
Business Intelligence: Conhecendo algumas ferramentas Open Source
Veja neste artigo o que é Business Intelligence (BI) e conheça algumas ferramentas open source disponíveis para BI e quais as funcionalidades e características que podemos esperar dessas ferramentas.
BI (Business Intelligence) é a utilização de variadas fontes de informação para definir estratégias de competitividade nos negócios da empresa. Como pode ser observado este é um conceito bastante amplo e poderíamos adicionar nessa definição conceitos de estruturas de dados que são representadas pelos bancos de dados tradicionais, data warehouse e data marts que tem como objetivo um tratamento relacional e dimensional de informações, bem como técnicas de data mining que podem ser aplicadas sobre elas, na qual se busca correlações e fatos que não são observáveis num primeiro momento. Ainda podemos adicionar outros conceitos como inteligência competitiva (CI - Competitive Intelligence), gerência de conhecimento (KMS - Knowledgement Management System) e BSC (Balanced Scorecard).
No restante do artigo veremos conceitos e práticas de como funciona a primeira parte conceitual do BI abordando data warehouse, data marts e aplicações de data mining, após isso veremos diversas ferramentas open source que nos fornecem as funcionalidades do BI.
Modelagem Dimensional de Dados
A visão dimensional modifica a ordem de distribuição de campos por entre as tabelas, permitindo uma formatação estrutural, mais voltada para muitos pontos de entradas específicos (chamadas de dimensões) e menos para os dados granulares em si (chamados de fatos). Dessa forma, na estrutura dimensional os dados estarão em uma forma em que várias tabelas de entrada estarão se relacionando com algumas tabelas de informações, criando assim uma notação mais sintética, legível e objetiva.
Portanto, o modelo dimensional oferece de forma clara e direta os elementos de que se precisa para buscar informações (fato) via dimensões de referências. Essa ideia é diferente da malha relacional, ou de rede como encontramos nos modelos anteriores, onde não existem estruturas específicas de entrada.
A forma mais direta de verificarmos na prática como acontece essa diferença entre o modelo clássico e o modelo dimensional se dá através do exemplo demonstrado na Figura 1, onde temos um modelo clássico de um sistema de vendas a varejo.
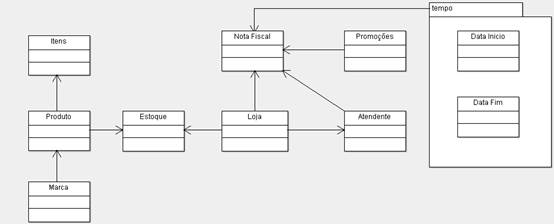
Figura 1. Exemplo de modelo ER.
No exemplo acima podemos notar as entidades LOJA que emite várias NOTAS FISCAIS, cada qual com vários ITENS e cada ITEM associado a um PRODUTO. Também podemos ter uma PROMOÇÃO associada a um período de tempo. Além disso, o modelo mostra uma entidade ESTOQUE que possui um relacionamento entre LOJA e PRODUTO e um ATENDENTE.
Agora, fazendo um contraponto podemos verificar na Figura 2 como fica o modelo acima sendo representado na forma dimensional.
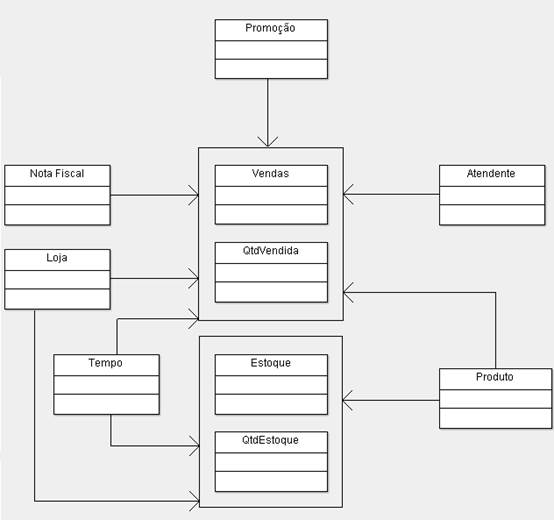
Figura 2. Exemplo de modelo dimensional equivalente ao modelo ER.
