
Particionamento de tabelas no SQL Server 2008 R2
Veja neste artigo como implementar de forma pratica e bem simples o particionamento de tabelas no SQL Server 2008 R2.
O uso de particionamento de tabelas se torna útil em grandes ambientes de banco de dados, onde existem a necessidade de grande acesso aos dados, não somente para esta causa, mas também para inúmeras funcionalidades dentro do banco, como: backup, rápido acesso a dados e dados históricos.
Para que seja necessário implementar particionamento de tabelas é aconselhável ter conhecimento sobre filegroups, aqui mesmo no portal DevMedia encontrei um ótimo artigo sobre o assunto: Trabalhando com Filegroups no Sql Server.
É bom lembrar que Particionamento de Tabelas está disponível somente nas seguintes edições do SQL Server 2008 R2: Enterprise, Datacenter e Developer.
Existem dois tipos de Particionamento de Tabelas:
Particionamento Horizontal: que separa os registros e é aplicado em uma coluna da tabela.
Particionamento Vertical: que separa as colunas e é aplicado na tabela.
Obs: é possível juntar os dois tipos.
Antes iniciar a criação de Particionamento de Tabelas, vamos criar um banco de dados e criar alguns filesgroups. A figura 1, mostra a criação do banco:
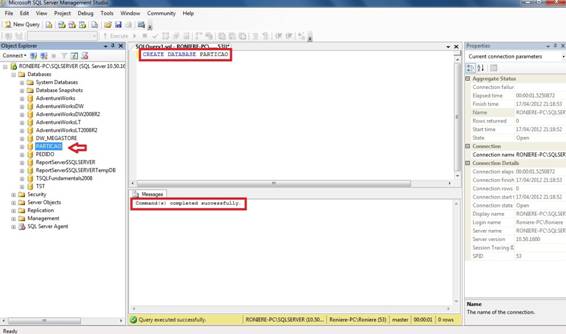
Figura 1. Janela do Management Studio, criando um banco de dados.
Nosso próximo passo, criar os filegroups do banco, clique com o botão direito do mouse sobre o banco, clique em PROPERTIES, aparecerá a janela como mostra a figura 2:
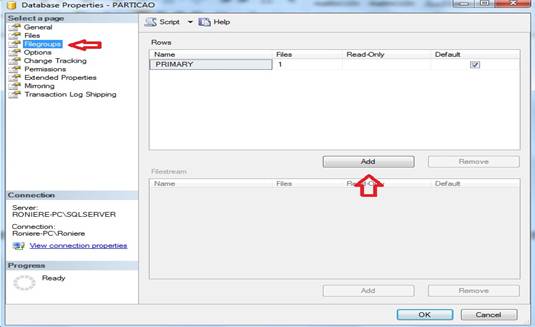
Figura 2. Janela Database Properties, opção Filegroups.
Neste momento vamos adicionar filegroups no banco de dados, aperte o botão ADD, no meu caso, adicionei quatro filegroup com os seguintes nomes: FG1, FG2, FG3, FG4, como mostra a figura 3 :
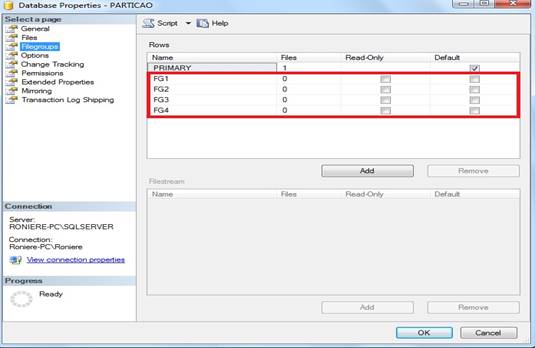
Figura 3. Janela Database Properties, com os Filegroups criados.
Se você achar melhor criar o banco de dados em T-SQL, mas antes vá até a Unidade C e crie uma pasta com o nome de “particao”, em seguida utilize o código:
Listagem 1. Criação do banco de dados com os filegroups.
CREATE DATABASE PARTICAO
ON
PRIMARY
(
NAME = BANCO_PRI,
FILENAME = 'C:\particao\BANCO_PRI.mdf',
SIZE = 5MB
),
FILEGROUP FG1
(
NAME = FG1,
FILENAME = 'C:\particao\FG1.ndf',
SIZE = 5MB
),
FILEGROUP FG2
(
NAME = FG2,
FILENAME = 'C:\particao\FG2.ndf',
SIZE = 5MB
),
FILEGROUP FG3
(
NAME = FG3,
FILENAME = 'C:\particao\FG3.ndf',
SIZE = 5MB
),
FILEGROUP FG4
(
NAME = FG4,
FILENAME = 'C:\particao\FG4.ndf',
SIZE = 5MB
)
LOG ON
(
NAME = LOG,
FILENAME = 'C:\particao\LOG.ldf',
SIZE = 5MB
)
Veja como os arquivos ficam na pasta, para melhor entendimento, como mostra a figura 4:
Figura 4. Imagem dos arquivos criados com o código mostrado anteriormente.
A partir deste momento, vamos iniciar o Particionamento de Tabelas, mas devemos considerar pontos importantes para implementar, o que realmente necessite de particionamento, veja alguns casos:
- tabelas com grandes volumes de dados.
