ORM ou Object Relational Mapping é uma técnica de mapeamento objeto relacional que visa criar uma camada de mapeamento entre nosso modelo de objetos (aplicação) e nosso modelo relacional (banco de dados) de forma a abstrair o acesso ao mesmo.
Com isso, ao longo do tempo foram criados diversos frameworks ORM, que nos ajudam nas tarefas de persistência e recuperação de dados, nos dando mais produtividade em nossas tarefas diárias. Neste artigo veremos os conceitos principais por trás da técnica e dos frameworks ORMs, como a sua mecânica e funcionamento. Veremos o que são e como trabalham, conceituando as principais características destes e apresentando quais os principais frameworks existentes no mercado.
Quase todo sistema precisa gravar dados durante seu uso que podem ser guardados para posterior processamento ou leitura como, por exemplo, num sistema de uma loja que precisa guardar os dados dos produtos, vendas, funcionários, dentre outros.
No mundo .NET temos um caminho padrão para acessar dados em SGDBs relacionais através do ADO.NET, biblioteca que nos fornece diversas classes para acesso e manipulação de dados, não somente de SGDBs relacionais como também de XMLs e documentos do Office (como excel e access).
Por outro lado, ao adotar uma solução baseada puramente em ADO.NET sofremos com alguns problemas, como por exemplo:
Saiba mais: Guia Completo de SQL
Além disso, o modelo de dados relacional possui algumas limitações em comparação com o modelo de objetos (Nota do DevMan 1), como por exemplo:
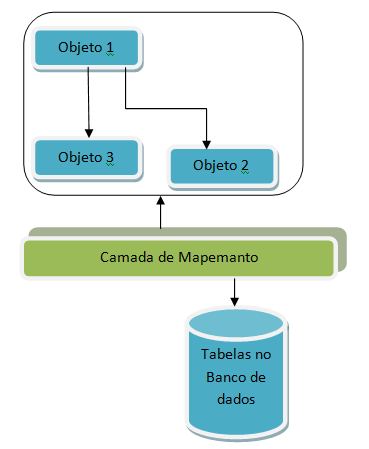
Diante disto, corremos o risco de limitar a arquitetura de nossa aplicação orientada a objetos ao modelo relacional. Para resolvermos este problema precisamos realizar um parse dos dados de um modelo para o outro. Este parse pode ser feito manualmente, através de consultas SQL acessando as tabelas de nosso banco de dados e alimentando objetos de nossa aplicação, ou de forma automática utilizando uma camada de mapeamento, chamada ORM, como ilustrado na Figura 1.
ORM (Object Relational Mapping) é uma técnica para mapeamento entre um modelo de dados relacional e um modelo orientado a objetos que visa resolver, ou pelo menos minimizar, as diferenças entres estes dois modelos. Para facilitar a aplicação desta técnica surgiram os frameworks ORM, como por exemplo, o NHibernate e o Entity Framework. Desta forma, esses frameworks se localizam em uma camada intermediária entre a lógica da sua aplicação e o seu SGDB.
O framework passa a receber as solicitações de interação com o SGDB através de objetos de sua aplicação e gera automaticamente todo o SQL necessário para a operação solicitada, nos poupando do trabalho de escrita e manutenção deste SQL e abstraindo o uso do SGDB, fazendo com que nos preocupemos apenas com nosso modelo de objetos. Além disso, o framework já trata as variações de tipos de dados existentes entre nossa aplicação e nosso SGDB.
Com isso, nossa aplicação passa a interagir com o framework e não mais com a base de dados diretamente, desacoplando nosso sistema de SGDBs específicos. Além disso, com uso de frameworks ORM a produtividade aumenta devido ao fato de não precisarmos escrever códigos SQL para inserir, alterar, excluir e recuperar dados do SGDB.
Os principais ORMs que trabalham com o .NET são o Entity Framework e NHibernate mas estes não são os únicos. A primeira tentativa de ORM da Microsoft no .NET foi o LinqToSQL, que ainda é usado por muita pessoas mas que aos poucos foi sendo substituído pelo Entity Framework. Na versão 4 do .NET a Microsoft anunciou que iria descontinuar o LinqToSql, tornando o Entity Framework a opção nativa para ORM.
