Atenção: por essa edição ser muito antiga não há arquivo PDF para download.Os artigos dessa edição estão disponíveis somente através do formato HTML.

Bancos de dados relacionais são responsáveis por armazenar e recuperar dados de forma eficiente. No entanto, somente estas atividades não garantem a continuidade dos negócios. Nos dias de hoje, cada vez mais é necessário que se tire um proveito maior dos dados. Surge a tríade dado, informação e conhecimento. O dado é algo bruto, é a matéria-prima da qual podemos extrair informação. Informação é o dado processado, com significado e contexto bem definido. O computador, em essência, serve para transformar dados em informações. Por fim, o conhecimento é o uso inteligente da informação, é a informação contextualizada e utilizada na prática. Dessa forma, a qualidade da informação sustenta o conhecimento.
Os bancos relacionais, quando bem projetados, permitem a extração de diversas informações usando SQL. O mecanismo é simples: elabora-se um problema, é realizado um mapeamento para a linguagem de consulta, e esta consulta é submetida ao SGBD. Observe que esse processo resolve questões que necessariamente devem ser definidas, ou seja, as informações extraídas são respostas a uma consulta previamente estruturada. No entanto, dados armazenados podem esconder diversos tipos de padrões e comportamentos relevantes que a princípio não podem ser descobertos utilizando-se SQL. Além disso, por mais que o analista seja criativo, ele irá apenas conseguir elaborar diversas questões de forma que se tenham resultados práticos no final. Neste contexto está inserida a aplicabilidade da mineração de dados.
Para exemplificar, considere um cadastro com aproximadamente 500.000 clientes de uma loja de roupas. Através do uso de técnicas de mineração foi descoberto que 7% desses clientes são casados, estão na faixa etária compreendida entre 31 e 40 anos e possuem pelo menos dois filhos. Uma campanha de marketing direcionada a esse grupo de clientes poderia ser realizada objetivando o aumento no consumo de produtos infantis. Note que inicialmente não foi elaborada uma questão do tipo “identifique os clientes casados com faixa etária entre 31 e 40 anos e que possuem pelo menos dois filhos”. O próprio processo de mineração identificou a pergunta e a resposta.
Assim, mineração de dados pode ser definida como o processo automatizado de descoberta de novas informações a partir de grandes massas de dados. A mineração de dados é uma área extensa, interdisciplinar e envolve o estudo de diversas técnicas (ver figura 1).
Para que o conceito seja melhor entendido, vejamos o seguinte exemplo (retirado do livro DataMining: Técnicas e Aplicações para o Marketing Direto, Fernanda Cristina Naliato do Amaral, Ed. Berkeley, 2001): tomemos uma base de dados de empréstimos pessoais. O tipo de conhecimento que se deseja extrair é como identificar os mutuários negligentes. Uma vez consultado um analista de dados, este considerou que os dados mais representativos do conhecimento desejado são fornecidos pelos atributos salário, débito e regularidade de pagamento. De posse dessas informações, pode-se formar o gráfico da figura 2, que mostra o conjunto de dados usado, composto de 14 amostras.
Cada ponto no gráfico representa um mutuário a quem foi dado um empréstimo por um banco particular, em algum momento no passado. No eixo horizontal, tem-se o salário do mutuário; no vertical, seu débito mensal (hipoteca, pagamento de carro, etc).
Os dados foram classificados em duas classes: os mutuários representados por X, que estão em débito com o pagamento dos empréstimos, e os representados por O, em dia com o banco. A partir do gráfico da figura 2, tenta-se definir padrões onde as pessoas consideradas negligentes estejam separadas das pessoas não negligentes.
O padrão linear t representa apenas parte da realidade, uma vez que nem sempre ele é verdadeiro. Ao examinarmos a figura 2, chegamos a seguinte regra:
Se salário >t, então mutuário é bom pagador.Note que a regra nem sempre é verdadeira: visualmente, podemos notar que existem casos em que mesmo um cliente com um salário > t não é um bom pagador. A proposta é encontrar o padrão que retrata de forma mais fiel o conhecimento apresentado nos dados. Para isso, além do padrão linear, existem outras técnicas mais complexas, que podem ser visualizadas na figura 3.
Em diversos livros e artigos, a mineração de dados é vista como parte de um processo maior, denominado KDD - Knowledge Discovery in Database - que significa descoberta de conhecimento em bases de dados. Este processo é dividido em seis etapas e envolve duas grandes fases: preparação de dados (destaque em azul) e sua mineração (destaque em verde) (ver figura 4).