- necessidade de dados para histórico e analise.
- melhoria de desempenho de consultas.
- importação e exportação de grandes volumes de dados.
Outras informação importantes, o que você deve fazer antes de implementar partições:
- analisar o crescimento dos dados.
- estudo das consultas mais utilizadas.
- verificar disponibilidade de discos rígidos para armazenamento dos arquivos de dados
- criar ou configurar os arquivos de dados de grupos de arquivos (Filegroups).
- definir quais são as colunas e os critérios do particionamento.
- implementar o particionamento (criando a função e o esquema de partição).
Função de Partição (Partition Function)
É usada para especificar como uma tabela ou índice é particionado, para criar uma Partition Function, você especifica o numero de partições a coluna de particionamento e o intervalo de valores da coluna da partição para cada partição.
Informações importantes:
Função de partição não trabalha com alguns tipos de dados: [N]TEXT, [N]VARCHAR (MAX), VARBINARY (MAX), IMAGE E XML
Obs: na função deve-se informar em qual partição os dados com valores IGUAIS aos valores limites devem ser armazenados.
O valor limite pode ser armazenado à esquerda (LEFT) ou à direita (RIGHT)
A sintaxe do CREATE PARTITION FUNCTION
Listagem 2. Exemplo de criação de função de partição
CREATE PARTITION FUNCTION nome_funcao (tipo de dados)
AS RANGE posicao FOR VALUES (Valor 1, Valor 2)
Esquema de Partição (Partition Scheme)
É um esquema que é utilizado para mapear as partições feitas por uma partition function em conjunto com grupos de arquivos (Filegroups).
Importante:
um partition schema só pode usar uma partition function, porem uma partition function pode participar de mais de uma partition schema.
A sintaxe do CREATE PARTITION SCHEME
Listagem 3. Exemplo de criação esquema de partição
CREATE PARTITION SCHEME nome_do_esquema AS PARTITION nome_funcao TO ([FG1],[FG2]…)
Alguns comandos importantes:
Para manipular partições é necessário saber utilizar essas três funções:
SPLIT: Divide uma partição em duas.
MERGE: Junta duas partições em uma.
SWITCH: Move registros entre duas tabelas, modificando apenas os ponteiros dos dados.
Depois destas informações teóricas, vamos iniciar um pouco de pratica, para entender melhor, neste primeiro momento vamos criar uma PARTITION FUNCTION e uma PARTITION SCHEMA. Logo abaixo segue um exemplo de como criar uma função de partição:
Listagem 4. Criação de uma função de partição
CREATE PARTITION FUNCTION func_particao(INT) AS RANGE LEFT FOR VALUES (1000, 2000)
GO
Agora veja no Management Studio o função criada, vá a até ao banco PARTICAO, expanda a pasta STORAGE e em seguida expanda PARTITION FUNCTION, como mostra a figura 5:
Figura 5. Janela do Management Studio, Object Explorer com a função de partição criada.
Para ver com mais detalhes essas informações, digite o código a seguir:
Listagem 5. Código para verificar os detalhes da função de partição.
SELECT * FROM sys.partition_range_values
Veja o resultado na figura 6:
Figura 6. Janela do Management Studio com o resultado do SELECT.
Agora veja como criar uma PARTITION SCHEMA, veja o exemplo e em seguida execute:
Listagem 6. Criação de um esquema de partição.
CREATE PARTITION SCHEME esquema_particao AS PARTITION func_particao
TO ([FG1, [FG2], [FG3])
Novamente veja no Management Studio o função criada, vá a até ao banco PARTICAO, expanda a pasta STORAGE e em seguida expanda PARTITION SCHEME, como mostra a figura 7:
Figura 7. Janela do Management Studio, Object Explorer com a função de esquema criada.
Utilize o código abaixo para verificar informações detalhadas:
Listagem 7. Código para verificar os detalhes do esquema de partição.
SELECT * FROM sys.partition_schemes
Veja o resultado da consulta na figura 8:
Figura 8. Janela do Management Studio com o resultado do SELECT.
Agora vamos criar uma tabela simples que faça parte do esquema de partição, veja o código abaixo:
Listagem 8. Criando a tabela no esquema de partição
CREATE TABLE tabela1
(
codigo INT PRIMARY KEY,
valor CHAR(1000) DEFAULT 'aaaa'
)
ON esquema_particao(codigo)
Neste momento vamos inserir um código capaz de popular a tabela com 150 registros, em seguida mostrarei os outros códigos:
Listagem 9. Código para popular a tabela.
SET NOCOUNT ON
DECLARE @a INT
SET @a = 10
WHILE @a <= 3000
BEGIN
INSERT INTO tabela1(codigo) SELECT @a
SET @a = @a + 20
END
GO
Para confirmar utilize um SELECT na tabela:
Listagem 10. Select da tabela para verificar se está com o dados.
SELECT * FROM tabela1
Para maiores detalhes utilize o SP_HELP:
Listagem 11. Verificar detalhes da tabela.
sp_help 'tabela1'
Com isso concluo mais um artigo de forma básica e direta, espero que apesar de ter sido breve em alguns momentos e de certa forma não muito didático, as informações passadas possam ajudar de alguma forma.
Artigos relacionados
-
Artigo
-
Artigo
-
Artigo
-
Artigo
-
Artigo