
} catch (Exception e) {
if (tx != null)
tx.rollback();
System.out.println("Transação falhou : ");
e.printStackTrace();
} finally {
session.close();
}
...
No entanto para ler um objeto o Hibernate Session oferece dois métodos com base em chave primária, load e get. O load admite que o objeto está persistido, porém se não conseguir recuperar o objeto, é lançada a exceção do tipo org.hibernate.ObjectNotFoundException. Já o get, nos casos em que o objeto procurado não for encontrado, será retornado null, dessa forma o programa terá que trata-lo.
Exemplos:
endereco end = (endereco)session.load(endereco.class, 1);
enderecoend = (endereco)session.get(endereco.class, 1);
...
A Session possui muitos outros métodos para interagir com o banco, segue abaixo mais alguns exemplos:
session.update(...);
session.delete(...);
session.save(...);
session.saveOrUpdate(...);
Como um exemplo funcional, escrevi o código abaixo para demonstrar como poderíamos trabalhar utilizando uma camada de persistência. Percebam que não foram escritas uma única linha de código SQL.
import org.hibernate.*;
import org.hibernate.cfg.*;
public class TesteHB {
public static void main(String[] args) {
endereco end = new endereco();
SessionFactory factory = factory(end);
end.setCodigo(1);
end.setRua("Av. Getúlio Vargas");
end.setCidade("Feira de Santana");
end.setEstado("BA");
end.setCep("4419999");
Session session = null;
Transaction tx = null;
try {
session = factory.openSession();
tx = session.beginTransaction();
session.persist(end);
tx.commit();
} catch (Exception e) {
if (tx != null) tx.rollback();
System.out.println("Transação falhou : ");
e.printStackTrace();
} finally {
session.close();
}
}
private static SessionFactory factory(Object classe){
Configuration config = new Configuration().
setProperty("hibernate.dialect", "org.hibernate.dialect.PostgreSQLDialect").
setProperty("hibernate.connection.driver_class", "org.postgresql.Driver").
setProperty("hibernate.connection.url",
"jdbc:postgresql://www.sitio.com.br:5432/Endereco").
setProperty("hibernate.connection.username", "postgres").
setProperty("hibernate.connection.password", "123").
setProperty("hibernate.show_sql", "true");
config.addClass(((endereco)classe).getClass());
return config.buildSessionFactory();
}
}
Como podemos ver, a dificuldade maior foi na montagem da estrutura (Configurar o banco, montar os mapeamentos, entender como o Hibernate trabalha), depois de feito o trabalho pesado, temos um código muito mais limpo, escalonável, maior reuso de código, sistema com n-camadas, maior manutenibilidade entre outros pontos positivos. Será que alguém poderia imaginar a extinção dos DBAs?. Creio que não, mas com certeza, programadores e/ou analistas serão muito mais independentes. Não foi contextualizado no texto mas gostaria de salientar que se caso queiram, o Hibernate possibilita que a partir do modelo das classes poderíamos montar todo mapeamento automaticamente e vice-versa. Para isso seria necessário usar uma ferramenta apropriada.
Espero que tenham gostado do que foi exposto aqui nesse artigo, e qualquer dúvida, crítica, elogios, podem entrar em contato. Até a próxima.
Referências
- java.sun.com
- www.hibernate.org
- www.postgresql.org
- BODEM, Brian Sam. Beginning POJOs: From Novice to Professional. Editora Appress, 2006.
Artigos relacionados
-
Artigo
-
Artigo
-
Artigo
-
Artigo
-
Artigo