O processo de KDD é iniciado através da compreensão do domínio da aplicação e o estabelecimento dos objetivos a serem obtidos. Nesta fase, as questões em potencial para a mineração são identificadas. Dependendo do problema a ser minerado e da massa de dados disponível, haverá a escolha do tipo de técnica a ser trabalhada. A questão a ser minerada e a própria técnica a ser trabalhada definem qual parte da massa de dados inicial vai ser utilizada e, para isso, selecionada.
No próximo passo é realizada a limpeza através de um pré-processamento dos dados. Nesta fase são eliminadas eventuais incompletudes, problemas de tipagem, repetição de registros etc.
Os dados pré-processados passam ainda por uma transformação com o objetivo de facilitar seu uso pelas técnicas de mineração. Nesta fase, o uso de data warehouse (DW) torna-se bastante útil, pois nessas estruturas o pré-processamento dos dados já existe (para mais informações sobre data warehouse, leia o artigo de Patrícia Barbalho, na edição 3 da revista). Ou seja, as informações já estão consolidadas num formato mais estatístico e menos transacional.
Dando continuidade ao processo, chega-se à fase de mineração, a qual começa com a escolha dos algoritmos a serem aplicados. Essa escolha depende do objetivo do processo de KDD. Ao final do processo, o sistema que efetuou a mineração poderá gerar relatórios das descobertas, que passam pela interpretação dos analistas envolvidos. A partir das informações identificadas é possível utilizá-las, transformando-as assim em conhecimento.
Alguns elementos que fornecem apoio ao processo de KDD são:
Descobrir padrões e tendências escondidos em grandes massas de dados não é um processo trivial. Em mineração de dados este processo envolve o uso de diversas tarefas e técnicas. As tarefas são classes de problemas, que foram definidas através de estudos na área. As técnicas são grupos de soluções (algoritmos) para os problemas propostos nas tarefas. Cada tarefa apresenta várias técnicas, e algumas técnicas podem ser utilizadas para solucionar tarefas diferentes.
As classes de tarefas básicas são:
Entre as principais técnicas, podemos destacar as árvores de classificação, redes neurais, algoritmos genéticos, algoritmo de Bayes, entre outros.
Serão apresentados quatro exemplos associados às tarefas acima. Para cada um deles será utilizada uma técnica específica.
O objetivo desta tarefa é construir um modelo que seja capaz de gerar classificações para novos objetos ou novos dados (tarefa preditiva). Para isso, devem ser considerados dois tipos de atributos que caracterizam o objeto: atributos preditivos, cujos valores irão influenciar no processo de determinação da classe; e atributos objetivos, que indicam a classe a qual o objeto pertence. Assim, a classificação visa descobrir algum tipo de relacionamento entre os atributos preditivos e objetivos.
A principal técnica utilizada para a tarefa de classificação é a árvore de classificação (classification tree). Vejamos um exemplo que utiliza esta técnica: imagine uma aplicação que analisa dados de clientes, visando a aprovação ou não (atributo objetivo) de crédito para empréstimo pessoal. Neste banco de dados, existem pessoas adimplentes e inadimplentes sendo cada classe caracterizada por algum tipo de padrão. Neste processo, os clientes do banco de dados cujo campo resultado venham a ter o valor não, representarão os inadimplentes. Para poder preencher esse campo, serão consideradas as características dos clientes (atributos preditivos) existentes no banco. Normalmente, um analista indica quais são os atributos relevantes para a predição – neste exemplo, os atributos preditivos são cargo e tempo. Observe que é um exemplo meramente ilustrativo e que num processo real outros atributos também deveriam ser considerados. O processo pode ser dividido em duas fases:
Vejamos um bom exemplo de como a técnica de árvore de classificação pode ser útil. Imagine uma empresa que quer aumentar a venda de telefones celulares. Com isto, temos:
Além da árvore de classificação, a classificação Bayes também se destaca com uma das técnicas utilizadas para resolver esta tarefa. A classificação Bayes utiliza classificações estatísticas baseadas no teorema de Bayes (Acesse aqui). Para maiores informações, consulte as referências indicadas no final deste artigo.
Veremos agora um exemplo prático de utilização de árvores de classificação utilizando o aplicativo Weka. Esta ferramenta é implementada em Java e está disponível para download(Acesse aqui). A ferramenta trabalha com diversas técnicas de data mining.
