
Distribuição de Dados com Java - Revista Java Magazine 95
Este artigo relata sobre os problemas enfrentados ao escalar um aplicativo para um ambiente de cluster e discute possíveis soluções com o uso da Plataforma de DataGrid JBoss Infinispan.
De que se trata o artigo:
Este artigo relata sobre os problemas enfrentados ao escalar um aplicativo para um ambiente de cluster e discute possíveis soluções com o uso da Plataforma de DataGrid JBoss Infinispan.
Em que situação o tema é útil:
O tema é útil para arquitetos, analistas e desenvolvedores que desejam construir um sistema escalável e com alta disponibilidade, ou que queiram melhorar a performance de aplicações que têm um grande volume de dados e necessitam compartilhar o estado dos objetos em um ambiente de Cluster.
Resumo DevMan:
Uma das maneiras mais fáceis de melhorar a performance de uma aplicação é trazer os dados para mais perto dela e manter um formato que seja simples para ela consumir.
A maioria das aplicações escritas em Java consome dados que geralmente são armazenados em bancos de dados relacionais, como Oracle, MySQL, entre outros. Isto significa que para a aplicação consumir estes dados, precisa converter as informações que estão armazenadas em tabelas em objetos.
Por conta da natureza tabular destes dados, o processo de conversão de dados para objeto em memória pode ser muito custoso, e nem sempre é fácil. Para remediar estes problemas, ferramentas ORM como Hibernate e EclipseLink utilizam mecanismos de cache para armazenar os objetos internamente. Entretanto, quando a aplicação cresce e é necessário escalá-la para múltiplos servidores, começam a surgir vários problemas de sincronização de dados.
Para ajudar a resolver este problema, neste artigo vamos conhecer um pouco sobre os conceitos de distribuição de dados com soluções de DataGrid baseado na plataforma JBoss Infinispan, e analisar os benefícios e cenários de uso de uma solução como esta.
Quando falamos em manter a disponibilidade de uma aplicação, temos que considerar várias situações, pois ela pode ser afetada por diversos fatores, como erros sistêmicos, problemas de infraestrutura, ataques maliciosos, carga excessiva no sistema, entre outros. Uma camada (tier) física da sua aplicação, como o servidor de banco de dados ou o servidor de aplicação pode falhar e perder a comunicação, fazendo com que todo o sistema falhe.
Pensando nisso, uma boa estratégia para tolerância a falhas (failover) e para suportar as camadas do sistema seria colocar a aplicação em um ambiente em cluster, tanto os servidores web quanto os de aplicação, para garantir a alta disponibilidade de um serviço, como mostra a Figura 1.
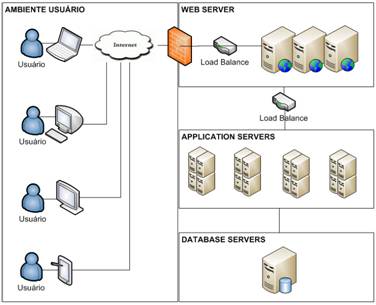
Figura 1. Escalando uma aplicação com diversos servidores.
Mas mesmo com redundância dos servidores e serviços, podemos ter outros problemas, principalmente quando falamos em replicação de dados. Imagine o seguinte cenário: existe um grande portal, chamado Pantanal, que é um grande site de e-commerce, construído em uma plataforma web baseada em Java EE, que recebe em torno de 4.000 a 5.000 requisições por dia. O ambiente de execução da aplicação utiliza servidores Web (Tomcat) para atender às requisições HTTP oriundas de seus clientes, servidores de aplicação (WebLogic) que contêm os componentes de negócio, Web Services e outros serviços de infraestrutura, e um servidor de dados (Oracle), responsável por armazenar todas as informações do sistema, como dados dos clientes, pedidos, produtos, etc.
No período de final de ano, o movimento no site quadruplicou, trazendo várias consequências para a aplicação – desde uma simples demora na resposta ao usuário, até quedas inesperadas no servidor de banco de dados.
Após uma análise detalhada nos logs da aplicação e das máquinas, o arquiteto da Pantanal.com, em conjunto com o Administrador de Banco de Dados (DBA), detectaram que o problema ocorreu no banco de dados, pois o aumento não planejado de requisições fez com que o banco se tornasse o “gargalo” da aplicação.
