
Mais de 90 dicas de modelagem de dados
Com o intuito de auxiliar o trabalho dos desenvolvedores, este artigo apresenta um conjunto bastante abrangente de dicas de modelagem.
Os artigos dessa edição estão disponíveis somente através do formato HTML.

Clique aqui para ler todos os artigos desta edição
Dicas de modelagem de dados
A grande maioria dos desenvolvedores, mesmo não desempenhando formalmente o papel de DBA ou Analista de Dados, normalmente encontra-se envolvido com situações de modelagem de dados. Neste sentido, com o intuito de auxiliar o trabalho destes desenvolvedores, este artigo apresenta um conjunto bastante abrangente de dicas de modelagem.
Muitos dos problemas encontrados após a implementação de um banco de dados têm sua origem em uma modelagem de dados feita sem uma análise mais profunda do escopo do projeto. Outro fator que colabora para uma má modelagem é o desconhecimento de técnicas como a normalização e desnormalização de tabelas, bem como a não adoção de integridade referencial, que auxiliam na definição mais ajustada do modelo à realidade que irá atender.
Agora vamos às dicas!
Modelagem de dados: projeto conceitual
1. Sempre faça modelagem de dados, isso ajuda no entendimento do problema e no planejamento de uma solução mais aderente aos seus objetivos. O objetivo do modelo conceitual é a definição do problema, não da solução.
2. Existem diferentes terminologias para modelagem conceitual. Os exemplos da Figura 1 representam diferentes notações para um relacionamento 1:N, sendo as mais comuns de serem implementadas pelas atuais ferramentas CASE. A primeira notação, de Peter Chen, é a mais utilizada para a construção do modelo conceitual enquanto a segunda, do Pé de Galinha, é a mais utilizada para a construção do modelo lógico.
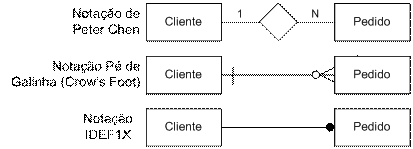
Figura 1. Notações para modelagem de dados.
3. Elimine qualquer redundância de dados. Redundâncias permitidas são aquelas relativas a chaves estrangeiras, que fazem referência à chave primária de outra tabela. Por exemplo, não se deve repetir o nome do cliente em seus pedidos, pois ele pode ser facilmente obtido através do relacionamento.
4. Utilize um padrão para dar nomes a entidades. Normalmente, nomes de entidades são no singular.
5. Dê nomes significativos a entidades, atributos e relacionamentos. Nomes que não representam seu real objetivo dificultam a compreensão do modelo.
6. Deve-se determinar os relacionamentos e, decidir como é a relação de dependência entre cada entidade é sempre importante. Os tipos de relacionamento podem ser:
· 0:1 (mínimo: nenhum – máximo: um);
· 0:N (mínimo: nenhum – máximo: muitos);
· 1:1 (mínimo: um – máximo: um);
· 1:N (mínimo: um – máximo; muitos);
· N:N (mínimo: muitos – máximo: muitos).
7. Relacionamentos não obrigatoriamente precisam ter nomes, mas é uma boa prática de modelagem nomeá-los, pois facilita o entendimento. Assim, utilize nomes significativos para os relacionamentos, como apresentado na Figura 2 para o relacionamento Lotação.
Figura 2. Nomeando relacionamentos.
8. Relacionamentos N:N ou que possuem atributos normalmente geram novas tabelas no modelo lógico. O nome do relacionamento pode ser utilizado como nome da tabela e deve ser cuidadosamente escolhido, como exemplificado na Figura 3.
Figura 3. Gerando tabelas a partir de relacionamentos.
9. Ao dar nomes a atributos determinantes, coloque sempre algo que identifique a entidade que está sendo relacionada. Por exemplo, um atributo chave cod_cliente é melhor do que simplesmente código. Lembre-se que, no modelo lógico, este atributo será repetido como chave estrangeira nas entidades relacionadas. Percebe-se na Figura 4 que, se o nome da chave primária da entidade Cliente for apenas codigo, quando repetida na entidade Pedido para representar o relacionamento, seu nome não será representativo, ou seja, não se pode observar facilmente a qual entidade está associado. Se o atributo tivesse sido chamado de cod_cliente, esta associação seria muito mais fácil. Este problema seria mais grave se a entidade Pedido estivesse associada à outra cujo nome de sua chave primária também fosse codigo. Teríamos mais de um atributo com o mesmo nome, que as ferramentas CASE costumam modificar atribuindo uma seqüência numérica, o que dificulta enormemente a compreensão do modelo.
Figura 4. Nomeando atributos chave.
10. Procure padronizar os nomes dos atributos de seu diagrama entidade relacionamento. Por exemplo, ao ver o atributo num_pedido percebe-se facilmente que seu tipo é numérico. A padronização garante um bom entendimento dos atributos perante a equipe de desenvolvimento, garantindo eficiência na fase de desenvolvimento da aplicação.
11. Atenção para entidades desconectadas no diagrama. Podem não ser um problema, mas precisam ser verificadas. Por exemplo, é comum que entidades que representem parâmetros estejam soltas no diagrama.
12. Cuidado com relacionamentos com participação total em ambos os lados de um relacionamento (obrigatoriedade dos dois lados). Isso pode provocar uma situação onde uma entidade dependa da outra recursivamente. Além disso, deve-se estar atentos a situações onde o banco de dados ainda está vazio e precisa-se cadastrar registros em apenas uma das entidades. Observe o exemplo abaixo da Figura 5. Um Cliente possui um ou mais Pedidos e um Pedido é obrigatoriamente de um Cliente. Devido à obrigatoriedade em ambos os lados do relacionamento, esta situação impede que Clientes sejam cadastrados sem Pedidos e que Pedidos sejam feitos sem Clientes.
Figura 5. Relacionamento com participação total em ambos os lados."
[...] continue lendo...
Artigos relacionados
-
Artigo
-
Artigo
-
Artigo
-
Artigo
-
Artigo