O Entity Framework vem ganhando melhorias muito rapidamente, no momento em que escrevo este artigo a versão 6 já está disponível em alpha e a opção da Microsoft por torná-lo Open Source aumentou o ritmo de melhorias e sugestões ao framework.
Porém, o NHibernate ainda possui uma consideravel preferência por possuir uma comunidade ativa e por suportar mais escolhas de bancos de dados do que o Entity. A conversa sobre performace pode ser esquecida a partir da versão 5 do Entity Framework quando a performace se equiparou entre eles.
Além desses dois há vários outros ORMs, como por exemplo podemos citar:
Até agora conversamos sobre ORMs comuns, mas também temos a nossa disposição os chamados MicroORMs que são mais simples, muitas vezes somente um arquivo ou dll a ser acrescentado no projeto, que possuem poucas funcionalidades e somente o mapeamento básico.
É comum um MicroORM se vangloriar de ser mais rápido e performático do que um ORM completo. A justificativa está na sua simplicidade e o modo direto, sem intermediários, de acesso ao SGDB relacional.
Dois exemplos de MicroORMs seriam o Drapper e o PetaPoco. O Drapper é adicionado ao projeto com somente um arquivo e possui 3 helpers. Já o PetaPoco trabalha com vários tipos de SGDBs, com geração de código com T4 Templates e possui mais helpers do que o Drapper.
A adoção de microORMs costuma ser em projetos muito simples ou que precisam de uma performace que não foi atingida com um ORM mais complexo.
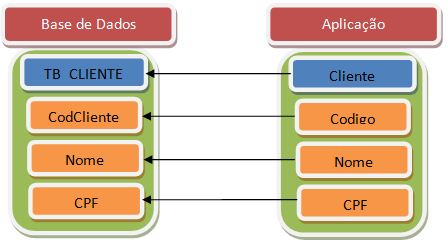
O ORM funciona através do mapeamento das características da base de dados para os objetos de nossa aplicação. O primeiro conceito chave é traçar um paralelo entre Classe x Tabela e Propriedade x Coluna. O ORM nos permite informar em que tabela cada classe será persistida e em que coluna do SGDB cada propriedade ficará armazenada, como podemos observar na Figura 2.
Na ilustração da Figura 2 nós temos uma tabela cliente na base de dados e uma classe cliente em nossa aplicação com as setas indicando o mapeamento da classe da aplicação para a tabela da base de dados. Este mapeamento considera coisas como o nome da coluna, o tipo da mesma, tamanho e precisão, dentre outras características. Um exemplo de mapeamento, em XML, pode ser visto na Listagem 1.
<?xml version="1.0" encoding="utf-8" ?>
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
namespace="DevMedia.Exemplo " assembly="DevMedia.Exemplo">
<class name="DevMedia.Exemplo.Cliente,
DevMedia.Exemplo" table="TB_CLIENTE">
<id name="Codigo" column="CodCliente"/>
<property name="Nome"/>
<property name="CPF"/>
</class>
</hibernate-mapping>Na Listagem 1 podemos observar um exemplo de mapeamento através do framework NHibernate. Veja que na linha 2 nós definimos o namespace e o assembly onde está a nossa classe e na linha 3 nós indicamos o nome da mesma seguido do nome de sua respectiva tabela no banco de dados. Na linha 4 temos uma tag Id que indica que o campo Codigo da classe é o identificador do objeto, mapeando o mesmo para a coluna CodCliente que é a chave primária da tabela. Por fim, nas linhas 5 e 6 temos o mapeamento das propriedades da classe Cliente. Vale ressaltar que nestes casos não foi informado o nome da coluna no banco de dados, pois as colunas possuem o mesmo nome das propriedades do objeto Cliente.
Com todo este mapeamento realizado, o framework passa a ter todas as informações necessárias para recuperar e persistir objetos na base de dados.