Na figura acima podemos verificar uma tabela FATO (Vendas) e seis tabelas DIMENSÃO (Tempo, Produto, Loja, Promoção, Atendente e Nota Fiscal). A tabela Fato, chamada de Vendas, representa as vendas de um PRODUTO, em um TEMPO ou DIA feito no âmbito de uma PROMOÇÃO numa LOJA, realizada por um ATENDENTE e registrada numa NOTA FISCAL. A tabela fato poderia possui apenas como métricas desejadas os campos “Quantidade Vendida” e “Valor em Reais” que eram dados do item da Nota Fiscal.
Podemos observar também a presença da tabela Estoque que poderia estar representado com o campo “Quantidade Estoque”. Esta também é uma tabela fato que surgiu da necessidade de registrar os aspectos de estoque. Essa tabela fato também se relaciona com algumas dimensões já identificadas na primeira tabela fato definida anteriormente como Tempo, Loja e Produto. Portanto, a métrica principal da tabela fato Estoque é a “Quantidade em Estoque” supondo que este fosse um campo desta tabela fato.
Assim sendo, podemos concluir que tudo que fizemos foi a realização de um remanejamento de dados e tabelas, onde criamos entradas de acesso que são as tabelas dimensão e algumas tabelas que contêm fatos relevantes que são as tabelas fato como Vendas e Estoque. Portanto, agora podemos acessar as métricas desejadas, entrando e combinando atributos de diversas dimensões de forma muito mais objetiva e direta, sem muitos percursos de navegação. As tabelas fato normalmente associam-se com documentos originados de transações de negócios. Alguns candidatos à tabela fato poderiam ser pedidos, despachos, pagamentos, transações bancárias, reservas, etc.
Conforme as necessidades dos requisitos, podemos criar outros esquemas dimensionais com tabelas fato e suas dimensões.
Conceitos de Ponto, Plano e Cubo
O valor pontual ou ponto representa a interseção de valores (fato) com relação aos eixos (dimensão). Por exemplo: Qual a quantidade de venda do PRODUTO P1, no DIA D1 na CIDADE C1? Este exemplo mostra somente três dimensões que é a visão de cubo, porém ele não se limita apenas a três dimensões, pode ter n dimensões (hipercubo ou hiperespaço). O plano por sua vez mostra o conceito plano ou fatia, onde este evidencia, por exemplo, os produtos P1 a Pn que foram vendidos na cidade C1, no período entre dias D1 e Dn. Portanto, o plano diria o quanto foi vendido do produto da categoria suco, vendido na cidade de Porto Alegre, no mês de Junho. Segue nas Figuras 3, 4 e 5 um exemplo de como poderíamos verificar graficamente essas situações do "valor dimensional ponto", "valores em planos" e "valores em cubos".
Figura 3. Representação dimensional – Valores em pontos.
Figura 4. Representação dimensional – Valores em Planos (Fatias).
Figura 5. Representação dimensional – Valores em Cubos.
Drill-down, Roll-up E Drill-Across
Outro conceito de operadores dimensionais é o Drill-down, Roll-up (ou Drill-up) e Drill-Across. O conceito de Drill-down está relacionado com o fato de sairmos de um nível mais alto da hierarquia e buscarmos informações mais detalhadas, ou níveis menores. Por exemplo, podemos imaginar que temos uma dimensão geográfica estruturadas da seguinte forma: PAÍS -> ESTADO -> CIDADE -> LOJA. Dessa forma, se já obtivemos as informações de vendas no nível de ESTADO e agora desejarmos detalhes por CIDADES, estaríamos solicitando um Drill-down. O inverso seria o conceito de Roll-up. Todas as ferramentas OLAP disponíveis no mercado estão aptas a executar esses dois operadores, que são considerados básicos dentro do conceito de manipulação dimensional de um data warehouse.
O conceito de Drill-across relaciona-se com a ideia de "pularmos" de um esquema para outro, desde que ambos tenham algumas dimensões em conformidade ou compartilhadas. Por exemplo, podemos imaginar que temos as tabelas fato VENDAS e ENTREGAS onde ambas compartilhassem a dimensão geográfica citada no exemplo anterior. Dessa forma, o comando Drill-across permitiria o acesso ao tratamento dessas informações que estão correlacionadas, mesmo que estejam em estruturas separadas, porém unidas por algumas dimensões em comum. Assim, temos uma espécie de join dimensional entre estruturas relacionadas, parecido com o join relacional que nos permite buscar informações em outra tabela a partir de campos comuns através de chaves primárias e estrangeiras. O Drill-across é equivalente ao join relacional, porém entre esquemas dimensionais.