A ferramenta pode ser utilizada de duas formas: através de linha de comando ou de uma interface gráfica. Ao iniciar, escolha a opção Explorer para entrar na interface gráfica (figura 8). A tela principal é apresentada na figura 9. Maiores detalhes sobre o uso da ferramenta através de linha de comando podem ser obtidos na documentação que acompanha o produto.
O objetivo deste exemplo é gerar uma árvore que auxilie na tomada de decisão entre jogar ou não jogar tênis a depender das condições climáticas. Para este exemplo, utilizamos a tabela weather.arff disponibilizada pela própria ferramenta. Para selecionar o arquivo, clique no botão Open File. O conteúdo deste arquivo pode ser visualizado na listagem 1. Neste exemplo, os atributos outlook, temperature, humidity e windy serão preditivos, e o atributo play será objetivo. Neste caso, o atributo objetivo especifica apenas duas classes: YES e NO, que indicam se o tempo está bom ou não para jogo.
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature real
@attribute humidity real
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,noNo destaque 1 da figura 9 vemos os atributos da tabela. Clique sobre cada atributo para visualizar como ele influencia no resultado total da tabela (destaque 2 da figura 9).
Para gerar a árvore de classificação, clique na aba classify. Tendo feito isto, clique no botão Choose e selecione o algoritmo a ser utilizado (destaque 1 da figura 10). Neste exemplo, usaremos o J4.8 (figura 11). O atributo classificador (atributo objetivo) é selecionado como mostrado no destaque 2 da figura 10. Por último, clique no botão Start – a árvore de classificação gerada pode ser visualizada no destaque 3 da figura 10. A partir de agora, a árvore pode ser usada para identificar novos casos. Por exemplo, se tivermos uma condição climática como a seguir:
outlook: rainy;
temperature: 80;
humidity: 65;
Windy: False.Seguindo a árvore de classificação, temos que o dia será bom para jogo. Veja a representação gráfica da árvore na figura 12. Para obter esse gráfico, clique com o botão inverso do mouse sobre o item trees.J48, gerado dentro do Result List, e selecione a opção Visualize Tree.
Os problemas de associação são solucionados através da técnica de regra de associação. Existem diversos algoritmos baseados nessa técnica: apriori, DHP, ABS, sampling, dentre outros.
Genericamente, uma regra de associação é representada pela notação X?Y (X implica em Y), onde X e Y são conjuntos de itens distintos. Neste caso, um item é representado por um dos conceitos existentes no domínio da aplicação. O objetivo desta técnica é representar, com determinado grau de certeza, uma relação existente entre o antecedente e o conseqüênte de uma regra de associação. A associação é uma tarefa descritiva, ou seja, ela visa identificar padrões em dados históricos.
Imagine um banco de dados contendo milhares de registros de transações de compras. Para o nosso exemplo consideraremos 10 transações desse banco de dados (ver tabela 1).
| IDTRANSAÇÃO | ITENS COMPRADOS |
|---|---|
| 1 | café, leite, manteiga, pão |
| 2 | milho, morango, pão |
| 3 | café, leite, farinha, cerveja |
| 4 | biscoito, café, carne, leite, presunto, vinho |
| 5 | adoçante, biscoito, peixe, queijo, vinho |
| 6 | adoçante, café, leite, pão |
| 7 | biscoito, milho, presunto, tomate |
| 8 | café, mel, leite, macarrão |
| 9 | frango, mel, tomate |
| 10 | biscoito, café, cerveja, leite, refrigerante |
O objetivo aqui é saber se determinado produto X implica na compra do produto Y. Esta implicação é avaliada através de dois fatores: suporte e confiança.
Considere a regra café ? leite.
O suporte de uma regra representa o percentual das transações em que tal regra aparece. No exemplo, existem 10 transações. Note que os itens café e leite aparecem juntos em 60% das transações (transações 1, 3, 4, 6, 8 e 10).
Considere agora a regra biscoito ? vinho.
Os itens biscoito e vinho aparecem juntos em apenas 20% das transações (transações 4 e 5).
A regra café ? leite possui 60% de suporte e a regra biscoito ? vinho possui 20% de suporte. Quando o suporte for baixo, a regra pode não ser relevante uma vez que aparece apenas em uma pequena parte das transações.