Além disso, acima foi demonstrado um exemplo de mapeamento via arquivo XML externo, através do NHibernate, porém existem outros tipos de mapeamento normalmente disponibilizados pelos frameworks ORM, sendo eles:
O mapeamento por XML, exemplificado na Listagem 1, é um dos mais comuns e está presente em muitos ORMs, como por exemplo, no próprio NHibernate. Um inconveniente deste mapeamento é a quantidade de XMLs gerados, além da manutenção um pouco mais trabalhosa, uma vez que você terá que fazê-la em arquivos XMLs, sem os recursos de refatoração e Intellisense nativos do Visual Studio.
O outro tipo de mapeamento é através de anotações, onde nós definimos no código do modelo as características da tabela ou coluna representada por cada classe e atributo. Em .NET temos os Custom Attributes que são utilizados entre colchetes, sendo aplicados às classes e propriedades, para realização do mapeamento. Um exemplo de mapeamento usando anotações pode ser visto na Listagem 2.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using NHibernate.Mapping.Attributes;
namespace DevMedia.Exemplo
{
[Class(Table = "TB_CLIENTE")]
public class Cliente
{
[Id(Column = "CodCLiente")]
public Double Codigo { get; set; }
[Property]
public Double Nome { get; set; }
[Property]
public Double CPF { get; set; }
}
}Como podemos ver no exemplo da Listagem 2, na linha 9 nós temos a definição do atributo Class com o parâmetro Table indicando o nome da tabela onde esta classe está mapeada, enquanto que na linha 12 nós temos a indicação de que a propriedade Codigo é o identificador do objeto e está mapeada para a coluna CodCliente da base de dados. Por fim temos o mapeamento das outras propriedades nas linhas 15 e 18.
O que muitos consideram como um inconveniente das anotações é que a classe que usa muitos Custom Attributes fica poluída e, caso o framework ORM fosse trocado,teríamos que alterar todas as nossas classes para que usassem os atributos do respectivo framework.
Como alternativa ao mapeamento, temos ainda normalmente o uso de uma Fluent API, que trata-se de uma API de mapeamento que implementa o pattern Fluent Interface (Nota do DevMan 2). Um exemplo deste tipo de mapeamento pode ser visto na Listagem 3.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using FluentNHibernate.Mapping;
using DevMedia.Exemplo.ExemploHeranca;
namespace DevMedia.Exemplo
{
public class ClienetMap:ClassMap<Cliente>
{
public ClienetMap() {
Id(x => x.Codigo).Column("CodCliente");
Map(x => x.Nome);
Map(x => x.CPF);
Table("TB_CLIENTE");
}
}
}Na Listagem 3 podemos observar o mapeamento com o FluentNHibernate, que é uma iniciativa da comunidade que visa permitir o mapeamento usando uma Fluent API para o NHibernate. Veja que nossa classe de mapeamento herda de uma classe base de mapeamento do FluentNHibernate, chamada ClassMap (linha 10), indicando no tipo genérico a classe que queremos mapear. Esta classe é a responsável por determinar o mapeamento de um objeto do sistema para a base de dados.Na linha 13 temos um método que nos permite indicar a propriedade identificadora do objeto e a coluna para onde a mesma está mapeada. Nas linhas 14 e 15 nós temos o mapeamento das propriedades Nome e CPF, não sendo necessária a definição da coluna da base de dados, pois esta possui o mesmo nome das propriedades do objeto. Por fim, na linha 17 temos a definição da tabela onde os dados da classe Cliente serão persistidos.
Para muitos o uso de Fluent Interface é o melhor dos dois mundos, onde podemos realizar todo o mapeamento em arquivos separados utilizando o próprio C#, com todos os recursos de refatoração e intellisense disponíveis e sem poluir nossos objetos.
Muito bem, agora que já compreendemos como as tabelas e colunas são mapeadas para classes e propriedades, como é feita a persistência destes dados através de frameworks ORM?
Cada ORM tem seu estilo de código para a persistência dos dados, mas em geral eles possuem o mesmo caminho: interpretar o comando que você solicitou, verificar qual função ou conjunto de funções SQL são necessárias para executar o comando solicitado, efetuar a leitura do mapeamento da classe que você está usando, gerar o SQL necessário, abrir uma conexão com o SGDB, executar o SQL e retornar o resultado.