O arquiteto identificou que o sistema foi projetado de maneira que toda consulta realizada pelo usuário, por mais simples que seja, implica na criação de uma consulta no banco de dados, e dependendo do tipo da mesma, o sistema poderia executar até 12 queries por consulta realizada.
Desta forma, o arquiteto chegou à conclusão de que a única maneira de evitar uma falha séria no banco e a perda de informações seria reduzir a carga no mesmo, transferindo o tratamento de estado do sistema, que grande parte, atualmente, se encontra no banco de dados em Stored Procedures, para a camada da aplicação. E para tanto, é preciso criar uma nova camada lógica na solução, para fazer o gerenciamento dos dados entre o banco e a camada de negócio da aplicação.
Esta camada deve ter as seguintes características:
• Deve gerenciar os dados como objetos, pois a aplicação lida com objetos;
• Os objetos devem ser mantidos na memória para aumentar a performance da aplicação, evitar I/O excessivo no disco e aliviar o banco de dados;
• A camada deve (de maneira transparente) carregar informações ausentes para a memória oriundas do banco de dados;
• Ela deve ser capaz de propagar as modificações nos dados para o banco de dados (ou outro repositório persistente) de maneira assíncrona;
• Deve ser tão simples de escalar quanto a camada de aplicação.
Para atender aos requisitos acima, podemos utilizar uma plataforma de Data Grid. Dentro desta categoria, existem diversos frameworks e soluções, entre eles: Hazelcast, GigaSpaces, Oracle Coherence, Joafip, GridGain, ExtremeScale e JBoss Infinispan. Para este artigo, vamos focar nossos estudos na Plataforma de Data Grid Infinispan da JBoss, por ser uma plataforma nova e de fácil utilização.
Infinispan
Infinispan é uma plataforma para grid de dados open source distribuída pela JBoss. Geralmente, data grids são utilizados para reduzir a latência do banco de dados, prover alta disponibilidade e storage elástico dos dados, como soluções NoSQL. Data Grids podem ser utilizados em conjunto com bancos de dados tradicionais ou como cache distribuído, para acesso rápido aos dados.
Ao escolher o Infinispan no lugar de um simples cache, temos as seguintes vantagens:
• Cluster: Podemos distribuir nosso cache em cluster com apenas algumas configurações;
• Eviction: Mecanismo automático de eviction para evitar erros de out-of-memory e controle do melhor uso da memória;
• Cache Loader: É possível configurar cache loaders (ver tópico “Cache Loader”) para persistir o estado dos objetos em um banco de dados ou em um arquivo no disco;
• Suporte a JTA e compatibilidade com XA: Gerenciamento de transação com qualquer aplicação compatível com JTA;
• Gerenciamento: É possível gerenciar e monitorar os objetos de uma instância do grid de dados através de componentes JMX ou utilizar um console gráfico com RHQ.
O Infinispan implementa a JSR 107 (JCache), cuja especificação propõe uma API para tratamento de cache temporário com Java, mas é muito mais do que isto. Uma das propostas do JBoss Infinispan é substituir a solução JBoss Cache, muito conhecida e utilizada para caching e persistência de dados. Com Infinispan podemos, inclusive, utilizá-lo como cache de segundo nível para o Hibernate.
Apesar de o Infinispan incorporar vários conceitos do JBoss Cache, ele é diferente, pois é uma plataforma de grid de dados, podendo ser escalada para milhares de nós, além de possuir uma API em REST para acesso remoto. Sua estrutura é baseada na interface Map, como mostra a Figura 2.
Figura 2. Interface Cache compatível com a JSR 107.
A interface Cache expõe métodos simples para adicionar, consultar e remover objetos, incluindo mecanismos atômicos fornecidos pela interface ConcurrentMap do JDK.
Para criação de um cache, é utilizado um dos métodos getCache() sobrecarregados da interface CacheManager. Ela age como um repositório de "
[...] continue lendo...
Artigos relacionados
-
Artigo
-
Artigo
-
Artigo
-
Artigo
-
Artigo