
Mineração de dados na Prática – Parte 2
Veja nesse artigo um exemplo do uso da mineração de dados para análise do problema de evasão em cursos universitários. Será apresentada a aplicação de duas técnicas de mineração: agrupamento e árvore de decisão.
Demais posts desta série:
Mineração de dados na Prática – Parte 1
Mineração de dados na Prática – Parte 1
Artigo no estilo: Curso
Fique por dentro
A mineração
de dados apoia a descoberta de informações úteis que normalmente estão ocultas
em bases de dados com grande quantidade de registros. Neste artigo
apresentaremos dois casos práticos do uso de técnicas de mineração para análise
do problema de evasão em cursos universitários utilizando duas técnicas
distintas: agrupamento e árvore de decisão. Esta discussão é útil pois mostra
na prática como problemas reais podem ser tratados com o uso de técnicas de
mineração.Autores: Péricles Magalhães e Rodrigo Oliveira Spínola
Neste artigo, os arquivos gerados para a mineração de dados (apresentados na primeira parte) serão utilizados em estudos de caso em uma aplicação de algoritmo de clustering e em uma aplicação de algoritmo de classificação.
Caso 1 – Aplicação de Algoritmo de Clustering
O agrupamento ou clustering identifica similaridades entres os valores dos atributos analisados e, a partir dessa análise, particiona a base de dados em grupos. Para a execução da técnica, no estudo de caso, foi selecionado o algoritmo SimpleKMeans que, a partir da indicação da quantidade (k) de clusters desejada, divide a base de dados de forma que a similaridade dos elementos de cada cluster seja alta e, entre os clusters seja baixa.
O arquivo de entrada de dados gerado para essa aplicação, descrito no artigo anterior, foi carregado no WEKA onde algumas análises e considerações foram realizadas sobre a distribuição dos valores dos atributos e seu impacto na atividade. A Figura 1 apresenta as distribuições dos valores de cada atributo da base de dados carregada. Como pode ser observado, os atributos PendenciasAcademicas, PeriodosConcluidos e IndicadorEvasao apresentam apenas um valor, cada, em toda a base utilizada. Dessa forma, não possuem nenhuma interferência na criação dos agrupamentos.
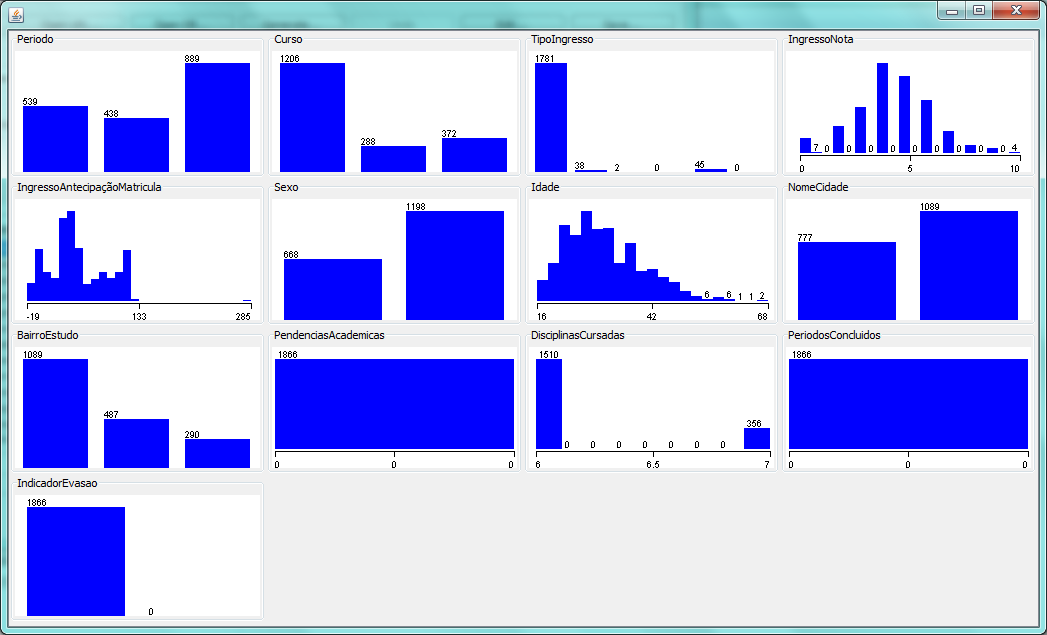
Figura 1. Representação gráfica da distribuição dos valores do arquivo de entrada para o caso 1
O algoritmo simpleKmeans apresenta algumas variáveis de configuração para a sua execução:
· displayStdDevs: indica a exibição de desvios padrão dos atributos numéricos e contagens de atributos nominais. Seu valor padrão é false;
" [...] continue lendo...
Artigos relacionados
-
Artigo
-
Artigo
-
Artigo
-
Artigo
-
Artigo