A seguir temos dois exemplos bem diferentes, um em ruby com o ActiveRecord, um ORM muito popular dentro do framework Rails, e um exemplo em C# com o Entity Framework.
pessoa = Pessoa.new
pessoa.nome = "Priscila Mayumi Sato"
pessoa.saveusing (CFcontext db = new CFcontext())
{
Pessoa pessoa = new Pessoa();
pessoa.Nome = "Priscila Mayumi Sato";
db.Pessoas.Add(pessoa);
db.SaveChanges();
}Podemos notar diferentes formas de persistir os dados. Na Listagem 4 temos o exemplo com ActiveRecord: podemos ver que foi instanciado um objeto do tipo Pessoa, foi atribuido um valor para o atributo Nome e depois o próprio objeto pessoa se persistiu no banco de dados com o método save.
Na Listagem 5, em C# com Entity Framework, temos a declaração de um contexto de persistência de dados (objeto db), instanciando um objeto do tipo Pessoa, atribuindo um valor a propriedade Nome e posteriormente adicionando este objeto pessoa a um container (Pessoas) de seu tipo, e após isso o objeto foi persistido usando o método SaveChanges do contexto de persistência.
Os métodos Save e SaveChanges possuem o mesmo objetivo: persistir mudanças de objetos da memória para o banco de dados, porém foram disponibilizados de formas diferentes, uma sendo chamada diretamente no objeto mapeado e o outro solicitando que o objeto a ser persistido seja adicionado a um container.
No momento em que estes métodos foram acionados, o framework ORM verificou o mapeamento das classes para identificar qual o nome da tabela responsável e das respectivas colunas do banco de dados e gerou um SQL dinamicamente, semelhante código abaixo, e executou o mesmo no SGDB em questão.
INSERT
INTO TB_PESSOA(NOME) VALUES ("Priscila Mayumi Sato";);Os frameworks ORM nos fornecem uma série de maneiras para acessar os dados persistidos no nosso SGDB, dentre estas formas podemos destacar:
Além disso, cada framework possui características e recursos adicionais, como por exemplo, o NHibernate que possui um recurso chamado Named Queries que nos permite armazenar consultas SQL (ou também HQLs) em arquivos xml separados e depois mapeie os mesmos, como mapeou suas tabelas, podendo assim usá-las a qualquer momento no seu código.
Na Listagem 6 podemos ver um exemplo de query SQL sendo executada através do Entity Framework:
using (CFcontext db = new CFcontext())
{
string nativeSQLQuery = "SELECT count(*) FROM dbo.Edicoes"
var queryResult = db.ExecuteStoreQuery<int>(nativeSQLQuery);
int totalEdicoes = queryResult.FirstOrDefault();
}Não é uma regra mas não é incomum encontrar uma linguagem própria de consulta nos frameworks ORM (Exemplo HQL / Linq). A mecânica é que os comandos na linguagem específica passem por um interpretador da framework e depois sejam traduzidos para uma query SQL para ser executada no SGDB.
Normalmente essas linguagens de consulta são parecidas com a linguagem SQL. Exemplos de linguagens de consulta são o LINQ do .NET, o HQL do NHibernate, a DQL (Doctrine Query Language) do Doctrine (framework de ORM para linguagem PHP), e a LIQUidFORM, uma linguagem que se inspirou no LINQ só que para rodar no JPA (Java Persistence API) da plataforma Java.
A mecânica é semelhante ao passar um comando do framework para que ele interprete e crie os comandos SQL, a diferença é a flexibilidade, pois com uma linguagem própria de consultas, temos mais liberdade para trabalhar com os dados. Além disso, você não precisa se preocupar com o uso de comandos específicos de cada SGDB, pois a própria framework já trata isso.
IEnumerable<Student> studentQuery =
from student in students
where student.Scores[0] > 90
select student;Na Listagem 7 podemos observar que temos uma estrutura que vai receber o resultado da query. Podemos perceber que a query inicia de forma contrária ao SQL, com um comando from, mostrando de onde serão retirados os dados, para depois ser inserida a condição where e por fim o select. Essa estrutura é tida como mais lógica e nela é suportado o intellisense (auto-complete do visual studio).
ISession sessao = sessionFactory.OpenSession();
ICriteria criteria = sessao.CreateCriteria<Cliente>().