Drill-Through
O conceito de Drill-through traz a ideia de desejarmos informações em um nível de detalhe menor do que aquele que está colocado na tabela fato e permitido pela sua granularidade. Por exemplo, imaginamos que armazenássemos na tabela fato VENDAS as informações em nível de granularidade de produto por dia e por loja. Portanto, o menor nível de granularidade que podemos alcançar na estrutura é a informação sobre produto. O Drill-through é uma operação que permite uma busca de informações além do nível de granularidade existente na estrutura dimensional. Para o exemplo citado acima aplicando o comando Drill-through estaríamos acessando as notas fiscais e os itens que deram origem (por agregação) ao fato armazenado em cada linha da tabela fato. É como se fosse um Drill-down, porém com a propriedade de buscar o detalhe em outra estrutura que está além do esquema dimensional, pois essas informações mais detalhadas do que a granularidade armazenada na tabela fato está em outro arquivo ou ambiente diferente do Data Warehouse ou Data Mart.
Outros Comandos
Algumas ferramentas possuem um conjunto bastante variado de operadores dimensionais, estatísticos e temporais. Entre as mais comuns são RANKING que classifica determinada informação baseada nos n melhores indicadores, LAST-WEEK que mostra os valores relacionados à semana anterior tendo como referência a semana atual, PRIOR-WEEK que mostra os valores relacionados ao período compreendido nos últimos sete dias tendo como referência a data atual, YEAR-TO-DATE que compreende o período do ano de referência até a data de hoje, entre outros comandos que permitem a manipulação dos dados.
Os comandos dimensionais são produzidos por comandos SQL que operam na retaguarda. Por exemplo, um Drill-down é a solicitação de um SQL que irá modificar o seu GROUP BY, obtendo o dado na granularidade solicitada. Muitas das ferramentas se incubem de traduzir as requisições de um comando OLAP em um ou mais comandos SQL.
Dessa forma, administradores desses ambientes de data warehouse e data marts deverão desenvolver um bom conhecimento em codificação SQL. O interessante é que alguns produtos já possuem uma espécie de dialeto SQL voltados para tratamentos dimensionais como o padrão MDX apoiado pela Microsoft. Porém, o próprio padrão oficial da linguagem SQL evoluiu nesta direção devido o crescimento dos projetos de Data Warehouse e Data Mart nos ambientes relacionais.
Data Warehouse, Data Mart e Operational Data Store
O conceito de BI está relacionado ao apoio e subsídio aos processos de tomada de decisão baseados em dados trabalhados especificamente para a busca de vantagens competitivas. Os dados presentes nos tradicionais sistemas legados, normalmente implementados nos ERP (Enterprise Resource Planning) constituem a base dos processos de negócios das empresas. Estes dados estão formatados e estruturados da forma transacional, o que dificulta o seu tratamento informacional. Assim, o conceito de BI deve ser entendido como o processo de desenvolvimento que objetiva a implementação de estruturas especiais de armazenamento de informações como Data Warehouse (DW), Data Marts (DM) e ODS (Operational Data Store), com o objetivo de montar uma base de recursos informacionais capaz de sustentar a camada de inteligência da empresa e possível de ser aplicada aos negócios, como elementos diferenciais e competitivos. Além disso, o conceito de BI também contempla o conjunto de ferramentas de desenvolvimento de aplicações e de ferramenta ETC (extração, tratamento e carga) que são fundamentais para a transformação dos recursos de dados transacional em informacional.
O DW e o DM se referem a estruturas (relacionais ou dimensionais) de dados, remodeladas com o objetivo de prover análises diferenciais. O ODS por sua vez nasceu como uma solução intermediária entre os muitos arquivos e dados espalhados pela empresa que careciam de certa uniformização. No entanto, DW e DM, estão relacionados com o armazenamento e tratamento de dados operacionais, de forma que também é consolidada, porém sem características dimensionais e voltado para a carga. Portanto, o ODS é como um cadastro consolidador de informações, porém mantidas as características de granularidade e de estruturação não dimensional, originadas dos sistemas legados e ERP.