Já o fator confiança, ao invés de considerar todas as transações, trabalha apenas com as que possuem o antecedente da regra. Assim, a confiança é calculada dividindo-se o número de vezes em que o conseqüente da regra aparece pela quantidade dessas transações. Por exemplo: o item café aparece seis vezes na base de dados de transação (transações 1, 3, 4, 6, 8 e 10). Para a regra café ? leite, a confiança é de 100%, ou seja, em todas as compras de café, há a compra de leite.
Já o item biscoito aparece quatro vezes na base de dados de transação (transações 4, 5, 7 e 10). Para a regra biscoito ? vinho, a confiança é de 50%, já que as transações 7 e 10 não contêm vinho. Isto significa que uma em cada duas transações contendo biscoito também contém vinho.
Um algoritmo de extração de regras de associação deve gerar regras que possuam suporte e confiança especificados pelo usuário. Observe que as regras podem ser compostas por um ou mais itens. Dependendo do tamanho da base de dados e dos fatores de suporte e confiança, inúmeras regras são geradas. Essas regras devem ser avaliadas pelo usuário especialista, para que somente as mais relevantes possam ser utilizadas na tomada de decisão.
Tendo a regra a seguir:
{cerveja, X } => {batatas fritas}
Podemos concluir que:
Vejamos um exemplo de utilização de regras de associação com a ferramenta Weka. Neste caso, utilizaremos a tabela weather.nominal.arff. Para gerar as regras de associação, clique na aba Associate. Você perceberá que o algoritmo apriori já aparece previamente selecionado (na área Associator). A implementação deste algoritmo na ferramenta Weka apresenta algumas particularidades:
Obs: Para configurar os parâmetros, clique sobre o nome do algoritmo apriori, na área Associator.
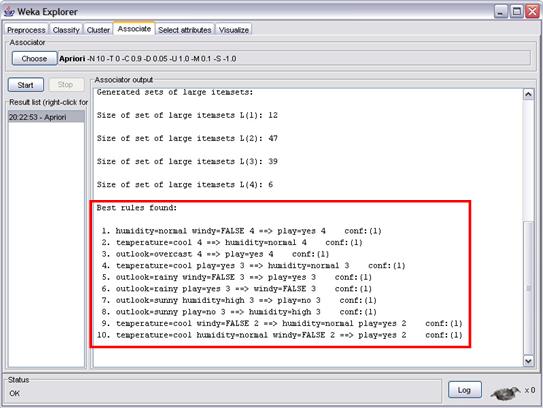
Para iniciar o processo, clique no botão Start. Feito isto, são geradas dez regras de associação, apresentadas no destaque da figura 13. Vamos analisar o resultado:
As regras de associação podem ser utilizadas por um analista para geração de novos conhecimentos. Por exemplo, podemos concluir com a regra 1 que, independente de outras variáveis climáticas, um dia com humidade normal e sem vento sempre é um bom dia para jogar tênis.
A tarefa de clusterização é descritiva, ou seja, ela visa identificar padrões em uma massa de dados. A principal diferença entre a classificação e a clusterização é que nesta última as classes não são previamente definidas. A idéia é que o algoritmo de clusterização identifique automaticamente comportamentos similares em uma base de dados, dividindo a massa de informação em clusters. Após o processo de clusterização, o analista deve estudar os padrões identificados a fim de determinar se eles podem ser transformados em conhecimento estratégico.
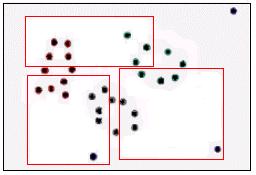
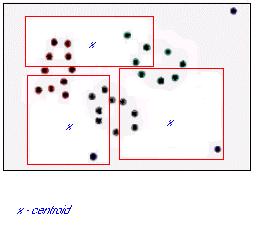
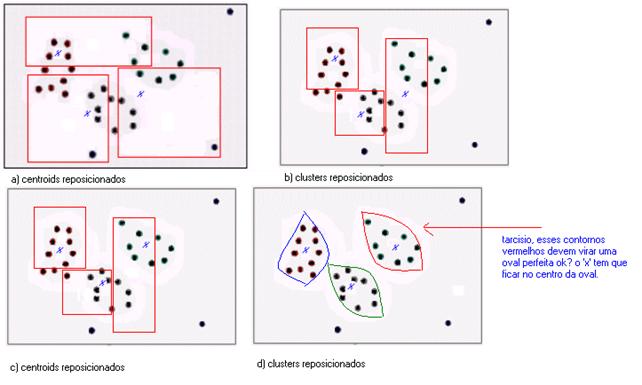
A figura 14 representa, hipoteticamente, os dados de uma tabela mapeados para um espaço bidimensional. Uma técnica de clusterização poderia identificar três clusters nessa tabela, conforme mostrado na figura 15. Observe que a clusterização não responde porquê os padrões existem, ela apenas os identifica.