Add(Expression.Eq("Sexo", "Masculino"));
IList<Cliente> clientes = criteria.List<Cliente>();Na Listagem 8 temos um exemplo que demonstra uma consulta utilizando os objetos de criteria do NHibernate onde adicionamos uma nova expressão de consulta de igualdade, recuperando todos os clientes do sexo masculino. Ao executar o método criteria.List o NHibernate gera internamente todo o SQL necessário para recuperação do resultado.
Um fator muito importante ao escolher um ORM para seu projeto é estudar a performace do mesmo. Um framework ORM lida diretamente com o banco de dados e isso implica em leitura e escrita em disco, que representa um recurso caro, por isso um ORM que faz consultas e gravações de dados de forma desorganizada pode acabar sendo menos eficiente.
Outro fator que impacta na performace é o cache das consultas. Deixar algumas consultas em memória pode fazer com que você ganhe alguns milesegundos. Outro cache possível e importante é o de resultados das consultas que são feitas com maior frequência.
Uma discussão recorrente é se a adoção de ORMs não diminui a performace do sistema que o adota. Realmente a performace pode cair, pois você está adicionando camadas adicionais e mais processamento no caminho entre a lógica da aplicação e os dados. Mas se o ORM for bom, seu modelo for coeso e estiver bem mapeado, a pequena queda de performace provavelmente não será percebida pelos usuários finais, sendo notada somente em testes específicos, visto que a diferença estará na casa de milésimos de segundos.
Mesmo que você perca alguns milésimos de segundos, a adoção vale a pena por aumentar consideravelmente a produtividade da equipe.
O que vale ressaltar é que se você está trabalhando com um grande volume de dados, por exemplo um relatório que retorna dezenas de milhares de registros ou uma importação de um grande volume de registros, pode ser melhor executar isso com SQL nativo do que com um framework ORM, visto que se formos criar dezenas de milhares de objetos em memória para isso, a diferença de performance poderá sair da casa de milésimos de segundos e passará para a casa de segundos (ou até minutos, dependendo do volume de dados), sendo percebida pelo usuário final. Além disso, aplicações críticas onde estes milésimos de segundos fazem diferença para o domínio em questão não devem usar ORM, buscando sempre o acesso mais direto possível à informação.
Diante dos principais prós (produtividade e manutenção) e contras (performance), o que vale é sempre o bom senso para avaliar cada caso, sempre buscando o melhor equilíbrio, avaliando o que é mais importante e o que traz mais impacto para o projeto em questão.
Como vimos neste artigo o uso de frameworks de ORM auxiliam no desenvolvimento de aplicações tornando mais fácil o manejo de dados bases de dados relacionais. Apesar de trazer facilidades nem sempre poderemos utilizar somente ORM, por isso é necessário aprender também a sintaxe SQL. Um relatório complexo é um exemplo em que normalmente a melhor forma de se fazer é com SQL nativo.
Como muitos frameworks ORM trazem alguns recursos específicos, também é bom estudar e se aprofundar no framework que você for usar para que se possa tirar o melhor proveito do mesmo. Nem sempre você usará o mesmo framework que está acostumado, por isso preste atenção nos frameworks que forem surgindo no mercado e na comunidade.
Vale ressaltar ainda que o foco deste artigo foi apresentar o conceito ORM e algumas das características chaves, sem entrar em muitos detalhes de implementação, servindo como base para as próximas edições onde falaremos mais sobre o Entity Framework e o NHibernate, apresentando exemplos práticos completos sobre os mesmos.

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programação antes de começar a estudar com vocês, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda não tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocês e logo percebi que são os melhores do Brasil. É um passo a passo incrível. Só não aprende quem não quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocês estão fazendo parte da minha jornada nesse mundo da programação, irei assinar meu contrato como programador graças a plataforma.

Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que não tem como não aprender, estão de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tão presente na vida acadêmica de seus alunos, parabéns!

Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!

Adauto Junior
Já fiz alguns cursos na área e nenhum é tão bom quanto o de vocês. Estou aprendendo muito, muito obrigado por existirem. Estão de parabéns... Espero um dia conseguir um emprego na área.
Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.