O conceito de BI também objetiva implementar aplicações especiais de tratamento dos dados, como OLAP e Data Mining. OLAP (On-Line Analytical Processing ou Processamento Analítico On-Line) representa a característica de trabalharmos com operadores dimensionais, possibilitando uma forma múltipla e combinada de análise. Data Mining, por outro lado, está mais relacionado com os processos de análise de inferência do que com os de análise dimensional de dados. Assim, o Data Mining objetiva o reconhecimento de padrões escondidos nos dados e não necessariamente revelados pelas outras abordagens analíticas como o OLAP.
A Figura 6 mostra esquematicamente a arquitetura de um data warehouse corporativo. Nessa arquitetura, os dados são coletados das fontes operacionais e trabalhados na Staging Area que é uma camada intermediária de tratamento e armazenamento de dados. Na Staging Area os dados são submetidos a um tratamento de limpeza, combinação, acertos e combinações, que serão a fonte de carga do Data Warehouse corporativo. Também poderemos ter um banco de dados, denominados ODS (Operational Data Store), nessa camada visando formar um depósito intermediário, preparatório para a carga do Data Warehouse. Esse ODS tem características relacionais e poderá ser usado para acessos de informações integradas sobre certo assunto, oferecendo normalmente um excelente tempo de resposta. O DW corporativo fornecerá os insumos para a carga dos Data Marts departamentais, por assunto ou linhas de negócio. As funções de ETC (Extração, Transformações e Carga), responsável pelas ações de coleta, limpeza, preparação e carga desses depósitos de informações, estão representadas pela camada de Staging. Podemos notar que os processos de Data Mining trabalharão sobre um extrato de dados especialmente preparado para esta forma de tratamento com foco mais estatístico. Os dados em qualquer desses depósitos poderão ser analisados pelas ferramentas disponíveis que permitem a geração de relatórios ou cubos com análises dimensionais OLAP ou ferramentas de Data Mining. Existem diferentes formas de organizar os Data Warehouses, essa apresentada é apenas uma delas.
Figura 6. Estrutura de um Data Warehouse corporativo.
Ferramentas Livres
As ferramentas livres que serão indicadas nessa seção oferecem uma ampla variedade de relatórios e funcionalidades, sendo utilizadas em diversas organizações. Algumas ferramentas possuem um maior destaque como a Pentaho Community e SpagoBI que vão ainda mais além das outras fornecendo capacidades extras como um bom processamento OLAP, uma interface extremamente efetiva, suporte para diferentes áreas, entre outras funcionalidades.
As ferramentas open source citadas aqui podem substituir poderosas ferramentas pagas de BI como Oracle Business Intelligence Standard, Microsoft Business Intelligence, SAP Business Intelligence, SAS Business Intelligence e IBM Cognos.
Abaixo descreveremos algumas dessas ferramentas e as suas principais capacidades e na última seção falaremos de outras ferramentas também disponíveis na comunidade open source, porém mais voltadas para aspectos exclusivos de um BI.
Eclipse BIRT
Ferramenta tem como característica ser bastante flexível e muito utilizada em ambientes de relatórios. O grande problema dessa ferramenta é que se quisermos funcionalidades extras como Dashboards e outros tipos de relatórios precisaremos adquirir a versão comercial chamada ActuateOne.
A ferramenta Eclipse BIRT é uma das mais utilizadas entre as ferramentas de BI open source e como seu nome sugere ela executa na IDE Eclipse, fornecendo uma extensa quantidade de relatórios e ferramentas para visualização de informações.
A BIRT é uma engine que é o coração desta ferramenta de BI, possuindo uma grande coleção de classes Java e APIs que geram e executam relatórios nos formatos apropriados. Entre os relatórios temos listas com agrupamento e cálculos, gráficos de pizza, gráficos de linha e gráficos de barras, entre diversos outros, que podem ser exibidos em SVG. A ferramenta também suporta tabelas de referência cruzada, documentos (dados textuais) com listas incorporadas, gráficos, etc, além de relatórios compostos (agregado e relatórios embutido).