Na ferramenta Weka, os algoritmos de clusterização podem ser acessados através da aba Cluster. O algoritmo que implementa a técnica k-means é chamado SimpleKMeans, e o algoritmo que implementa a técnica de hiearquia é chamado CobWeb. Não entraremos em detalhes, pois um exemplo prático de clusterização pode ser visto na matéria Explorando visualmente informações em grandes bases de dados utilizando a ferramenta FMDB, publicada nesta edição. Maiores informações sobre o uso da ferramenta Weka para clusterização podem ser obtidos em sua documentação.
A estimativa (também conhecida como regressão) é considerada uma tarefa preditiva - seu objetivo é prever um valor numérico desconhecido a partir de alguns atributos conhecidos, utilizando uma massa de dados histórica como modelo. Por exemplo, tendo um banco de dados de imóveis, podemos prever o valor do aluguel de um novo imóvel baseado em fatores como localidade, dimensão, segurança, entre outros.
As técnicas mais comuns de estimativa são baseadas nos mesmos métodos da classificação, ou seja, utilizam árvores de decisão. Em outras palavras, a idéia básica é a geração de modelos que possam estimar o valor (numérico) de determinado atributo. Exemplos de algoritmos de estimativa são: M5 e CART.
Vamos ao exemplo prático na ferramenta Weka. Utilizaremos o arquivo baskball.arrf, disponível no website da revista. Esse arquivo foi obtido do endereço Datasets-numeric.jar, que disponibiliza um jarfile contendo 37 problemas de regressão. No website da ferramenta podem ser obtidos outros datasets de exemplo.
A tabela baskball contém dados de atletas de basquete. Os campos são: assistência por minuto, altura, tempo em quadra, idade e pontos por minuto. A Listagem 2 mostra parte deste arquivo. O objetivo do exemplo é gerar um modelo para prever a altura de um determinado jogador tendo em mãos as demais informações.
@relation baskball
@attribute assists_per_minute real
@attribute height integer
@attribute time_played real
@attribute age integer
@attribute points_per_minute real
@data
0.0888,201,36.02,28,0.5885
0.1399,198,39.32,30,0.8291
0.1107,196,35.22,25,0.4799
0.2521,183,31.73,29,0.5735
0.1007,193,28.81,34,0.6318
0.1067,196,35.6,23,0.4326
...Clique na aba Classify. O algoritmo utilizado será o M5P (figura 21), que é baseado na geração de árvores de classificação.
O próximo passo é escolher o atributo objetivo (altura do jogador); lembre-se que o objetivo da estimativa é prever o valor de atributos numéricos – portanto, o atributo objetivo deve ser numérico. Para isso, selecione o atributo de acordo com o destaque 1 da figura 21. Em seguida, clique em Start. O resultado pode ser visualizado no destaque 2 da figura 21.
Para visualizar a árvore de decisão clique com o botão inverso do mouse sobre o item trees.M5P, gerado dentro do Result List, e selecione a opção Visualize Tree.
Para exemplificar, um jogador com as características assists-per-minute = 0,19 e time-played = 34 tem uma altura prevista de 1.88 (regra 4). A função para a regra 4 é:
height = (-104.3935 * assists_per_minute) + (0.0352 * time_played) + 206.8226
Neste artigo vimos que o crescente acúmulo de dados nas corporações muitas vezes esconde informações relevantes. Neste cenário, foram apresentados a importância da mineração de dados e o processo (KDD) do qual ela faz parte. Por fim, foram vistas algumas técnicas de mineração juntamente com exemplos didáticos e reais, facilitando assim o entendimento.
As técnicas apresentadas neste artigo são as mais básicas no processo de data mining. Existem diversas ténicas mais complexas, tais como redes neurais, algoritmos genéticos, indução, dedução, entre outras. Contudo, os métodos apresentados neste texto são os mais populares, e servem para resolver a maioria dos problemas primários de descoberta de conhecimento.
Espero que tenham gostado do assunto. Ele é bastante amplo e diversas áreas podem obter benefícios com seu uso. Até a próxima!

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.