JasperSoft
A JasperSoft fornece uma variedade de versões para seu software de BI, o JasperSoft BI Suite. A versão Community possui um ambiente de relatórios e gráficos com uma infraestrutura completa que fornece todo suporte necessário. O gerador de gráficos suporta imagens, tabelas de referência cruzada e sub-relatórios para layouts de relatórios. O visualizador de relatório interativo é um browser baseado em um visualizador de relatório que fornece filtragem, ordenação e formatação. Além disso, o JasperSoft BI possui um repositório centralizado que fornece uma infraestrutura completa para relatórios e armazenamentos de perfis de usuários, dashboards e visualização analítica.
Outra funcionalidade interessante é o suporte para agendamento automático de relatórios e a versão Mobile BI que é suportada por aparelhos iPhone e Android.
A versão comercial da ferramenta adiciona muito mais dashboards, camada de metadata, análise em memória, capacidade de integração de informações e visualizações interativas.
Palo
A Palo é uma ferramenta open source para business intelligence focada em OLAP, Excel e interfaces Web. O Palo OLAP Server é o coração da ferramenta para o fornecimento de uma plataforma multiusuário e para o acesso de alta performance às informações. A ferramenta também oferece agregação em tempo real e é considerada ideal para colaboração em BI. A Palo ETL Server é oferecida para que possamos carregar informações no OLAP Server. O Palo também suporta a maioria dos data sources incluindo base de dados relacionais, SAP e muitos outros.
Além disso, a Palo Web fornece interfaces para usuários de negócio e designers. Os designers podem administrar o sistema e criar relatórios baseados na web, enquanto usuários podem visualizar os relatórios.
A Palo para Excel é onde os usuários de negócio passarão maior parte do seu tempo. Essa ferramenta possui uma lógica central que evita diversos gargalos frequentemente encontrados quando usamos Excel para tarefas mais complexas. Como a Palo é baseada em células que é o oposto ao baseado em registros, esta suíte é a ideal para interface Excel ou OpenOffice.
A versão comercial oferece consideravelmente mais funcionalidades do que a versão livre. As versões estão disponíveis em http://www.palo.net/.
Pentaho Community
A Pentaho é uma suíte para BI bastante complexa que oferece suporte a relatórios, ferramentas de data mining com funcionalidades bastante sofisticadas, e provavelmente sanará as necessidades da maioria das organizações.
O Pentaho BI Suite Community Edition (CE) inclui ETL, OLAP, metadata, data mining, relatórios e dashboards.
Uma variedade de soluções open source são reunidas para oferecer diversas funcionalidades, entre elas tem-se: Weka para data mining, Kettle para integração de dados, Mondrian para OLAP, e diversas outras para relatórios de BI, dashboards, OLAP, e big data.
A plataforma Pentaho BI também oferece um ambiente para construção de soluções de BI e inclui autenticação, uma engine para regras e web services. O servidor do Pentaho BI fornece gerenciamento de relatórios baseados na web, integração de aplicações e workflow.
O Pentaho Report Designer, Reporting Engine e Reporting SDK suportam a criação de relatórios relacionais e analíticos com muitos formatos de saída e diferentes data sources.
O Pentaho também oferece versões com suporte, treinamentos e consultoria, assim como mais funcionalidades e customizações.
A ferramenta está disponível em http://community.pentaho.com/.
ReportServer
O ReportServer fornece uma plataforma extremamente flexível para geração de relatórios e dashboards. A ferramenta suporta Eclipse BIRT, JasperReports e SAP Crystal Reports além das suas próprias ferramentas de relatórios. A interface com usuário é baseada na web e suporta uma grande quantidade de ferramentas de administração. O Script Reports é usado para relatórios complexos e requer habilidades em programação para manipula-lo. Dashboards interativos são suportados e são construídos através de itens chamados dadgets (Dashboard Gadgets). Entre os Data sources suportados incluem a Oracle, Microsoft SQL Server, IBM Informix, IBM DB2, mySQL, PostgreSQL, h2 e arquivos csv.
Versões pagas incluem treinamento, consultoria e suporte.
SpagoBI
O SpagoBI é considerado a melhor ferramenta de BI open source disponível atualmente. A ferramenta possui uma grande coleção de softwares open source para BI criando uma ampla capacidade para suportar business intelligence. Além das características essenciais que uma ferramenta de BI possui, a SpagoBI inclui outros domínios como data mining e BPM. Grandes empresas como FIAT e Gamebay já aderiram à SpagoBI como parte da sua solução de BI. A SpagoBI é também a única solução de BI open source que a versão livre é a única versão disponível. Portanto, esta ferramenta destaca-se por ser complexa e totalmente livre.
A quantidade de ferramentas oferecidas é realmente impressionante e cada área é servida por um grande número de funcionalidades, entre elas: Relatórios, análises multidimensionais, gráficos, KPI, Relatório ad-hoc, Location Intelligence, Data mining, Dashboard e Console, colaboração, automação, ETL, Mobile e muito mais.
O site oficial oferece treinamento e suporte que são pagos. A SpagoBIestá disponível em http://www.spagobi.org/.
Outras ferramentas
Existem diversas outras ferramentas open source que também podem ser utilizadas como a Openl (http://openi.org) e a ERP BI (http://host.bicourse.com/site/) que também oferecem soluções completas de BI.
Soluções para ETL destacam-se as ferramentas Apatar (http://www.apatar.com/index.html), Clover ETL (http://www.cloveretl.com), GeoKettle (http://www.spatialytics.org/projects/geokettle/), KETL (http://www.ketl.org), Scriptella (http://scriptella.javaforge.com), Talend (http://www.talend.com/index.php) e a DataCleaner (http://datacleaner.eobjects.org) que podem ser substitutas das ferramentas pagas SnapLogic (http://www.snaplogic.com) e Informatica (http://www.informatica.com/us/).
Soluções para Base de Dados e Data Warehouses destacam-se as ferramentas Cassandra (http://cassandra.apache.org), MongoDB (http://www.mongodb.org), FlockDB (https://github.com/twitter/flockdb), Hypertable (http://hypertable.org), CouchDB (http://couchdb.apache.org) e OrientDB (http://www.orientdb.org/index.htm) que são substitutas para as ferramentas pagas Oracle NoSQL Database (http://www.oracle.com/technetwork/products/nosqldb/overview/index.html) e Amazon SimpleDB (http://aws.amazon.com/simpledb). Outras soluções conhecidas para base de dados é o MySQL, PostgreSQL, Firebird, HBase, entre outros.
Soluções de Reporting destacam-se as ferramentas JMagallanes (http://jmagallanes.sourceforge.net/en/), Actuate (http://www.actuate.com) e OpenReports (http://oreports.com) que substituem as ferramentas pagas SAP Crystal Reports (http://store.businessobjects.com) e DBxtra (http://www.dbxtra.com).
Soluções de Data Mining e Analytics destacam-se as ferramentas KNIME (http://www.knime.org), RapidMiner/RapidAnalytics (http://rapid-i.com), Orange (http://orange.biolab.si), jHepWork (http://jwork.org/jhepwork/), SPMF (http://www.philippe-fournier-viger.com/spmf) e Rattle (http://rattle.togaware.com) que substituem as ferramentas pagas SAS Predictive Analytics (http://www.sas.com/technologies/analytics/datamining/), Oracle Data Miner (http://www.oracle.com/technetwork/database/options/advanced-analytics/odm/index.html) e Statistica (http://www.statsoft.com).
Soluções para ERP com funcionalidades de BI destacam-se as ferramentas Openbravo ERP (http://www.openbravo.com/product/erp/business-intelligence/), ADempiere (http://www.adempiere.com/index.php/ADempiere_ERP), Compiere (http://www.compiere.com), JFire (http://www.jfire.net) e Opentaps (http://www.opentaps.org/index.php) que substituem as ferramentas NetSuite (http://www.netsuite.com) e Microsoft Dynamics (http://www.microsoft.com/en-us/dynamics/default.aspx).
Bibliografia
[1] Vinicius, F. Decisões com B.I. - Business Intelligence. Ciência Moderna, 2008.
[2] Barbieri, C. BI2: Business Intelligence Modelagem e Qualidade. Campus, 2014.
Artigos relacionados
-
DevCast
-
DevCast
-
DevCast
-
DevCast
-
DevCast